Tiny-LSM Lab
![]()
0 Tiny-LSM是什么?
Tiny-LSM是一个基于LSM Tree的开源教学KV存储引擎, 除LSM Tree的基础功能外, 还支持MVCC、WAL、崩溃恢复、Redis兼容等功能。本实验是基于作者原本实验的代码进行改造后的Lab课程。
LSM Tree(Log-Structured Merge-Tree)是一种适用于磁盘存储的数据结构,特别适合于需要高吞吐量的写操作的场景。它由Patrick O’Neil等人于1996年提出,广泛应用于NoSQL数据库和文件系统中,如LevelDB、RocksDB和Cassandra等。LSM Tree的主要思想是将数据写入操作日志(Log),然后定期将日志中的数据合并到磁盘上的有序不可变文件(SSTable)中。这些SSTable文件按层次结构组织,数据在多个层次之间逐步合并和压缩,以减少读取时的查找次数和磁盘I/O操作。
有关LSM Tree的进一步背景和介绍请参见LSM Tree 概览
本实现项目Tiny-LSM完成了包括内存表(MemTable)、不可变表(SSTable)、布隆过滤器(Bloom Filter)、合并和压缩(Compaction)等LSM Tree的核心组件,并在此基础上添加了额外的功能博客, 包括:
- 实现了
ACID事务 - 实现了
MVCC多版本并发控制 - 实现了
WAL日志和崩溃恢复 - 基于
KV存储实现了Redis的Resp协议兼容层 - 基于
Resp协议兼容层实现了redis-server服务
⭐ 请支持我们的项目!
如果您觉得本
Lab不错, 请为Tiny-LSM点一个⭐。项目实验制作耗费了我很大精力,作者非常需要您的鼓励❤️, 您的支持是我更新的动力😆
1 本实验的目的是什么?
本实验的最终目标是实现一个基于LSM Tree的单机KV Store引擎。其功能包括:
- 基本的
KV存储功能,包括put、get、remove等。 - 持久化功能,构建的存储引擎的数据将持久化到磁盘中。
- 事务功能,构建的存储引擎将支持
ACID等基本事务特性 MVCC, 构建的存储引擎将支持MVCC对数据进行查询。WAL与崩溃恢复, 数据写入前会先预写到WAL日志以支持崩溃恢复Redis兼容, 本实验将实现Redis的Resp兼容层, 作为Redis后端。
2 本实验适合哪些人?
通过本实验,你可以学习到LSM Tree这一工业界广泛使用的KV存储架构, 适合数据库、存储领域的入门学习者。同时本实验包含了Redis的Resp协议兼容层、网络服务器搭建等内容,也适合后端开发的求职者。同时,本项目使用C++ 17特性, 使用Xmake作为构建工具,并具备完善的单元测试,也适合想通过项目进一步学习现代C++的同学。
3 本实验的前置知识?
本项目的知识包括:
- (必备): 到
C++17为止的常见C++新特性,(项目的配置文件指定的标准为C++20, 但其只在单元测试中使用, 项目核心代码只要求C++17即可) - (必备):常见的数据结构与算法知识
- (建议): 数据库的基本知识,包括事务特性、
MVCC的基本概念 - (建议):
Linux系统编程知识,本实验使用了系统底层的mmap等IO相关的系统调用 - (可选):
Xmake的使用, 本实验的构建工具为Xmake, 若你想自定义单元测试或引入别的库, 需要手动在Xmake中配置。 - (可选):
Redis基本知识, 本实验将利用kv存储接口实现Redis后端, 熟悉Redis有助于实验的理解。 - (可选): 单元测试框架
gtest的使用, 如果你想自定义单元测试, 需要自行改配置。
4 实验流程
本实验的组织类似CMU15445 bustub, Lab提供了整体的代码框架, 并将其中某些组件的关键函数挖空并标记为TODO, 参与Lab的同学需要按照每一个Lab的指南补全缺失的函数, 并通过对应的单元测试。
同样类似CMU 15445, 后面的Lab依赖于前一个Lab的正确性, 而实验提供的单元测试知识尽量考虑到了各种边界情况, 但不能完全确保你的代码正确, 因此必要时, 你需要自行进行单元测试补充以及debug。
本实验代码位于仓库 Tiny-LSM 的
lab2分支(lab分支为旧版本),对应的文档位于lab-doc-2分支(lab-doc分支为旧版本)。你确实可以从原仓库的complete分支直接查看Lab实验的答案, 但作者不希望你如此做, 这样你将无法深刻理解实验设计的思路和相关知识。并且, 作者自己实现的代码中的崩溃恢复部分存在bug, 且其余部分并非最佳方案。(猜猜作者是不是故意的😏)
在了解完这些以后, 你可以开启下一章Lab 0 环境准备的学习。
5 项目交流与讨论
如果你对本Lab有疑问, 欢迎在GitHub Issues中提出问题。也欢迎加入次实验的QQ讨论群 。如果你想参与Lab的开发, 欢迎通过QQ群或者作者邮件: 📧邮件 联系。
6 推荐课程
这里给出作者推荐的相关开源课程, 供你参考学习:
- mini-lsm 迟先生用
Rust实现的LSM Tree课程, 其代码质量非常高, 本课程的很多设计也参考了Mini-LSM, 适合想用Rust实现LSM Tree的同学学习。 - TinyCoroLab, 基于
io_uring的现代C++协程的开源课程, 适合学习协程及的各种现代C++新特性。 - CMU 15445 经典CMU的数据库课程, 不解释了。
- MIT 6.824 MIT的经典分布式课程。
- Tiny-KV PingCap出品的分布式KV数据库教程, 算是MIT 6.824的升级版。
7 贡献者
非常感谢本项目贡献过源码的网友:
如果你在阅读本教程文档中发现错误, 可以直接点击文档右上角的 , 其会引导你进入对应分支对当前的
, 其会引导你进入对应分支对当前的md文件进行编辑和修改, 然后提交PR即可。
1. LSM Tree 简介
在具体进入本实验之前,我们先来简单介绍LSM Tree。
LSM Tree是一种KV存储架构。其核心思想是,将KV存储的数据以SSTable的形式进行持久化,并通过MemTable进行内存缓存,当MemTable的数据量达到一定阈值时,将其持久化到磁盘中,并重新创建一个MemTable。并且,数据以追加写入的方式进行,删除数据也是通过更新的数据进行覆盖的方式实现。
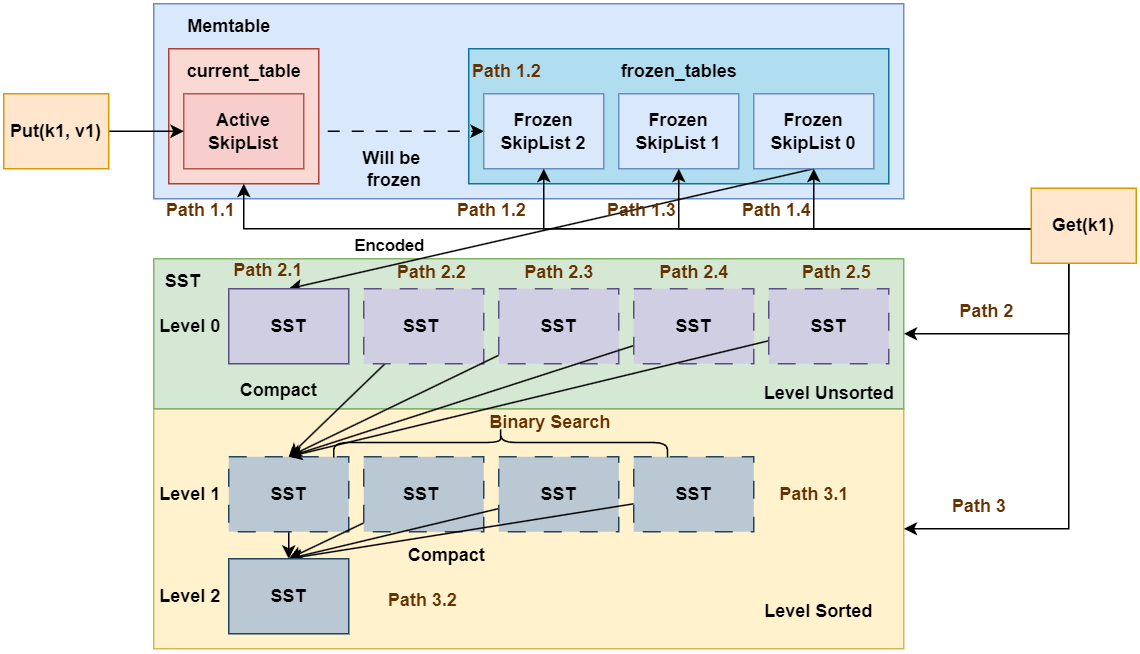
如图所示为LSM Tree的核心架构。我们通过Put, Remove和Get操作的流程对其进行介绍。
1.1 Put 操作流程
Put操作流程如下:
- 将
Put操作的数据写入MemTable中MemTable中包括多个键值存储容器(本项目是采用的跳表SkipList)- 其中有一份称为
current_table, 即活跃跳表, 其可读可写 - 其余的多份跳表均为
frozen_tables, 即即冻结跳表, 其只能进行读操作
- 其中有一份称为
Put的键值对首先插入到current_table中- 如果
current_table的数据量未达到阈值, 直接返回给客户端 - 如果
current_table的数据量达到阈值, 则将current_table被冻结称为frozen_tables中的一份, 并重新初始化一份current_table
- 如果
- 如果前述步骤导致了新的
frozen_table产生, 判断frozen_table的容量是否超出阈值 - 如果超出阈值, 则将
frozen_table持久化到磁盘中, 形成SST(全程是Sorted String Table), 单个SST是有序的。SST按照不同的层级进行划分, 内存中的MemTable刷出的SST位于Level 0,Level 0的SST是存在重叠的。(例如SST 0的key范围是[0, 100),SST 1的key范围是[50, 150), 那么SST 0和SST 1的key在50, 100)范围是重叠的, 因此无法在整个层级进行二分查询)- 当
Level 0的SST数量达到一定阈值时, 会进行Level 0的SST合并, 将SST进行compact操作, 新的SST将放在Level 1中。同时,为保证此层所有SST的key有序且不重叠,compact的SST需要与原来Level 1的SST进行重新排序。由于compact时将上一层所有的SST合并到了下一层, 因此每层单个SST的容量是呈指数增长的。 - 当每一层的
SST数量达到一定阈值时,compact操作会递归地向下一层进行。
1.2 Remove 操作流程
由于LSM Tree的操作是追加写入的, 因此Remove操作与Put操作本质上没有区别, 只是Remove的value被设定为空以标识数据的删除。
1.3 Get 操作流程
Get操作流程如下:
- 先在
Memtable中查找, 如果找到则直接返回。- 优先查找活跃跳表
current_table - 其次尝试查找
frozen_tables, 按照id倒序查找(因为id越小, 表示SkipList越旧)
- 优先查找活跃跳表
- 如果在
Memtable中未找到, 则在SST中查找。- 先在
Level 0层查找, 如果找到则直接返回。注意的是,Level 0层不同的SST没有进行排序, 因此需要按照SST的id倒序逐个查找(因为id越小, 表示SST越旧, 优先级越低) - 随后逐个在后面的
Level层查找, 此时所有的SST都已经进行过排序, 因此可在Level层面进行二分查询。
- 先在
- 如果
SST中为查询到, 返回。
至此,你对LSM Tree的CRUD操作流程有了一个初步的印象, 如果你现在看不懂的话, 没关系。后续的Lab中会对每个模块有详细的讲解。
2. LSM Tree VS B-Tree
接下来对比分析一下LSM Tree 和 B-Tree。B-Tree 和 LSM-Tree 是两种最常用的存储数据结构,广泛应用于各种数据库和存储引擎中。
2.1 B-Tree 概述
2.1.1 基本结构
B-Tree 是一种多路平衡搜索树,具有如下特点:
- 多路搜索:每个节点可包含多个 key 和多个指向子节点的指针,典型的阶为 M 的 B-Tree 每个节点最多包含 M-1 个 key 和 M 个子指针。
- 有序性:节点内的 key 是有序排列的,满足搜索树的性质(左子树所有 key 小于当前 key,右子树所有 key 大于当前 key)。
- 节点平衡:B-Tree 总是保持所有叶子节点在同一深度,避免了不平衡树造成的性能劣化。
- 磁盘优化:B-Tree 节点设计与磁盘页大小(如 4KB)对齐,尽量减少 I/O 次数。一个节点一般映射为一个磁盘页。
2.1.2 操作流程
查找操作
- 从根节点开始,顺序查找当前节点内的 key;
- 若找到对应 key,返回其值;
- 若未找到,确定 key 所属范围并跳转到对应子节点;
- 重复上述步骤,直到叶子节点。
插入操作
- 先定位插入位置;
- 若目标页未满,直接插入;
- 若目标页已满,触发分裂操作,将节点拆分为两个,并将中间 key 上移至父节点;
- 如果父节点也满,则递归向上分裂,可能导致树高度加一。
删除操作(简略)
- 查找要删除的 key;
- 若为叶子节点直接删除,若为内部节点需用前驱/后继替换;
- 若删除导致节点 key 数小于最小值(通常是 M/2),需借 key 或合并兄弟节点,保持平衡。
2.1.3 性能特点
| 操作类型 | 时间复杂度 | 备注 |
|---|---|---|
| 查找 | O(logₘN) | 树高取决于扇出 M,M 越大树越矮 |
| 插入 | O(logₘN) | 最多向上分裂至根节点 |
| 删除 | O(logₘN) | 包含调整和合并操作 |
- 优势:查找路径短,适用于 OLTP 事务型数据库;
- 劣势:写入为页内更新和随机写, 且可能导致写放大,不适合写密集型负载。
🌪️ “随机写”是什么意思?
在 B-Tree 中,每次写入(插入、更新或删除)都必须找到对应位置,比如一个叶子节点中的第 n 个 key:
- B-Tree 会从根节点一路查找,定位到目标页(也就是磁盘上的一个节点)。
- 如果该页满了,还要分裂成两个页,再更新父节点指针,可能一直递归到根。
- 每一个操作,可能都要读写不同位置的磁盘页——这些页不在相邻磁盘位置上,就叫“随机写”。
而磁盘(特别是传统 HDD)最慢的操作就是随机写。
🔥 “写放大”又是什么?
你本来只是想写入一个 key-value 对,结果 B-Tree 却可能会因为:
- 页满而分裂;
- 父节点也满而再分裂;
- 更新多个索引路径节点;
导致你实际上要写入多个节点、多个页——一次小写入导致多次磁盘写入,这就叫写放大(Write Amplification)。
比如你写了 1KB 数据,磁盘实际写了 16KB,甚至 64KB,这种浪费,就是放大了。
2.2. LSM-Tree 概述
2.2.1 设计动机
为了解决传统 B-Tree 在写密集场景下的随机写和高写放大问题,LSM-Tree 采取“先内存写、再后台合并”的思路,以空间换时间,提升写入吞吐。
2.2.2 主要组件与流程
- MemTable(内存表):所有写操作首先追加到内存中的有序结构(如跳表)。
- SSTable(磁盘表):当 MemTable 达到阈值时,将其定期刷新为只读的磁盘文件。
- 后台 Compaction(合并):将多个旧的 SSTable 合并、去重,并生成新的 SSTable,控制文件数量与数据冗余。
2.2.3 优化手段
- Bloom Filter:快速判断某 key 是否存在于某个 SSTable,减少不必要的磁盘查找。
- Index Block / Block Cache:缓存热点数据页,加速读请求。
- Tiered / Leveled Compaction:通过分层或分阶段合并,平衡写放大与读放大。
2.3. B-Tree vs. LSM-Tree 对比
| 特性 | B-Tree | LSM-Tree |
|---|---|---|
| 写入模式 | 随机写,页内更新,可能分裂节点 | 顺序写(追加),后台合并 |
| 写放大 | 较低 | 较高(受合并策略影响) |
| 读取路径 | 单次树搜索 | 多级查找(MemTable + 多个 SSTable + 合并) |
| 读写性能场景 | 读密集型 | 写密集型 |
| 磁盘友好性 | 随机 I/O | 顺序 I/O,更适合 SSD |
小结:LSM-Tree 在写入吞吐上优于 B-Tree,但读取延迟与 I/O 成本相对更高。 更深入的对比分析可以阅读: https://tikv.org/deep-dive/key-value-engine/b-tree-vs-lsm/
2.4 常见系统及应用场景
| 存储引擎 / 数据库 | 类型 |
|---|---|
| LevelDB | 嵌入式 KV 存储引擎 |
| RocksDB | KV 存储引擎 |
| HyperLevelDB | 分布式 KV 存储 |
| PebbleDB | 嵌入式 KV 存储 |
| Cassandra | 分布式列存储数据库 |
| ClickHouse | 分析型数据库 |
| InfluxDB | 时间序列数据库 |
2.5 LSM-Tree 优化研究
LSM Tree自1997年提出后,有很多研究人员在LSM Tree的基础上进行了改进,部分代表性工作比如:
RocksDB, LevelDB:经典的LSM Based KV存储引擎.
WiscKey: Separating Keys from Values in SSD-Conscious Storage:分离 Key 和 Value,降低写放大
Monkey: Optimal Bloom Filters and Tuning for LSM-Trees:优化布隆过滤器分配策略,减少读放大
这里不再进行详细介绍,感兴趣的可以阅读相关论文。
Lab 0 环境准备
1 OS和编译器环境
本实验目前最高使用的C++标准是C++20, 所以需要使用g++或者clang++进行编译, 因此只要是支持C++20的编译器都可以. 我这里使用的操作系统是kali linux, 其和Ubuntu一样, 都是基于Debian, 且都使用apt作为系统包管理工具, 所以你使用Ubuntu或者Debian执行我之后的安装指令肯定也没有什么问题。
我使用
WSL2的kali linux作为开发环境,WSL2相关内容可以参考WSL入门到入土 经个人验证,WSL2的kali-linux和Ubuntu 22.04均能正常完成本实验
1.1 编译器安装
sudo apt install -y gcc
sudo apt install -y g++
经测试, 只要支持C++20的编译器均可以正常构建本项目, 我测试通过的编译器版本包括:
g++-11/12/13/14/15clang++-16/17/18/19
1.2 语言服务器
本实验推荐使用clangd作为语言服务器, clangd是一个C/C++语言服务器, 其可以提供代码补全、代码跳转、代码高亮等功能。
# Ubuntu/Debian/Kali
sudo apt update
sudo apt install -y clangd
# Arch Linux / Manjaro
sudo pacman -S clang # 安装的是最新版本的 clang 包,clangd 自动包含在其中。
# Fedora / CentOS / RHEL
sudo dnf install clang-tools-extra # langd 在 clang-tools-extra 包中
# openSUSE
sudo zypper install clang-tools
2 项目管理工具
2.1 Xmake
2.1.1 安装
本实验使用Xmake作为项目管理工具, Xmake是一个C/C++项目管理工具, 其可以看做Make+CMake+vcpkg的集合, 包括构建、依赖管理和项目运行等功能。
安装Xmake
curl -fsSL https://xmake.io/shget.text | bash
Xmake官网参考: https://xmake.io/#/getting_started
2.1.2 Xmake语法简介
Xmake使用Lua作为脚本语言,其语法简单易学,支持C/C++的依赖管理、构建、运行等功能。以下是一些基本的内置函数:
- 项目配置:通过
add_rules添加规则,如添加 C++11 支持。 - 目标定义:使用
target定义构建目标,包括可执行文件或库。 - 源文件指定:通过
set_sources指定源代码文件。 - 依赖管理:定义项目时使用
add_requires添加依赖, 定义目标时用add_deps声明本地依赖的目标, 使用add_packages添加第三方包依赖。 - 宏定义与包含路径:分别通过
add_defines和add_includedirs设置。
这里说起来比较抽象, 直接看一个示例:
-- 定义项目
set_project("tiny-lsm")
set_version("0.0.1")
set_languages("c++20")
add_rules("mode.debug", "mode.release")
add_requires("gtest") -- 添加gtest依赖
add_requires("muduo") -- 添加Muduo库
target("utils")
set_kind("static") -- 生成静态库
add_files("src/utils/*.cpp") -- 指定源代码文件
add_includedirs("include", {public = true})
target("example")
set_kind("binary") -- 生成可执行文件
add_files("example/main.cpp") -- 指定源代码文件
add_deps("utils") -- 声明依赖目标
add_includedirs("include", {public = true})
set_targetdir("$(buildir)/bin")
add_packages("gtest") -- 添加gtest包
常用的
以上是 Xmake 的基本语法概览,更多细节可以参考官方文档: https://xmake.io/#/getting_started
2.2 (可选)vcpkg安装
正常情况下, Xmake已经足够本项目的构建需求。但是可能存在系统依赖不兼容导致Xmake无法从xrepo拉取依赖的情况, 此时建议使用vcpkg进行第三方的依赖管理。
vcpkg是一个跨平台依赖管理工具, 其可以自动下载、编译和安装C/C++依赖库。虽然Xmake自带一个依赖管理库, 但上面的库还是比较少, 作为补充, 我们可以再安装vcpkg, 这使得我们可以使用vcpkg来安装更多Xmake没有的依赖库。
vcpkg这里不过多介绍, 可以直接看我另一篇文章: https://zhuanlan.zhihu.com/p/849150169
3 VSCode配置
3.1 代码智能提示和跳转
这里使用clangd作为语言服务器, 我们之前已经安装了clangd, 现在只需要在VSCode中安装clangd插件即可:
3.2 集成Xmake
VScode中支持Xmake项目管理工具, 我们可以安装Xmake插件, 使得在VSCode中可以更方便的使用Xmake项目管理工具:
这里有一点需要说明, 如果你安装了Xmake插件, 但是在调试时卡死不懂, 建议禁用Code Runner和C/C++ Runner两个插件, 如果还行不将CMake插件也一起禁用了:
如果你的Xmake在调试时进入的是gdb的页面, 请在设置中将Debug Config Type设置为lldb:
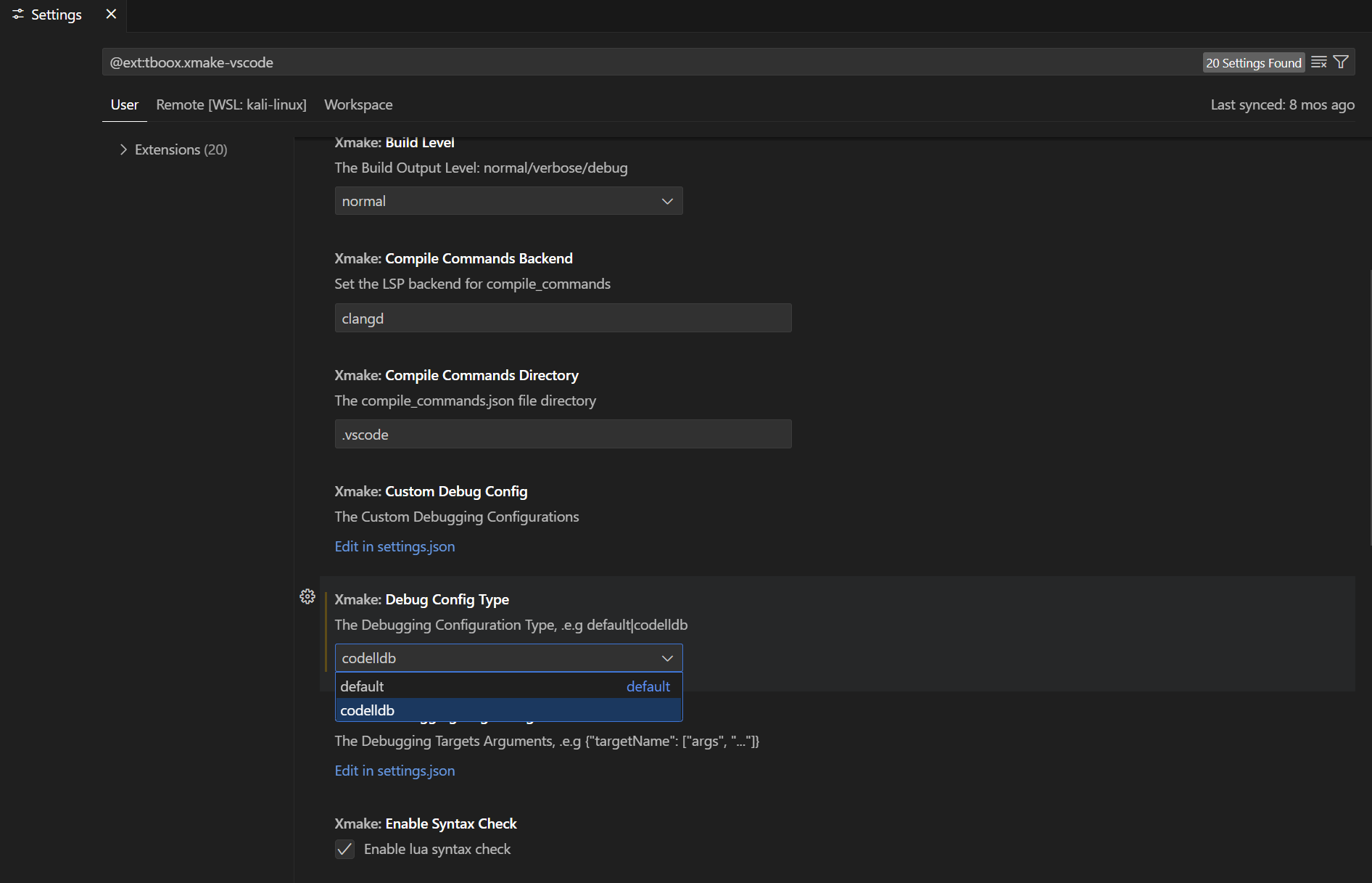
当然你需要先安装CodeLLdb插件:
3.3 代码高亮
如果你经常用C++开发, 那么你可能经常会遇到第三方包导致代码高亮跳转失效的问题:
这是因为语言服务器找不到第三方包的头文件, 由于我们使用的语言服务器是clangd, 我们可以在项目根目录中添加.clangd配置文件, 可以用下面两种方式解决:
3.3.1 配置.clangd文件
CompileFlags: # 编译标志部分
Add:
- "-std=c++20" # 添加 C++17 支持
- "-isystem/home/vanilla-beauty/proj/vcpkg/installed/x64-linux/include" # 包含头文件, 绝对路径
- "-isystem/home/vanilla-beauty/.xmake/packages/m/muduo/2022.11.01/e9382a25649e4e43bf04f01f925d9c2f/include" # 包含头文件, 绝对路径
这样一来之前的告警就不复存在了
关于.clangd文件的更多用法, 可以参考:
3.3.2 生成compile_commands.json文件(推荐⭐⭐⭐)
这里首先简单介绍下compile_commands.json文件是什么, compile_commands.json 文件是一个标准的 JSON 文件,它包含了项目中每个源文件编译时所使用的命令。这个文件通常被 IDE 和 代码分析工具 用来获取项目的编译信息,从而实现以下功能:
- 代码补全和智能提示:通过解析编译命令中的头文件路径和宏定义,工具可以提供更准确的代码补全。
- 代码导航:工具能够快速跳转到头文件和函数定义。
- 静态分析:分析工具可以利用完整的编译命令来更精确地检查代码中的潜在问题。
在本项目中, 你可以通过下面的命令生成compile_commands.json文件:
xmake project -k compile_commands
生成的compile_commands.json文件会放在项目根目录下, 此后重新用VSCode或者Vim打开项目, 你就可以看到高亮和跳转了(前提是C++的语言服务器是clangd)
3.4 其他实用插件
3.4.1 Better Comments && TodoTree
Better Comments是一个VSCode插件, 它可以提供代码注释高亮和语法高亮功能, 使得代码更加易读。比如像TODO, !这样的符号:
当我们实现一个功能但其后续需要更新时, 我们可以在代码中添加TODO注释, 以便后续更新时更醒目。
TodoTree则会在侧边栏展开我们标记了TODO的注释的位置
3.4.2 AI插件
如果你有钱, 直接用Cusor, Windsurf, 他们的体验更好
如果和我一样不够钱, 那么你可以使用通义灵码, Cline或者GitHub Copilot:
4 Lab代码仓库说明
按照下面的命令拉取实验代码仓库:
git clone https://github.com/Vanilla-Beauty/tiny-lsm.git --depth 1 -b lab2
如果你之前的环境配置没有问题的话, 编译项目能够正常进行:
cd tiny-lsm
mkdir build
xmake
项目目录结构
tiny-lsm/
├── doc/ # 项目文档
├── example/ # 示例程序
├── include/ # 公共头文件
├── sdk/ # SDK 接口
├── server/ # 服务器端实现
├── src/ # 核心源代码
├── test/ # 测试代码
├── .clangd # Clangd 配置文件
├── .gitignore # Git 忽略文件配置
├── Readme.md # 项目说明文档
└── xmake.lua # xmake 构建配置文件
其中src目录下包含以下子目录:
src/
├── block/ # 数据块的编码与解码
├── iterator/ # 统一的迭代器接口
├── lsm/ # LSM 引擎的核心逻辑
├── memtable/ # 内存表(MemTable)管理
├── redis_wrapper/ # Redis 协议兼容层
├── skiplist/ # 跳表实现
├── sst/ # SSTable 的读写与管理
├── utils/ # 工具函数与通用组件
├── wal/ # Write Ahead Log管理
```
Lab 1 跳表实现
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
1 跳表在 LSM Tree 中的作用
本Lab中, 你将实现内存的基础数据结构作为MemTable的容器, 这里使用基于红黑树的std::map也是可行的, 但LSM Tree的原始论文中使用的是跳表, 因此我们选择使用跳表作为MemTable的容器,并且正好实现以下这个数据结构 (造轮子是C++的快乐)。
我们再次回顾下面的这张架构图:
这里的MemTable用于存储内存中的键值对数据, 其存储的基础容器即为Skiplist。SkipList被划分为2组: current_table和frozen_table。current_table可读可写, 并是唯一写入的SkipList, frozen_table是只读状态, 用于存储已经写入的键值对数据。current_table容量超出阈值即转化为frozen_table中的一个。
2 跳表的原理
这里简单介绍一下跳表是什么, 跳表就是个链表, 每个链表的步长不同, 且链表节点是排序的, 查找或插入时, 先使用最大步长层级的链表, 然后定位大区间后, 转入下层低步长层级的链表继续查询, 是不是非常简单? :smile:
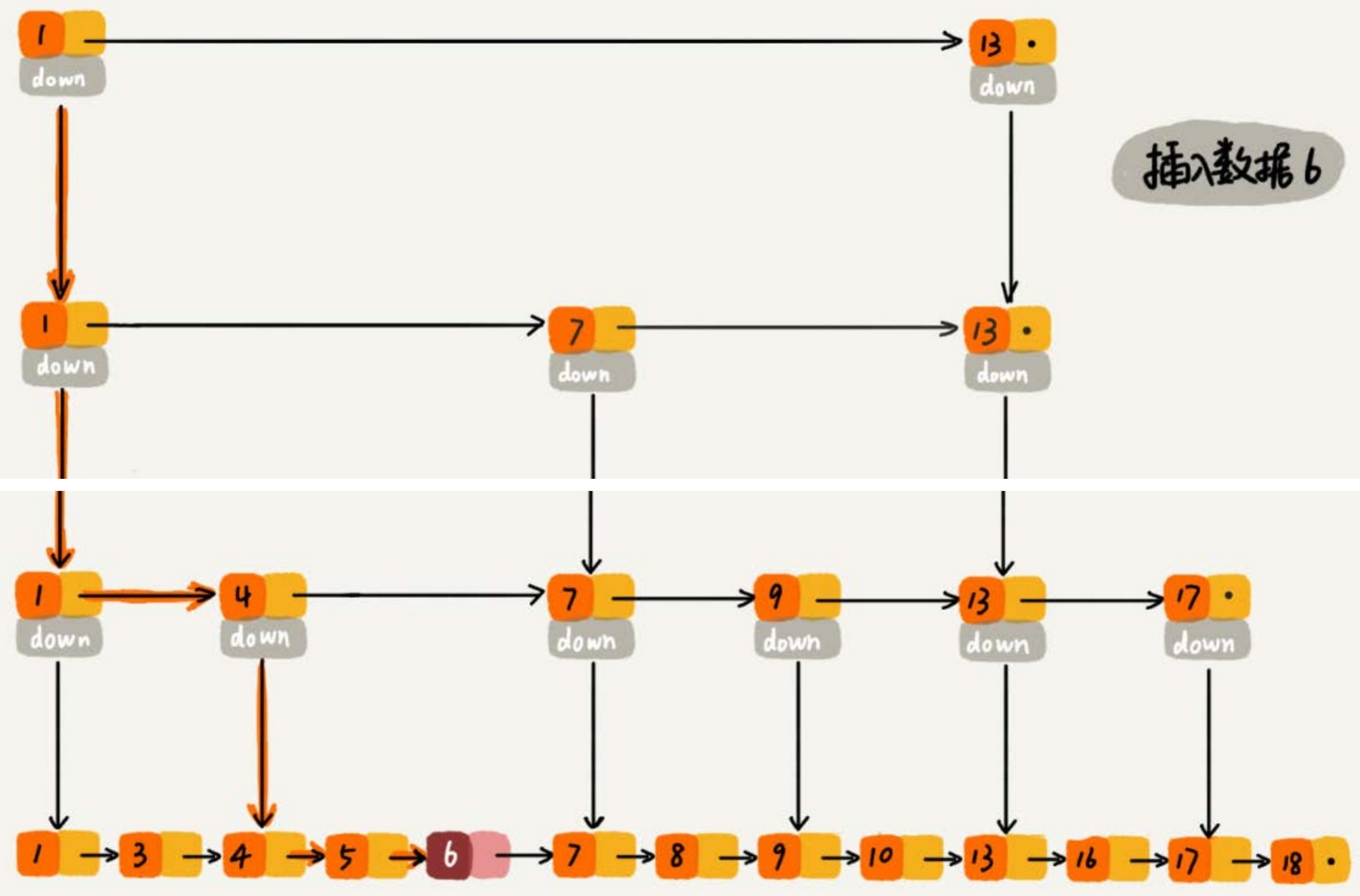
上图所示为跳表的简单示意图, 可以看出跳表由多层链表组成,每一层都是一个有序链表。最底层的链表包含所有元素,而上层的链表只包含部分元素,这些元素作为“索引”加速查找过程。
2.1 查找过程
假设我们要查找值为6的节点:
- 从最高层开始:从最高层的头节点开始,沿着水平指针向右移动,直到遇到大于目标值的节点或到达该层的末尾。
- 向下移动:如果当前层没有找到目标值,则沿着垂直指针向下移动到下一层,重复上述步骤。
- 继续查找:在每一层中重复这个过程,直到在最底层找到目标值或确定目标值不存在。
2.2 插入过程
假设我们要插入值为6的节点:
- 查找插入位置:首先按照查找过程找到值为6应该插入的位置。在这个例子中,值为6应该插入在4和7之间。
- 创建新节点:在最底层创建一个新节点,值为6,并将其插入到正确的位置。
- 随机决定层数:使用随机算法决定新节点的层数。例如,可以以50%的概率决定是否将新节点添加到上一层。
- 更新指针:在每一层中更新指针,确保新节点被正确地链接到链表中。
2.3 删除过程
假设我们要删除值为6的节点:
- 查找要删除的节点:首先按照查找过程找到值为6的节点。
- 逐层删除:从最底层开始,逐层删除该节点,并更新相应的指针。
- 调整层数:如果某一层只剩下头节点和尾节点,则可以考虑删除这一层以优化空间。
3 还欠缺什么?
在你了解到了上述LSM的基础知识后, 你可能觉得SkipList的实现不过如此, 很简单吧。但实际上也没有那么简单,首先你需要思考下面几个问题:
- 不同
Level的链表的步长如何确定?- 最底层
Level 0的链表步长肯定是1, 那么Level 1呢,Level 2呢?
- 最底层
- 什么时候我们需要创建新的
Level的?- 一开始的时候,
SkipList的Level是多少? - 新创建的
Level是逐层创建的吗? 还是说一次性提升好几层?
- 一开始的时候,
- 上面演示的
SkipList仅仅是单向链表, 如果是双向链表, 有什么区别呢?
带着疑问, 你可以开启本章跳表 CRUD 的实现的Lab实验了
Lab 1.1 跳表的 CRUD
1 准备工作
本Lab中, 你需要修改的代码文件为
src/skiplist/skipList.cppinclude/skiplist/skiplist.h(optional)
这里首先简单介绍本Lab已有的SkipList头文件定义:
// include/skiplist/skiplist.h
struct SkipListNode {
std::string key_; // 节点存储的键
std::string value_; // 节点存储的值
uint64_t tranc_id_; // 事务 id, 目前可以忽略
std::vector<std::shared_ptr<SkipListNode>>
forward_; // 指向不同层级的下一个节点的指针数组
std::vector<std::weak_ptr<SkipListNode>>
backward_; // 指向不同层级的下一个节点的指针数组
// ...
};
这里定义了跳表节点的基础数据, 包括key, value和目前可以忽略的事务tranc_id_
这里定义的跳表节点使用的是双向链表, forward_和backward_分别存储了各层链表节点的前向指针和后向指针, 其中为了避免循环引用, 这里结合使用了weak_ptr和shared_ptr, 详细熟悉现代C++的同学对此非常熟悉。
这里补充说明一下
weak_ptr, 它的作用是避免shared_ptr循环引用, 即一个节点的shared_ptr指针指向另一个节点, 另一个节点的shared_ptr指针指向前者, 这样就会造成两个节点的析构都无法进行, 因为在析构时互相持有对方的引用计数, 类似死锁。但weak_ptr不参与类似shared_ptr的引用计数, 保证了析构的正确进行。但也正因为如此,weak_ptr不保证指针的有效性, 需要使用.lock()判断该指针是否有效。
然后我们看SkipList的头文件定义:
class SkipList {
private:
std::shared_ptr<SkipListNode>
head; // 跳表的头节点,不存储实际数据,用于遍历跳表
int max_level; // 跳表的最大层级数,限制跳表的高度
int current_level; // 跳表当前的实际层级数,动态变化
size_t size_bytes = 0; // 跳表当前占用的内存大小(字节数),用于跟踪内存使用
// std::shared_mutex rw_mutex; // ! 目前看起来这个锁是冗余的, 在上层控制即可,
// 后续考虑是否需要细粒度的锁
std::uniform_int_distribution<> dis_01; // 随机层数的辅助生成器
std::uniform_int_distribution<> dis_level;
std::mt19937 gen;
};
这里我们定义了最大的链表层数max_level, 你的实现不能有超过max_level的链表数量, current_level定义当前链表的层数(注意是层数, 不是索引), 最后介绍最重要的head, 其只是个哨兵节点, 并不实际存储键值对。
后面三行的gen和dis_01和dis_level是随机数生成器,你可以使用它们来生成随机数。回想我们之前提到的问题, 你应该如何确定每一次插入节点时最高的连接链表的Level呢? 这里你可以利用这些随机生成器来确定这些层数, 当然你也可以选择自己的方式来实现。
2 put 的实现
你需要实现下面的put函数:
// 插入或更新键值对
void SkipList::put(const std::string &key, const std::string &value,
uint64_t tranc_id) {
spdlog::trace("SkipList--put({}, {}, {})", key, value, tranc_id);
// TODO: Lab1.1 任务:实现插入或更新键值对
// ? Hint: 你需要保证不同`Level`的步长从底层到高层逐渐增加
// ? 你可能需要使用到`random_level`函数以确定层数, 其注释中为你通公路一种思路
}
目前, 你可以先忽略tranc_id这个参数。
此外,之前提到过,跳表的层数是动态增加的, 因此你实现下面的函数可能对你有帮助:
int SkipList::random_level() {
// TODO: 实现随机生成level函数
// 通过"抛硬币"的方式随机生成层数:
// - 每次有50%的概率增加一层
// - 确保层数分布为:第1层100%,第2层50%,第3层25%,以此类推
// - 层数范围限制在[1, max_level]之间,避免浪费内存
return -1;
}
这里给出一个提示, 生成的整型值的每一个二级制位只包含0或1, 可以表示为bool类型, 因此你可以利用它来判断这个节点的最高层数:
Level 0底层链表: 一定连接新节点Level 1链表: 判断random_level()生成整型数的第1位是否为1, 有50%的概率连接新节点, 为0则跳出该判断链Level 2链表: 判断random_level()生成整型数的第2位是否为1, 有50% * 50% =25%的概率连接新节点, 为0则跳出该判断链- …
当然, 上述只是一个建议的方案, 你可以选择别的实现方案, 并删除
random_level函数 另外, 别忘记了更新size_bytes这个统计信息, 如果你不知道这个统计信息的运作规则, 你可以查看单元测试SkipListTest.MemorySizeTracking
3 remove 的实现
虽然我们的LSM Tree是以仅追加写入的方式使用我们的SkipList, 但为了这个数据结构的完整性, 也是一次手搓底层跳表的体验, 你需要实现正儿八经的remove函数:
// 删除键值对
// ! 这里的 remove 是跳表本身真实的 remove, lsm 应该使用 put 空值表示删除,
// ! 这里只是为了实现完整的 SkipList 不会真正被上层调用
void SkipList::remove(const std::string &key) {
// TODO: Lab1.1 任务:实现删除键值对
}
remove函数的实现的第一步是查询到指定的节点位置, 因此你可以尝试先实现get函数。
4 get 实现
接下来实现get函数:
// 查找键值对
SkipListIterator SkipList::get(const std::string &key, uint64_t tranc_id) {
// spdlog::trace("SkipList--get({}) called", key);
// ? 你可以参照上面的注释完成日志输出以便于调试
// ? 日志为输出到你执行二进制所在目录下的log文件夹
// TODO: Lab1.1 任务:实现查找键值对,
// TODO: 并且你后续需要额外实现SkipListIterator中的TODO部分(Lab1.2)
return SkipListIterator{};
}
可以看到, 我们的get返回的是一个SkipListIterator, 它是一个迭代器, 可以用来遍历SkipList中的元素。这一部分涉及SkipList Iterator的实现不会在文档中进行展开, 你需要阅读源码, 这也是一项基本能力(这部分代码很简单, 别怕:smile:)
这里的迭代器调用构造函数就可以了, 目前的
SkipListIterator实现了一部分, 关于自增等运算符重载, 你将在后续的任务中实现。
4 测试
当你完成上述操作后, test/test_skiplist.cpp中的部分单元测试你应该能够通过:
✗ cd tiny-lsm
✗ xmake
✗ xmake run test_skiplist
[==========] Running 12 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 12 tests from SkipListTest
[ RUN ] SkipListTest.BasicOperations
[ OK ] SkipListTest.BasicOperations (0 ms)
[ RUN ] SkipListTest.LargeScaleInsertAndGet
[ OK ] SkipListTest.LargeScaleInsertAndGet (6 ms)
[ RUN ] SkipListTest.LargeScaleRemove
[ OK ] SkipListTest.LargeScaleRemove (6 ms)
[ RUN ] SkipListTest.DuplicateInsert
[ OK ] SkipListTest.DuplicateInsert (0 ms)
[ RUN ] SkipListTest.EmptySkipList
[ OK ] SkipListTest.EmptySkipList (0 ms)
[ RUN ] SkipListTest.RandomInsertAndRemove
[ OK ] SkipListTest.RandomInsertAndRemove (5 ms)
[ RUN ] SkipListTest.MemorySizeTracking
[ OK ] SkipListTest.MemorySizeTracking (0 ms)
[ RUN ] SkipListTest.Iterator
^C
到SkipListTest.Iterator前的单元测试你应该都能够通过, 卡在SkipListTest.Iterator是因为我们很没有实现迭代器相关功能。
恭喜你, 你已经完成了SkipList的基础CRUD实现。接下来你可以进行Lab1.2了。
Lab 1.2 迭代器
1 概述
这一部分的内容很简单, 只需要补全跳表迭代器即可。跳表的迭代器基本上就是对SkiplistNode的最简化封装, 这一小节的代码量非常少, 也很简单, 不过重点是迭代器的设计和基类的继承关系。
我们先来看它继承了什么基类:
class SkipListIterator : public BaseIterator
这里的BaseIterator是所有组件的基类, 它的声明在include/iterator/iterator.h中。它是后续我们不同组件之间交互的桥梁。建议同学们认真读一下相关代码,很简单但很重要。
2 迭代器补全
你需要补全src/skiplist/skipList.cpp中标记为// TODO: Lab1.2的迭代器函数:
BaseIterator &SkipListIterator::operator++() {
// TODO: Lab1.2 任务:实现SkipListIterator的++操作符
return *this;
}
bool SkipListIterator::operator==(const BaseIterator &other) const {
// TODO: Lab1.2 任务:实现SkipListIterator的==操作符
return true;
}
bool SkipListIterator::operator!=(const BaseIterator &other) const {
// TODO: Lab1.2 任务:实现SkipListIterator的!=操作符
return true;
}
SkipListIterator::value_type SkipListIterator::operator*() const {
// TODO: Lab1.2 任务:实现SkipListIterator的*操作符
return {"", ""};
}
IteratorType SkipListIterator::get_type() const {
// TODO: Lab1.2 任务:实现SkipListIterator的get_type
// ? 主要是为了熟悉基类的定义和继承关系
return IteratorType::Undefined;
}
3 测试
现在你应该能通过test/test_skiplist.cpp中的SkipListTest.Iterator单元测试了
没问题我们开始Lab 1的最后一部分: Lab 1.3 范围查询
Lab 1.3 范围查询
1 范围查询的特性
根据之前的介绍我们了解到, 我们实现的跳表是一个有序数据结构, 而我们构建的数据库是K00V00数据库, 因此除了最基础的CRUD操作外, 我们还需要实现一个范围查询的功能。这些范围查询包括:
- 前缀查询: 通过前缀查询, 我们可以查询以某个前缀开头的所有键值对。比如, 我们数据库中如果
k00ey用userxxx标识用户数据, 可以查询以"userxx"开头的所有用户数据的键值对。 - 范围查询: 通过范围查询, 我们可以查询某个范围内的键值对。比如, 我们数据库中如果
k00ey是学生的学号, 那么我们可以查询某个学号范围内的学生数据[100, 200)。
以上的查询都存在一个特性: 他们是单调的查询, 也就是说在全局数据库中只会出现一个这样的区间。
例如我们有下面的键值对:
(k001, v001), (k002, v002), (k003, v003), (k004, v004), (k005, v005), (k006, v006), (k007, v007), (k008, v008), (k009, v009), (k010, v010)
- 我们查询
key >= k005 && key < k008的范围, 我们可以得到:
(k005, v005), (k006, v006), (k007, v007)`。
- 我们查询
key前缀为k00的键值对, 我们可以得到:
`(k001, v001), (k002, v002), (k003, v003), (k004, v004), (k005, v005), (k006, v006), (k007, v007), (k008, v008), (k009, v009)`。
可以看到, 这些查询都是单调的, 也就是说, 全局数据库中只会出现一个这样的区间。而考虑到我们的数据库是有序的, 因此可以使用二分查询的方式, 确定查询区间的开始位置和结束位置, 以迭代器的形式返回查询结果即可。
2 实现
2.1 前缀查询
你需要实现这两个函数:
// 找到前缀的起始位置
// 返回第一个前缀匹配或者大于前缀的迭代器
SkipListIterator SkipList::begin_preffix(const std::string &preffix) {
// TODO: Lab1.3 任务:实现前缀查询的起始位置
return SkipListIterator{};
}
// 找到前缀的终结位置
SkipListIterator SkipList::end_preffix(const std::string &prefix) {
// TODO: Lab1.3 任务:实现前缀查询的终结位置
return SkipListIterator{};
}
注意的是, 这里迭代器返回的定义类似STL中迭代器end, 其并不属于指定的区间类, 也就是说区间的数学表达是[begin, end)
2.2 谓词查询
这里除了前缀查询外, 还包括各种其他的查询, 只要他们是单调的即可。因此我们给出了一种更通用的接口, 谓词查询, 只需要上层调用者提供一个谓词(lambda函数或者仿函数均可), 我们就可以实现各种单调区间的范围查询。
因此, 我们可以设计这样一个查询接口, 其接收一个谓词, 这个谓词的具体函数体说明此次查询是普通的范围查询、前缀匹配或者是其他的单条区间查询, 但要求结果一定在全局只位于一个连续区间中就可以。同时该谓词不能返回bool值, 而是类似字符串比较那样返回一个int值, 0 表示不匹配, 1 表示大于, -1 表示小于。这样我们才可以根据返回值确定下一步二分查找的方向。
我们需要逐层次实现这个支持谓词的查询接口,其返回一组迭代器表示start和end, 这里我们还是要利用SkipList的有序性多层不同步长的链表来实现快速的匹配查询。
你需要实现下面的函数:
// ? 这里单调谓词的含义是, 整个数据库只会有一段连续区间满足此谓词
// ? 例如之前特化的前缀查询,以及后续可能的范围查询,都可以转化为谓词查询
// ? 返回第一个满足谓词的位置和最后一个满足谓词的迭代器
// ? 如果不存在, 范围nullptr
// ? 谓词作用于key, 且保证满足谓词的结果只在一段连续的区间内, 例如前缀匹配的谓词
// ? predicate返回值:
// ? 0: 满足谓词
// ? >0: 不满足谓词, 需要向右移动
// ? <0: 不满足谓词, 需要向左移动
// ! Skiplist 中的谓词查询不会进行事务id的判断, 需要上层自己进行判断
std::optional<std::pair<SkipListIterator, SkipListIterator>>
SkipList::iters_monotony_predicate(
std::function<int(const std::string &)> predicate) {
// TODO: Lab1.3 任务:实现谓词查询的起始位置
return std::nullopt;
}
Hint: 这里的思路其实也很简单, 推荐的思路如下:
- 先逐次使用高
Level的链表, 逐次降低, 找到满足谓词的区间的某一个节点node1- 根据找到的节点
node1, 逐次向左移动, 直到找到第一个满足谓词的节点node0- 根据找到的节点
node1, 逐次向右移动, 直到找到最后一个满足谓词的节点node2- 返回找到的节点
node0和node2
看到这里你应该也明白了, 为什么实验的
Skiplist的头文件定义采用了双向链表, 目的就是方便这里谓词查询链表节点方向移动的便捷性
3 测试
完成上面的函数后, 你应该可以通过除了SkipListTest.TransactionId外所有的test/test_skiplist.cpp的单元测试:
✗ xmake
[100%]: build ok, spent 5.785s
✗ xmake run test_skiplist
[==========] Running 12 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 12 tests from SkipListTest
[ RUN ] SkipListTest.BasicOperations
[ OK ] SkipListTest.BasicOperations (0 ms)
[ RUN ] SkipListTest.LargeScaleInsertAndGet
[ OK ] SkipListTest.LargeScaleInsertAndGet (7 ms)
[ RUN ] SkipListTest.LargeScaleRemove
[ OK ] SkipListTest.LargeScaleRemove (6 ms)
[ RUN ] SkipListTest.DuplicateInsert
[ OK ] SkipListTest.DuplicateInsert (0 ms)
[ RUN ] SkipListTest.EmptySkipList
[ OK ] SkipListTest.EmptySkipList (0 ms)
[ RUN ] SkipListTest.RandomInsertAndRemove
[ OK ] SkipListTest.RandomInsertAndRemove (6 ms)
[ RUN ] SkipListTest.MemorySizeTracking
[ OK ] SkipListTest.MemorySizeTracking (0 ms)
[ RUN ] SkipListTest.Iterator
[ OK ] SkipListTest.Iterator (0 ms)
[ RUN ] SkipListTest.IteratorPreffix
[ OK ] SkipListTest.IteratorPreffix (0 ms)
[ RUN ] SkipListTest.ItersPredicate_Base
[ OK ] SkipListTest.ItersPredicate_Base (0 ms)
[ RUN ] SkipListTest.ItersPredicate_Large
[ OK ] SkipListTest.ItersPredicate_Large (5 ms)
[ RUN ] SkipListTest.TransactionId^
SkipListTest.TransactionId单元测试是Lab 5.1的内容, 你可以先忽略它。
此外, 单元测试目前并没有规定你的实现的效率, 但你的实现在release模式下, 不应该超过100ms, (30ms以内最佳)
到此为止, Lab1的实验结束, 恭喜你完成本实验!
Lab 2 MemTabele
本Lab中, 你将基于之前实现的Skiplist, 将其组织成内存中负责存储键值对的组件MemTable。
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
1 MemTable的构造原理
再次回顾我们的整体架构图:
MemTable负责存储内存中的键值对数据,其存储的基础容器即为Skiplist。SkipList被划分为2组:current_table和frozen_table。current_table可读可写,并是唯一写入的SkipList,frozen_table是只读状态,用于存储已经写入的键值对数据。current_table容量超出阈值即转化为frozen_table中的一个。
为什么要如此设计呢? 答案是为了提升并发性, 我们的查询与写入的逻辑如下图所示:
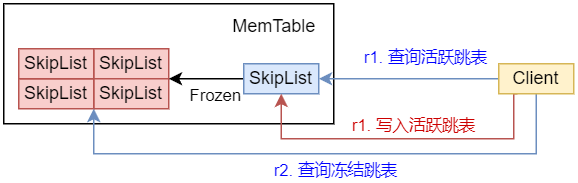
我们在写入时始终只对活跃的current_table进行写入,而查询时则同时对current_table和frozen_table进行查询。这样, 如果我们不将内存表进行划分的话, 查询和写入将同时对一张大的SkipList进行操作, 这将导致并发度降低。反之, 我们将MemTable划分为current_table和frozen_tables后, 我们可以在写入current_table的同时对frozen table进行查询, 大幅度提升了并发量。
2 SkipList查询的优先级
由之前的理论描述所知, 我们的frozen_tables包含多份Skiplist, 而LSM Tree的写入是追加写入, 后写入的数据会覆盖前面的数据。因此,查询时,我们应该按照从新到旧的顺序查询frozen_tables。如同架构图中Get的查询路径中Path 1.1, Path 1.2, Path 1.3, Path 1.4分别按照从新到旧的顺序查询Skiplist, 一旦查询成功即返回。
3 思考
本实验的惯例是先介绍对应
Lab的基本原理, 再抛出一些思考题,你可以简单地对思考题给出一个心智层面的解决方案, 然后开启后续的Lab。
现在又到了我们的思考环节, 根据之前的描述, 将SkipList组织为MemTable好像很简单。但是别忘了,我们之前讲述的都是最基本的单点查询和写入,如果是更复杂的情形呢? 比如:
- 要查询前缀为
xxx的所有键值对- 很多个
Skiplist中都可能存在这样的键值对, 我们需要依次遍历吗? - 有些旧
Skiplist中的键值对已经被更新的Skiplist的数据覆盖了, 是否需要过滤? 如何过滤?
- 很多个
- 如何为
MemTable实现迭代器?KV数据库的迭代器肯定是按照key的顺序从小大大排布- 多个
Skiplist的键值对如何进行整合, 从而也实现从小大大的排布?
通过本节对MemTable的基本介绍, 以及进阶问题的思考, 你可以开始[Lab ]
Lab 2.1 简单 CRUD
1 准备工作
本小节需要你修改的代码:
-src/memtable/memtable.cpp
include/memtable/memtable.h(Optional)
同样的,我们先看看代码的头文件东一,从而了解我们的MemTable的整体实现思路:
class MemTable {
// ...
private:
std::shared_ptr<SkipList> current_table;
std::list<std::shared_ptr<SkipList>> frozen_tables;
size_t frozen_bytes;
std::shared_mutex frozen_mtx; // 冻结表的锁
std::shared_mutex cur_mtx; // 活跃表的锁
};
这里我们根据之前的原理介绍, 对之前的SkipList简单包装, 使用list保证一系列冻结的Skiplist。这里建议的规定是:
最新的Skiplist放在list的head位置,最旧的Skiplist放在list的tail位置。
此外, 你在头文件中除了基础的CRUD函数外, 还会看到这个函数:
std::shared_ptr<SST> flush_last(SSTBuilder &builder, std::string &sst_path,
size_t sst_id,
std::vector<uint64_t> &flushed_tranc_ids,
std::shared_ptr<BlockCache> block_cache);
这个函数不是本Lab要求实现的函数, 但可以先进行简单的介绍便于认知整体架构。当MemTable中的数据量达到阈值时, 会调用这个函数将最古老的一个SST进行持久化, 形成一个Level 0的SST, 因此你可以理解为, Skiplist是和Level 0 SST的数据来源。
其中新增的flushed_tranc_ids是一个输出参数, 刷盘过程中会将已经完成的事务id收集到这个数组中, 供上层组件通知事务管理器哪些事务已经安全持久化。
2 put 的实现
你首先要实现的是put系列的函数:
void MemTable::put_(const std::string &key, const std::string &value,
uint64_t tranc_id) {
// TODO: Lab2.1 无锁版本的 put
}
void MemTable::put(const std::string &key, const std::string &value,
uint64_t tranc_id) {
// TODO: Lab2.1 有锁版本的 put
}
void MemTable::put_batch(
const std::vector<std::pair<std::string, std::string>> &kvs,
uint64_t tranc_id) {
// TODO: Lab2.1 有锁版本的 put_batch
}
这里的put有多个版本, 分别是无锁版本和有锁版本的单次put以及有锁版本的批量put, 你必须按照语义实现这些函数, 因为后续上层组件调用的函数默认携带_后缀的函数版本是无锁操作版本。
同时简单讲述以下如此设计的原因,某些并发控制只需要当前的MemTable组件控制即可, 但有些并发控制场景设计多个组件, 需要再上层进行, 例如后续事务提交时的冲突检测就是一个典型的案例。
Hint: 你不仅仅需要做简单的
API调用, 还需要判断什么时候Skiplist的容量超出阈值需要进行冻结
3 get 的实现
接下来实现get的一系列函数, 同样包括无锁版本与有锁版本, 并且你还需要实现不同部分的分阶段查询:
SkipListIterator MemTable::cur_get_(const std::string &key, uint64_t tranc_id) {
// 检查当前活跃的memtable
// TODO: Lab2.1 从活跃跳表中查询
return SkipListIterator{};
}
SkipListIterator MemTable::frozen_get_(const std::string &key,
uint64_t tranc_id) {
// TODO: Lab2.1 从冻结跳表中查询
// ? 你需要尤其注意跳表的遍历顺序
// ? tranc_id 参数可暂时忽略, 直接插入即可
return SkipListIterator{};
;
}
SkipListIterator MemTable::get(const std::string &key, uint64_t tranc_id) {
// TODO: Lab2.1 查询, 建议复用 cur_get_ 和 frozen_get_
// ? 注意并发控制
return SkipListIterator{};
}
SkipListIterator MemTable::get_(const std::string &key, uint64_t tranc_id) {
// TODO: Lab2.1 查询, 无锁版本
}
4 remove 实现
最后, 插入value为空的键值对表示对数据的删除标记, 同样有不同的版本:
void MemTable::remove_(const std::string &key, uint64_t tranc_id) {
// TODO Lab2.1 无锁版本的remove
}
void MemTable::remove(const std::string &key, uint64_t tranc_id) {
// TODO Lab2.1 有锁版本的remove
}
void MemTable::remove_batch(const std::vector<std::string> &keys,
uint64_t tranc_id) {
// TODO Lab2.1 有锁版本的remove_batch
}
5 冻结活跃表
Skiplist的容量超出阈值需要进行冻结时需要调用下述函数。
至于这个函数的调用实际,作者建议是在每次put后检查容量是否超出阈值, 然后同步地调用该函数, 当然你也可以启用一个后台线程进行周期性检查。
void MemTable::frozen_cur_table_() {
// TODO: 冻结活跃表
}
void MemTable::frozen_cur_table() {
// TODO: 冻结活跃表, 有锁版本
}
Hint
src/config/config.cpp中定义了一个配置文件的单例, 其会解析项目目录中的config.toml配置文件, 其中包含了各种阈值的推荐值- 你可以使用类似
TomlConfig::getInstance().getLsmPerMemSizeLimit()的方法获取配置文件中定义的常量- 你可以修改
config.toml配置文件的值, 但尽量不要新增配置项, 否则你需要自行修改src/config/config.cpp中的解析函数
6 测试
当你完成上述所有功能后, 你可以通过如下测试:
✗ xmake
✗ xmake run test_memtable
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from MemTableTest
[ RUN ] MemTableTest.BasicOperations
[ OK ] MemTableTest.BasicOperations (2 ms)
[ RUN ] MemTableTest.RemoveOperations
[ OK ] MemTableTest.RemoveOperations (0 ms)
[ RUN ] MemTableTest.FrozenTableOperations
[ OK ] MemTableTest.FrozenTableOperations (0 ms)
[ RUN ] MemTableTest.LargeScaleOperations
[ OK ] MemTableTest.LargeScaleOperations (0 ms)
[ RUN ] MemTableTest.MemorySizeTracking
[ OK ] MemTableTest.MemorySizeTracking (0 ms)
[ RUN ] MemTableTest.MultipleFrozenTables
[ OK ] MemTableTest.MultipleFrozenTables (0 ms)
[ RUN ] MemTableTest.ConcurrentOperations
^C
ConcurrentOperations需要你实现后续的迭代器功能。
接下来你可以开启下一小节的Lab
Lab 2.2 迭代器
1 迭代器的作用
我们需要实现整个MemTable的迭代器, 这算是本Lab的一个难点, 因为新的SkipList中的元素会导致旧的SkipList的部分元素失效, 因此不能简单地将不同SkipList的遍历结果拼接起来就完事儿。
试想下面这个场景:
SkipList0: ("k1", "v1") -> ("k4", "") -> ("k5", "v3")
SkipList1: ("k2", "v2") -> ("k3", "v3") -> ("k4", "v4")
SkipList0中的("k4", "")表示删除了"k4", 因此如果我们先消耗了SkipList0的迭代器, 那么SkipList1中就无法获取"k4"的不合法性, 因此需要对不同SkipList的迭代器进行merge操作来删除这些无效的元素。
本实验的建议方案是:
可以维护一个堆,堆首先根据key排序, 然后根据SkipList id排序, 因此相同的key, 后插入的记录肯定更靠近堆顶(因为SkipList id越小表示其越新), 因此堆顶的某个key一定是整个MemTable中该key的最新记录, 迭代器对该key只需要堆顶的这一个元素, 其余在取出堆顶后即可全部移除(因为首先按照key排序, 所以他们一定连续出现在堆顶)
2 堆去重的原理
我们假设有以下两个 SkipList:
SkipList0 (id=0): ("k1", "v1") -> ("k4", "") -> ("k5", "v3") // 最新的
SkipList1 (id=1): ("k2", "v2") -> ("k3", "v3") -> ("k4", "v4")
我们借助之前Skiplist的迭代器, 遍历各个Skiplist, 把所有键值对按 key 排序后放入堆,排序依据是:
- 先按
key升序,即key越小越靠近堆顶 - 对于相同的
key,选择tranc_id较大(越新)的优先(越靠近堆顶)(这一条你可暂时哦忽略, 测试中tranc_id都是0) - 按照
SkipList来源的新旧排序, 新SkipList的键值对更靠近堆顶(这里的id是构建堆时手动赋予的)
最后的排序依据中, 这个新旧的顺序需要你手动指定, 无论你实现的排序是更大的
id表示更新的SKiplist还是更小的id表示更新的SKiplist, 自身逻辑自洽即可 建议将更新的Skiplist用更大的id标识, 因为id随新的Skiplist增长是很正常的事情
遍历迭代器, 并逐一构建堆元素插入堆中, 最终的堆的示意图为:
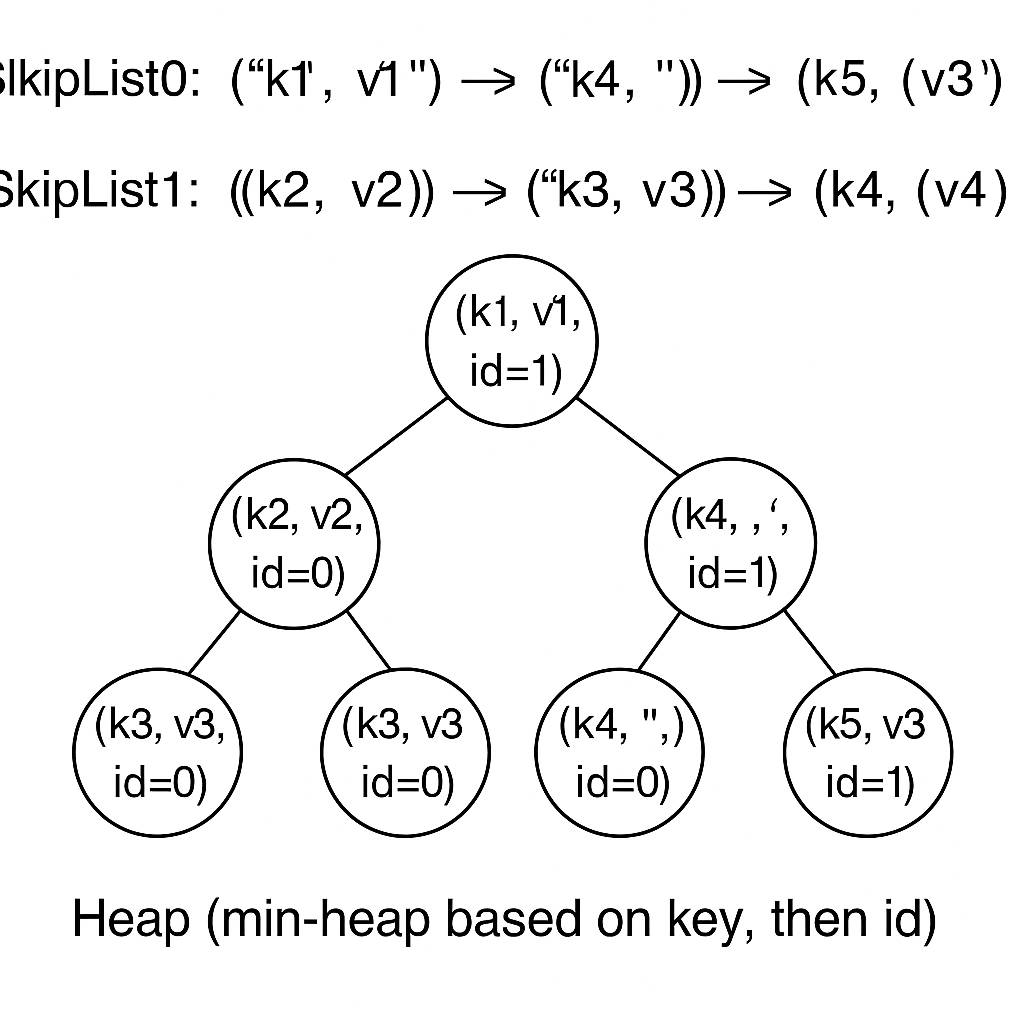
这里可以看到, k4的键值对中, 更新的跳表中的键值对更靠近堆顶, 当我们遍历这个堆并不断弹出元素时, 相同key的元素只能被迭代器(这个堆肯定是迭代器封装的一个成员变量)对外暴露一次, 其余相同key的键值对进行丢弃即可, 这样我们就能利用类似堆排序的功能, 同时完成了排序和去重。
3 基于堆的迭代器实现
3.1 代码框架介绍
因此,本实验你首先要基于上述原理的介绍实现一个基于堆的迭代器。
本小节需要你修改的代码:
src/iterator/iterator.cppinclude/iterator/iterator.h(Optional)src/memtable/memtable.cppinclude/memtable/memtable.h(Optional)
首先是SearchItem, 我们来看定义:
// *************************** SearchItem ***************************
struct SearchItem {
std::string key_;
std::string value_;
uint64_t tranc_id_;
int idx_;
int level_; // 来自sst的level
SearchItem() = default;
SearchItem(std::string k, std::string v, int i, int l, uint64_t tranc_id)
: key_(std::move(k)), value_(std::move(v)), idx_(i), level_(l),
tranc_id_(tranc_id) {}
};
bool operator<(const SearchItem &a, const SearchItem &b);
bool operator>(const SearchItem &a, const SearchItem &b);
bool operator==(const SearchItem &a, const SearchItem &b);
其就是我们之前提到的每个堆节点的数据结构, 这里的构造函数中, k, v, i即为key, value, id(跳表的), l表示来源的层级, 现在我们都是在内存操作, 设为0即可, tranc_id不需要你理解, 直接赋值即可。
然后是你要实现的迭代器HeapIterator的定义:
class HeapIterator : public BaseIterator {
public:
HeapIterator() = default;
HeapIterator(std::vector<SearchItem> item_vec, uint64_t max_tranc_id);
// ...
private:
std::priority_queue<SearchItem, std::vector<SearchItem>,
std::greater<SearchItem>>
items;
mutable std::shared_ptr<value_type> current; // 用于存储当前元素
uint64_t max_tranc_id_ = 0;
};
这里的priority_queue就是我们之前提到的堆, C++的堆实际上就是优先队列。
在
C++中,当使用std::priority_queue来实现小根堆(min-heap)时,你需要使用std::greater<SearchItem>作为比较函数对象。感兴趣的同学可以查一查为什么要这么设计。
3.2 实现 SearchItem 的比较规则
bool operator<(const SearchItem &a, const SearchItem &b) {
// TODO: Lab2.2 实现比较规则
return true;
}
bool operator>(const SearchItem &a, const SearchItem &b) {
// TODO: Lab2.2 实现比较规则
return true;
}
bool operator==(const SearchItem &a, const SearchItem &b) {
// TODO: Lab2.2 实现比较规则
return true;
}
这里你需要按照之前介绍的比较规则进行代码补全。
3.3 实现构造函数
接下来你需要实现HeapIterator的构造函数, 其参数就是已经遍历了所有Skiplist的迭代器构造的vector, max_tranc_id你可以暂时忽略:
HeapIterator::HeapIterator(bool skip_delete)
: max_tranc_id_(0), skip_delete_(skip_delete) {
// TODO: Lab2.2 实现 HeapIterator 构造函数
}
HeapIterator::HeapIterator(std::vector<SearchItem> item_vec,
uint64_t max_tranc_id, bool skip_delete)
: max_tranc_id_(max_tranc_id), skip_delete_(skip_delete) {
// TODO: Lab2.2 实现 HeapIterator 构造函数
}
Hint 1: 构造完堆后, 是否需要额外的一些初始化的滤除? Hint 2: (重要!!!)这里说明下
skip_delete参数,这个参数用于控制迭代器是否删除value为空的键值对。value为空在逻辑上表示删除标记,这样的键值对是否保留取决于具体场景。当作为借口暴露给外部时,我们应该跳过删除的键值对;但用于数据刷盘时,删除标记是有效的存储记录,是不能被跳过的。
3.4 实现自增函数
接下来自增函数是最重要的, 自增函数的逻辑是:
- 自增后的
key不能是之前相同的key, 如果是(以为着实际上被前者覆写了), 则跳过 - 自增后的键值对不能是删除标记, 即
value为空
BaseIterator &HeapIterator::operator++() {
// TODO: Lab2.2 实现 ++ 重载
return *this;
}
同时, 这些辅助函数的实现有助于你完成:operator++()和之前的构造函数:
bool HeapIterator::top_value_legal() const {
// TODO: Lab2.2 判断顶部元素是否合法
// ? 被删除的值是不合法
// ? 不允许访问的事务创建或更改的键值对不合法(暂时忽略)
return true;
}
void HeapIterator::skip_by_tranc_id() {
// TODO: Lab2.2 后续的Lab实现, 只是作为标记提醒
}
3.4 其他运算符重载函数
其他运算符重载函数就简单了很多, 但仍然是对你代码理解的考验:
HeapIterator::pointer HeapIterator::operator->() const {
// TODO: Lab2.2 实现 -> 重载
return nullptr;
}
HeapIterator::value_type HeapIterator::operator*() const {
// TODO: Lab2.2 实现 * 重载
return {};
}
BaseIterator &HeapIterator::operator++() {
// TODO: Lab2.2 实现 ++ 重载
return *this;
}
bool HeapIterator::operator==(const BaseIterator &other) const {
// TODO: Lab2.2 实现 == 重载
return true;
}
bool HeapIterator::operator!=(const BaseIterator &other) const {
// TODO: Lab2.2 实现 != 重载
return true;
}
其中->运算符重载, 你可以直接利用已有的成员变量mutable std::shared_ptr<value_type> current, 返回器地址, 但你需要在构造函数和自增函数中对其进行正确的初始化和重置, 下面这个函数即为初始化和重置的逻辑实现:
void HeapIterator::update_current() const {
// current 缓存了当前键值对的值, 你实现 -> 重载时可能需要
// TODO: Lab2.2 更新当前缓存值
}
4 MemTable的迭代器
接下来, 有了HeapIterator, 你可以实现MemTable组件的全局迭代器了:
HeapIterator MemTable::begin(uint64_t tranc_id) {
// TODO Lab 2.2 MemTable 的迭代器
return {};
}
HeapIterator MemTable::end() {
// TODO Lab 2.2 MemTable 的迭代器
return HeapIterator{};
}
这里的逻辑就是利用之前实现的HeapIterator对整个MemTable进行遍历。
5 测试
当你完成上述所有功能后, 你可以通过如下测试:
✗ xmake
✗ xmake run test_memtable
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from MemTableTest
[ RUN ] MemTableTest.BasicOperations
[ OK ] MemTableTest.BasicOperations (0 ms)
[ RUN ] MemTableTest.RemoveOperations
[ OK ] MemTableTest.RemoveOperations (0 ms)
[ RUN ] MemTableTest.FrozenTableOperations
[ OK ] MemTableTest.FrozenTableOperations (0 ms)
[ RUN ] MemTableTest.LargeScaleOperations
[ OK ] MemTableTest.LargeScaleOperations (0 ms)
[ RUN ] MemTableTest.MemorySizeTracking
[ OK ] MemTableTest.MemorySizeTracking (0 ms)
[ RUN ] MemTableTest.MultipleFrozenTables
[ OK ] MemTableTest.MultipleFrozenTables (0 ms)
[ RUN ] MemTableTest.IteratorComplexOperations
[ OK ] MemTableTest.IteratorComplexOperations (0 ms)
[ RUN ] MemTableTest.ConcurrentOperations
[ OK ] MemTableTest.ConcurrentOperations (601 ms)
[ RUN ] MemTableTest.PreffixIter
[ OK ] MemTableTest.PreffixIter (0 ms)
[----------] 9 tests from MemTableTest (602 ms total)
[----------] Global test environment tear-down
[==========] 9 tests from 1 test suite ran. (602 ms total)
[ PASSED ] 9 tests.
接下来你可以开启下一小节的Lab
Lab 2.3 范围查询
1 概述
还记得我们对Skiplist实现了前缀查询和谓词查询吗, 他们本质上都是范围查询, 这一小节, 你将基于已有的Skiplist的前缀查询和谓词查询接口, 实现MemTable的谓词查询。
本小节需要你修改的代码:
-src/memtable/memtable.cpp
include/memtable/memtable.h(Optional)
2 实现 iters_preffix
HeapIterator MemTable::iters_preffix(const std::string &preffix,
uint64_t tranc_id) {
// TODO Lab 2.3 MemTable 的前缀迭代器
return {};
}
你需要借助Skiplist的begin_preffix完成这个MemTable::iters_preffix, 你可以从返回值类型推断出, 我们仍然需要借助HeapIterator进行去重和排序。
这里需要注意的还是自定义的排序id(就是SearchItem里面的成员变量idx_), 你需要在构造HeapIterator手动赋予idx_正确的整型值。
另外,tranc_id相关的滤除操作你可以暂时忽略, 直接传入SearchItem的构造函数即可。
需要注意的是, 这个返回的迭代器从语义上是
begin迭代器, 其使用方式是判断自身是否is_valid()以及is_end(), 不同于C++ STL中给定一对迭代器确定范围的风格。这也算是作者前期项目设计的不足之处,介于次代码和实验还是初版,能用能跑就行。
3 实现 iters_monotony_predicate
std::optional<std::pair<HeapIterator, HeapIterator>>
MemTable::iters_monotony_predicate(
uint64_t tranc_id, std::function<int(const std::string &)> predicate) {
// TODO Lab 2.3 MemTable 的谓词查询迭代器起始范围
return std::nullopt;
}
和iters_preffix类似, 只不过查询逻辑从特化的前缀查询变成了适用性更广泛的谓词查询, 注意事项也都差不多, 同样是借助Skiplist的iters_monotony_predicate(predicate)获取初步的结果, 再用HeapIterator区中。
4 测试
完成上面的函数后, 你应该可以通过所有的test/test_memtable.cpp的单元测试:
✗ xmake
✗ xmake run test_memtable
[==========] Running 12 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 12 tests from MemTableTest
[ RUN ] MemTableTest.BasicOperations
[ OK ] MemTableTest.BasicOperations (0 ms)
[ RUN ] MemTableTest.RemoveOperations
[ OK ] MemTableTest.RemoveOperations (0 ms)
[ RUN ] MemTableTest.FrozenTableOperations
[ OK ] MemTableTest.FrozenTableOperations (0 ms)
[ RUN ] MemTableTest.LargeScaleOperations
[ OK ] MemTableTest.LargeScaleOperations (1 ms)
[ RUN ] MemTableTest.MemorySizeTracking
[ OK ] MemTableTest.MemorySizeTracking (0 ms)
[ RUN ] MemTableTest.MultipleFrozenTables
[ OK ] MemTableTest.MultipleFrozenTables (0 ms)
[ RUN ] MemTableTest.IteratorComplexOperations
[ OK ] MemTableTest.IteratorComplexOperations (0 ms)
[ RUN ] MemTableTest.ConcurrentOperations
[ OK ] MemTableTest.ConcurrentOperations (604 ms)
[ RUN ] MemTableTest.PreffixIter
[ OK ] MemTableTest.PreffixIter (0 ms)
[ RUN ] MemTableTest.IteratorPreffix
[ OK ] MemTableTest.IteratorPreffix (0 ms)
[ RUN ] MemTableTest.ItersPredicate_Base
[ OK ] MemTableTest.ItersPredicate_Base (0 ms)
[ RUN ] MemTableTest.ItersPredicate_Large
[ OK ] MemTableTest.ItersPredicate_Large (13 ms)
[----------] 12 tests from MemTableTest (620 ms total)
[----------] Global test environment tear-down
[==========] 12 tests from 1 test suite ran. (620 ms total)
[ PASSED ] 12 tests.
到此为止, Lab2的实验结束, 恭喜你完成本实验!
Lab 3 SST
1 概述
这一章的开头我们再次搬出我们的经典架构图:
通过Lab1和Lab2的学习,我们已经初步完成了LSM Tree中内存的基础读写组件, 这一章我们将眼光从内存迁移到磁盘, 实现SST相关的内容。
从架构图中我们知道,SST文件是LSM Tree中持久化的存储文件,其中Level 0的SST存储了MemTable中单个Skiplist的数据,并且提供了LSM Tree中数据的有序性。因此对于一个磁盘中的文件, 我们肯定需要实现文件的编解码设计。其中编码设计用于将内存的Skiplist类的实例转化为SST文件, 而读取SST中的某些键值对时我们需要将文件进行解码并读取数据到内存。因此这一章中编解码是一大主题内容。而且相对之前常驻内存的MemTable而言, 这里的编解码代码的实现更为复杂, 尤其是Debug难度比之前要大上不少。
此外,我们从架构图中还了解到,不同Level的SST是需要再容量超出阈值时进行合并(Compact)的, 但Compact在本实验中是由更上层的控制结构实现的, 因此本节实验你不需要担心Compact, 这是后续Lab的内容, 这里提一嘴只是为了有助于从理论上理解其运行机制。
2 SST 的结构
从架构图中我们了解到,不同Level之间的容量呈指数增长, 其中最小的Level 0的SST也是SkipList的大小, 而SkipList实例在内存中是由多个链表组成的, 查询速度基本上和红黑树差不多。但假若我们想从SST中查一个键值对,总不可能把整个SST都解码放到内存中吧? 要知道高层Level的SST是可以轻易增长到GB的大小的。因此,SST必须进行内部的切分, 这里切分形成的一块数据我们称之为Block。因此对Block的组织管理就是SST设计的核心内容。Tiny-LSM的SST文件结构如下:

SST文件由多个Block组成,每个Block_x内部暂且看成一个黑箱, 只需要知道其是我们查询的基本IO单元即可。 每个Block_x后会追加32位的哈希值,用于校验。每个Block对应一个Meta, 每个Meta记录这个Block在SST文件中的偏移量、第一个和最后一个key的元数据(长度和大小)。
这里,Block是基本的IO单元,这就意味着在查询一个key时, 其所在的整个Block的数据都会被解码并加载到内存中的。你可以类比操作系统中的Page, 其是内存和磁盘之间的基本IO单元。
另一方面,在查询一个key时,如何确定查哪一个Block呢? 这里就需要将SST中的Extra Information中的元数据提前加载到内存中, 这些元数据能够定位到Meta Section, 而Meta Section是一个数组, 其中每个Meta_x记录了对应Block在整个SST中的位置, 可以以此来快速对指定为位置的二进制数据进行解码。
你肯定能想到, 作为基本的IO单元, 我们肯定会为其实现一个缓存池的, 这样可以避免每次查询时都进行磁盘IO。
心细的你肯定也注意到, 这里有一个Bloom Section, 这其实就是布隆过滤器中的bit位数组, 其用处是拦截无效的访问, 这会在后续的Lab中进行详细讲解。
3 Block的结构
现在我们来看Block的结构, Block是SST中的基本IO单元,即SST的每个查询最终是在Blcok中定位到具体的键值对的, 其结构为:

上图的
B表示一个字节
一个Block包含:Data Section、Offset Section和Extra Information三部分:
Data Section: 存放所有的数据, 也就是key和value的序列化数据- 每一对
key和value都是一个Entry, 编码信息包括key_len、key、value_len和valuekey_len和value_len都是2B的uint16_t类型, 用于表示key和value的长度key和value就是对应长度的字节数, 因此需要用varlen来表示。
- 每一对
Offset Section: 存放所有Entry的偏移量, 用于快速定位Extra Information: 存放num_of_elements, 也就是Entry的数量
这样编码满足了最基本的要求, 从最后的2个字节可以知道Block包含了多少kv对, 再从Offset Section中查询对应的kv对数据的偏移。
4 思考
现在有了Block和SST的设计方案, 你可以思考如下几个问题:
Blcok和SST是如何构建的?Block如何进行划分?Block内部如何实现迭代器吗?SST的迭代器是单独设计, 还是对已有Blcok迭代器的封装? 如何封装?Block的缓存池如何设计?- 布隆过滤器和缓存池的设计各自有什么作用? 他们的功能是否重复?
当你对上述问题有过简单思考后, 你可以开启本次Lab了, 你需要有一定心理准备, 这一大章节的Lab原比之前的MemTable和Skiplist复杂, 现在开始第一部分 Block 实现。
阶段1-Block
本阶段主要实现Block类, 包括Block的编码格式, 编解码方法、以及Block的迭代器和相关的查询功能。
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
Lab 3.1 Block 实现
1 准备工作
老套路, 我们先理一下Block的数据结构, 看看头文件定义:
// include/block/block.h
class Block : public std::enable_shared_from_this<Block> {
friend BlockIterator;
private:
std::vector<uint8_t> data; // 对应架构图的 Data
std::vector<uint16_t> offsets; // 对应架构图的 Offset
size_t capacity;
struct Entry {
std::string key;
std::string value;
uint64_t tranc_id;
};
// ...
};
这里可能涉及C++的新特性:
public std::enable_shared_from_this<Block>
std::enable_shared_from_this 是 C++11 引入的一个标准库特性,它允许一个对象安全地创建指向自身的std::shared_ptr。这里先简单说明一下, 后续实现迭代器的时候就知道其作用了。
这里主要对data和offsets这两个数据结构进行说明, 他们在构建阶段和读取阶段存在一定区别, 首先还是给出架构图:
构建阶段
当我们从Skiplist拿到数据构建一个SST时, SST需要逐个构建Block, 这个Block在构建时步骤如下:
- 逐个将编码的键值对(也就是
Entry)写入data数组, 同时将每个Entry的偏移量记录在内存中的offsets数组中。 - 当这个
Block容量达到阈值时,Block构建完成, 你需要将offsets数组写入到Block的末尾。 - 还需要再
Block末尾写入一个Entry Num值, 用于标识这个Block中键值对的数量, 从而在解码时获取Offset的其实位置(因为每个Entry Offset大小是固定的整型值) - 当前
Block构建完成,SST开始构建下一个Block。
这里之所以将先将键值对持久化到
data数组, 而元信息暂存于内存的offsets数组, 是因为Data是在数据部分之后的的Offset部分的偏移需要再键值对完全写入Data部分后才能确定
解码阶段
解码阶段, 直接将Data、Offset解码形成内存中的Block的实例以为上层组件提供查询功能,同时如果实现了缓存池,需要再缓存池中进行记录。
2 代码实现
你需要修改的函数都在src/block/block.cpp中。
2.1 Block 编码和解码
这里你先不要管这个Block是哪里来的, 就当它已经存在, 实现编码和解码的功能:
std::vector<uint8_t> Block::encode(bool with_hash) {
// TODO Lab 3.1 编码单个类实例形成一段字节数组
return {};
}
std::shared_ptr<Block> Block::decode(const std::vector<uint8_t> &encoded,
bool with_hash) {
// TODO Lab 3.1 解码字节数组形成类实例
return nullptr;
}
两个函数都接受 with_hash 参数:
encode(with_hash): 若为true,在编码末尾额外追加 CRC32 校验值(4字节)decode(encoded, with_hash): 若为true,先校验 CRC32,校验失败则抛出异常
这样统一设计,使得
SSTBuilder在构建时可以选择是否写入校验码,read_block在读取时按同样的标志进行校验,编解码行为完全对称。
编解码时你需要注意数据的格式, 如果校验格式错误, 你需要抛出异常, 否则错误将非常难以
Debug
2.2 局部数据编解码函数
对于二进制数据, 你需要按照设计的编码结构获取其key, value和tranc_id, 这里我们实现几个辅助函数:
// 从指定偏移量获取entry的key
std::string Block::get_key_at(size_t offset) const {
// TODO Lab 3.1 从指定偏移量获取entry的key
return "";
}
// 从指定偏移量获取entry的value
std::string Block::get_value_at(size_t offset) const {
// TODO Lab 3.1 从指定偏移量获取entry的value
return "";
}
uint64_t Block::get_tranc_id_at(size_t offset) const {
// TODO Lab 3.1 从指定偏移量获取entry的tranc_id
// ? 你不需要理解tranc_id的具体含义, 直接返回即可
return 0;
}
2.3 构建 Block
Block构建是由SST控制的, 其会不断地调用下面这个函数添加键值对:
bool Block::add_entry(const std::string &key, const std::string &value,
uint64_t tranc_id, bool force_write) {
// TODO Lab 3.1 添加一个键值对到block中
// ? 返回值说明:
// ? true: 成功添加
// ? false: block已满, 拒绝此次添加
return false;
}
这里需要注意, force_write参数表示是否强制写入, 如果为true, 则不管Block是否已满, 都强制写入, 否则如果Block已满, 则拒绝此次写入。
Block是否已满的判断将当前数据容量与成员变量capacity进行比较, capacity在Block初始化时由SST传入, 表示一个Block的最大容量。
如果你需要一些使用
config.toml中预定义的一些阈值变量或者其他常来那个, 你也可以通过TomlConfig::getInstance().getXXX的方式获取
2.4 二分查询
Block构建时是通过SST遍历Skiplist的迭代器调用add_entry实现的, 因此Block的数据是有序的, 你需要实现一个二分查找函数, 用于在Block中查找指定key所属的Entry在offset元数据中的索引:
std::optional<size_t> Block::get_idx_binary(const std::string &key,
uint64_t tranc_id) {
// TODO Lab 3.1 使用二分查找获取key对应的索引
return std::nullopt;
}
get_value_binary函数中会调用get_idx_binary函数, 并返回指定key的value:
// 使用二分查找获取value
// 要求在插入数据时有序插入
std::optional<std::string> Block::get_value_binary(const std::string &key,
uint64_t tranc_id) {
auto idx = get_idx_binary(key, tranc_id);
if (!idx.has_value()) {
return std::nullopt;
}
return get_value_at(offsets[*idx]);
}
3 测试
如果成功完成了上述的所有函数, 你应该如下运行测试并得到结果:
✗ xmake
[100%]: build ok, spent 1.94s
✗ xmake run test_block
[==========] Running 10 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 10 tests from BlockTest
[ RUN ] BlockTest.DecodeTest
[ OK ] BlockTest.DecodeTest (0 ms)
[ RUN ] BlockTest.EncodeTest
[ OK ] BlockTest.EncodeTest (0 ms)
[ RUN ] BlockTest.BinarySearchTest
[ OK ] BlockTest.BinarySearchTest (0 ms)
[ RUN ] BlockTest.EdgeCasesTest
[ OK ] BlockTest.EdgeCasesTest (0 ms)
[ RUN ] BlockTest.LargeDataTest
[ OK ] BlockTest.LargeDataTest (0 ms)
[ RUN ] BlockTest.ErrorHandlingTest
[ OK ] BlockTest.ErrorHandlingTest (1 ms)
[ RUN ] BlockTest.IteratorTest
test/test_block.cpp:225: Failure
Expected equality of these values:
count
Which is: 0
test_data.size()
Which is: 100
你应该能通过BlockTest.IteratorTest之前的所有单元测试, BlockTest.IteratorTest这个测试会测试Block的迭代器功能, 因为Block的迭代器功能还没有实现, 所以会失败, 这是符合预期的。
4 下一步
现在进入下一步前, 你可以先思考:
- 如何实现
Block的迭代器 - 为什么我们需要让
Block类继承std::enable_shared_from_this<Block>?
带着这些疑问, 欢迎开启下一章
Lab 3.2 迭代器
1 BlockIterator的设计
现在实现我们的Block的迭代器。通过Block的编码格式可知, 只需要知道当前的索引, 就可以在Block中查询该索引的kv对, 因此迭代器只需要记录当前索引和原始Block的引用就可以了。
这也就是之前提到的std::enable_shared_from_this的作用,让我们的BlockIterator可以使用Block的智能指针, 为什么这样设计呢? 因为BlockIterator的生命周期是依赖于于Block的, 如果Block的生命周期结束, BlockIterator依然存在, 那么就会产生悬空指针, 因此我们需要使用智能指针来管理Block的生命周期。
这么说可能有点迷糊, 我们直接看头文件定义:
class BlockIterator {
// ...
private:
std::shared_ptr<Block> block; // 指向所属的 Block
size_t current_index; // 当前位置的索引
uint64_t tranc_id_; // 当前事务 id
mutable std::optional<value_type> cached_value; // 缓存当前值
};
cached_value其实算是个小优化, 尽管有索引就在block中进行二分查找, 但这里还是用一个值进行缓存, 因为迭代器可能被反复读取值, 而每次读取值需要按照数据编码的格式进行解码, 在多次读取迭代器值的情况下, 缓存起来从理论上速度回更快
这里的BlockIterator不同于我们之前的HeapIterator, 它并不持有我们实际的键值对数据, 而进行对Block中的键值对位置进行定位, 因此就需要保证其指针block是有效的, 在现代C++中, 我们应该避免使用裸指针, 因此这里使用了std::shared_ptr来保证其指针block有效的。但 std::shared_ptr<Block> block肯定是某个Blcok的this指针, 而this是裸指针, 因此我们需要使Block继承std::enable_shared_from_this, 这样就可以通过shared_from_this()获取代表this指针的shared_ptr<Block>了。
需要注意的是, 使用
shared_from_this()时, 需要保证类的实例被shared_ptr管理, 否则会抛出异常, 具体可以查询相关资料, 这里不过多介绍。
其余成员变量应该很好理解, current_index记录当前索引, tranc_id_记录当前事务 id, cached_value缓存当前值。
2 实现 BlockIterator
本部分你需要修改的代码文件为:
src/block/block_iterator.cppinclude/block/block_iterator.h(Optional)
2.1 构造函数实现
实现构造函数,传入一个 block 和 key,以及事务 tranc_id, 这里在构造迭代器时就将迭代器移动到指定key的位置(还需要满足tranc_id的可见性, 不过现在你可以先忽略这个可见性的判断逻辑)。
你需要借助之前实现的Block的成员函数来实现这的移动逻辑:
BlockIterator::BlockIterator(std::shared_ptr<Block> b, const std::string &key,
uint64_t tranc_id)
: block(b), tranc_id_(tranc_id), cached_value(std::nullopt) {
// TODO: Lab3.2 创建迭代器时直接移动到指定的key位置
// ? 你需要借助之前实现的 Block 类的成员函数
}
2.2 运算符重载
迭代器的运算符重载是你需要实现的基础成员函数:
BlockIterator::pointer BlockIterator::operator->() const {
// TODO: Lab3.2 -> 重载
return nullptr;
}
BlockIterator &BlockIterator::operator++() {
// TODO: Lab3.2 ++ 重载
// ? 在后续的Lab实现事务后,你可能需要对这个函数进行返修
return *this;
}
bool BlockIterator::operator==(const BlockIterator &other) const {
// TODO: Lab3.2 == 重载
return true;
}
bool BlockIterator::operator!=(const BlockIterator &other) const {
// TODO: Lab3.2 != 重载
return true;
}
BlockIterator::value_type BlockIterator::operator*() const {
// TODO: Lab3.2 * 重载
return {};
}
这些运算符重载函数中, 你也不需要考虑
tranc_id的相关逻辑, 只是你需要记得, 后续实现了事务功能后, 本Lab的部分逻辑需要进行调整
2.3 辅助函数
这里有一些作者提供的可能用用的辅助函数, 你可以按选择实现他们, 也可以忽略他们, 自己按照自己的理解创建自定义的成员函数:
void BlockIterator::update_current() const {
// TODO: Lab3.2 更新当前指针
// ? 该函数是可选的实现, 你可以采用自己的其他方案实现->, 而不是使用
// ? cached_value 来缓存当前指针
}
void BlockIterator::skip_by_tranc_id() {
// TODO: Lab3.2 * 跳过事务ID
// ? 只是进行标记以供你在后续Lab实现事务功能后修改
// ? 现在你不需要考虑这个函数
}
这里的skip_by_tranc_id只是标记后续Lab实现事务带来的的一些逻辑上的变化, 你现在不需要实现。
而update_current则是一个可选的实现, 其用来更新缓存的键值对变量, 你可以采用自己的其他方案实现->, 而不是使用成员变量cached_value和这个函数。
4 获取迭代器的接口函数实现
现在我们已经实现了BlockIterator的, 我们需要实现Block的begin和end函数将BlockIterator进行返回给外部组件使用:
BlockIterator Block::begin(uint64_t tranc_id) {
// TODO Lab 3.2 获取begin迭代器
return BlockIterator(nullptr, 0, 0);
}
BlockIterator Block::end() {
// TODO Lab 3.2 获取end迭代器
return BlockIterator(nullptr, 0, 0);
}
这里的tranc_id同样可以暂时忽略, 但对应类实例的值还是要在构造函数中初始化的。
5 测试
测试代码在test/test_block.cpp中, 你在完成上述组件实现后的测试结果预期为:
✗ xmake
✗ xmake run test_block
[==========] Running 10 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 10 tests from BlockTest
[ RUN ] BlockTest.DecodeTest
[ OK ] BlockTest.DecodeTest (0 ms)
[ RUN ] BlockTest.EncodeTest
[ OK ] BlockTest.EncodeTest (0 ms)
[ RUN ] BlockTest.BinarySearchTest
[ OK ] BlockTest.BinarySearchTest (0 ms)
[ RUN ] BlockTest.EdgeCasesTest
[ OK ] BlockTest.EdgeCasesTest (0 ms)
[ RUN ] BlockTest.LargeDataTest
[ OK ] BlockTest.LargeDataTest (0 ms)
[ RUN ] BlockTest.ErrorHandlingTest
[ OK ] BlockTest.ErrorHandlingTest (1 ms)
[ RUN ] BlockTest.IteratorTest
[ OK ] BlockTest.IteratorTest (0 ms)
[ RUN ] BlockTest.PredicateTest
test/test_block.cpp:277: Failure
Value of: result.has_value()
Actual: false
Expected: true
unknown file: Failure
C++ exception with description "bad optional access" thrown in the test body.
PredicateTest需要你在完成下一小节的任务后, 才能通过。
现在你可以开启下一节的范围查询
Lab 3.3 范围查询
1 范围查询函数
鉴于你之前已经在Skiplist组件和MemTable组件中实现了range_query功能, 这里我们需要再Blcok组件中再次实现range_query功能。(同样, 查询是单调的), 只不过这里操作的基础数据从内存中的跳表变成了类似数组结构的Block。
你需要修改的文件:
src/block/block.cppinclude/block/block.h(Optional)
1.1 前缀查询
具体修改的函数为:
std::optional<
std::pair<std::shared_ptr<BlockIterator>, std::shared_ptr<BlockIterator>>>
Block::iters_preffix(uint64_t tranc_id, const std::string &preffix) {
// TODO Lab 3.2 获取前缀匹配的区间迭代器
return std::nullopt;
}
这里返回一对迭代器,标识前缀匹配的区间。(同样是和STL风格一致的左闭右开区间), 如果查询不到, 返回std::nullopt。
std::optional是一个智能指针, 其用法非常类似Rust的Option
1.2 谓词查询
具体修改的函数为:
// 返回第一个满足谓词的位置和最后一个满足谓词的位置
// 如果不存在, 范围nullptr
// 谓词作用于key, 且保证满足谓词的结果只在一段连续的区间内, 例如前缀匹配的谓词
// 返回的区间是闭区间, 开区间需要手动对返回值自增
// predicate返回值:
// 0: 满足谓词
// >0: 不满足谓词, 需要向右移动
// <0: 不满足谓词, 需要向左移动
std::optional<
std::pair<std::shared_ptr<BlockIterator>, std::shared_ptr<BlockIterator>>>
Block::get_monotony_predicate_iters(
uint64_t tranc_id, std::function<int(const std::string &)> predicate) {
// TODO: Lab 3.2 使用二分查找获取满足谓词的区间迭代器
return std::nullopt;
}
这里返回一对迭代器,标识谓词查询的区间。(同样是和STL风格一致的左闭右开区间), 如果查询不到, 返回std::nullopt。
2 测试
如下运行测试, 预期结果为:
✗ xmake
✗ xmake run test_block
[==========] Running 10 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 10 tests from BlockTest
[ RUN ] BlockTest.DecodeTest
[ OK ] BlockTest.DecodeTest (0 ms)
[ RUN ] BlockTest.EncodeTest
[ OK ] BlockTest.EncodeTest (0 ms)
[ RUN ] BlockTest.BinarySearchTest
[ OK ] BlockTest.BinarySearchTest (0 ms)
[ RUN ] BlockTest.EdgeCasesTest
[ OK ] BlockTest.EdgeCasesTest (0 ms)
[ RUN ] BlockTest.LargeDataTest
[ OK ] BlockTest.LargeDataTest (0 ms)
[ RUN ] BlockTest.ErrorHandlingTest
[ OK ] BlockTest.ErrorHandlingTest (1 ms)
[ RUN ] BlockTest.IteratorTest
[ OK ] BlockTest.IteratorTest (0 ms)
[ RUN ] BlockTest.PredicateTest
[ OK ] BlockTest.PredicateTest (2 ms) # 到这里成功就表示你完成了本`Lab`
[ RUN ] BlockTest.TrancIteratorTest
[ OK ] BlockTest.TrancIteratorTest (0 ms)
[ RUN ] BlockTest.TrancPredicateTest
[ OK ] BlockTest.TrancPredicateTest (0 ms)
[----------] 10 tests from BlockTest (4 ms total)
[----------] Global test environment tear-down
[==========] 10 tests from 1 test suite ran. (4 ms total)
[ PASSED ] 10 tests.
其中最后两个测试BlockTest.TrancIteratorTest和BlockTest.TrancPredicateTest需要后续实现事务功能后才能正常通过。只要你通过了BlockTest.PredicateTest前的测试, 即视为完成了本Lab。
阶段2-SST
在完成了Block组件和BlockIterator组件之后, 我们就可以开始实现SST组件了。
SST组件的核心工作就是管理器内部的多个Block组件, 利用Block组件和BlockIterator的各种CRUD和初始化、构建等基本接口,来对外提供各类功能。
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
Lab 3.4 BlockMeta
1 概述
让我们再次回顾SST的结构:
可以看到, SST中有一个Meta Section, 它是一个数组, 数组中的每一个元素对应一个Block的元信息, 这些元信息包括:
- 该
Block在SST中的偏移量 - 该
Block的第一个key和最后一个key的元数据
在SST构建完成后, 其文件持久化在文件系统中, 但Meta Section会被加载到内存中并解码为控制结构, 因为没有Meta Section的元数据, 我们是没法对SST按照Block进行索引的。在Tiny-LSM中, 这里的元数据在内存中用类BlockMeta来表示, 其定义为:
class BlockMeta {
friend class BlockMetaTest;
public:
size_t offset; // 块在文件中的偏移量
std::string first_key; // 块的第一个key
std::string last_key; // 块的最后一个key
static void encode_meta_to_slice(std::vector<BlockMeta> &meta_entries,
std::vector<uint8_t> &metadata);
static std::vector<BlockMeta>
decode_meta_from_slice(const std::vector<uint8_t> &metadata);
BlockMeta();
BlockMeta(size_t offset, const std::string &first_key,
const std::string &last_key);
};
这里的每一个BlockMeta对应一个Block的元数据, 包含了我们之前介绍的编码方式的基础数据结构。
2 代码实现
你需要修改的代码文件为:
src/block/blockmeta.cppinclude/block/blockmeta.h(Optional)
2.1 编码函数
你需要实现将内存中的元信息编码到二进制数组的函数:
void BlockMeta::encode_meta_to_slice(std::vector<BlockMeta> &meta_entries,
std::vector<uint8_t> &metadata) {
// TODO: Lab 3.4 将内存中所有`Blcok`的元数据编码为二进制字节数组
// ? 输入输出都由参数中的引用给定, 你不需要自己创建`vector`
}
2.2 解码函数
你需要实现将二进制数组解码到内存中的函数:
std::vector<BlockMeta>
BlockMeta::decode_meta_from_slice(const std::vector<uint8_t> &metadata) {
// TODO: Lab 3.4 将二进制字节数组解码为内存中的`Blcok`元数据
return {};
}
这里的编码解码都是以代表整个
SST元信息的vector数组进行的, 上层组件并不要求你实现单个Block的编解码函数, 但需要你可以选择实现单个Block的编解码函数作为辅助函数
3 测试
测试代码在test/test_blockmeta.cpp中, 正常情况下, 完成本小节Lab后你应该可以通过所有的测试:
✗ xmake
✗ xmake run test_blockmeta
[==========] Running 6 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 6 tests from BlockMetaTest
[ RUN ] BlockMetaTest.BasicEncodeDecodeTest
[ OK ] BlockMetaTest.BasicEncodeDecodeTest (0 ms)
[ RUN ] BlockMetaTest.EmptyMetaTest
[ OK ] BlockMetaTest.EmptyMetaTest (0 ms)
[ RUN ] BlockMetaTest.SpecialCharTest
[ OK ] BlockMetaTest.SpecialCharTest (0 ms)
[ RUN ] BlockMetaTest.ErrorHandlingTest
[ OK ] BlockMetaTest.ErrorHandlingTest (0 ms)
[ RUN ] BlockMetaTest.LargeDataTest
[ OK ] BlockMetaTest.LargeDataTest (0 ms)
[ RUN ] BlockMetaTest.OrderTest
[ OK ] BlockMetaTest.OrderTest (0 ms)
[----------] 6 tests from BlockMetaTest (0 ms total)
[----------] Global test environment tear-down
[==========] 6 tests from 1 test suite ran. (1 ms total)
[ PASSED ] 6 tests.
4 思考
我们实现了Block类的元信息BlcokMeta, 现在可以思考一下, BlcokMeta如何被上层使用? 其如何加速查询?
Lab 3.5 SSTBuilder
1 概述
SSTBuilder是SST文件的构造器, 它将MemTable中的数据进行编码并写入磁盘形成SST。不过这里我们并没有设计到不同组件数据的控制,这是由更上层的结构控制的。
SST和SSTBuilder的关系是什么?
区别在于,SSTBuilder这个类的实例只在SST文件构建过程中存在, 其是可写的数据结构, 构建过程可不断添加键值对进行编码。在其调用Build后,其会将自身数据编码为SST文件, 并转化为一个SST类实例, SST类本质上就是SST文件的控制结构。
这样说起来可能不好理解, 让我们结合代码将这个过程具体化, 先看其SSTBuilder和SST的头文件定义:
class SST : public std::enable_shared_from_this<SST> {
// ...
private:
FileObj file;
std::vector<BlockMeta> meta_entries;
uint32_t bloom_offset;
uint32_t meta_block_offset;
size_t sst_id;
std::string first_key;
std::string last_key;
std::shared_ptr<BloomFilter> bloom_filter;
std::shared_ptr<BlockCache> block_cache;
uint64_t min_tranc_id_ = UINT64_MAX;
uint64_t max_tranc_id_ = 0;
public:
// ...
};
class SSTBuilder {
private:
Block block;
std::string first_key;
std::string last_key;
std::vector<BlockMeta> meta_entries;
std::vector<uint8_t> data;
size_t block_size;
std::shared_ptr<BloomFilter> bloom_filter; // 后续Lab内容
uint64_t min_tranc_id_ = UINT64_MAX; // 后续Lab内容
uint64_t max_tranc_id_ = 0; // 后续Lab内容
// WiscKey 键值分离字段(后续Lab内容)
uint8_t storage_mode_ = 0; // 0=inline, 1=WiscKey
std::shared_ptr<VLog> vlog_;
size_t wisckey_threshold_ = 0;
public:
// 创建一个sst构建器, 指定目标block的大小(普通模式)
SSTBuilder(size_t block_size, bool has_bloom);
// WiscKey 模式:value 超过阈值时写入 vlog,SST 中只存引用(后续Lab内容)
SSTBuilder(size_t block_size, bool has_bloom,
std::shared_ptr<VLog> vlog, size_t wisckey_threshold);
// 添加一个key-value对
void add(const std::string &key, const std::string &value, uint64_t tranc_id);
// 完成当前block的构建, 即将block写入data, 并创建新的block
void finish_block();
// 构建sst, 将sst写入文件并返回SST描述类
std::shared_ptr<SST> build(size_t sst_id, const std::string &path,
std::shared_ptr<BlockCache> block_cache);
};
构建流程
- 当
MemTable的大小超过阈值后,准备将MemTable中最旧的Frozen Table刷出为SST。 - 先创建一个
SSTBuilder, 按照迭代器的顺序遍历Frozen Table,将key-value对添加到SSTBuilder中:SSTBuilder会有一个当前的block, 其add函数首先会调用Block::add_entry将迭代器的kv对插入- 如果当前的
block容量超出阈值block_size, 就调用finish_block将其编码到data, 并清楚当前block相关数据, 开启下一个block的构建 - 遍历完成迭代器的所有
kv对的插入后, 调用build将所有的数据刷到文件系统, 并返回一个SST描述类
读取流程
SST构造函数会绑定一个文件描述符(这里是我自定义封装的文件读取类FileObj file)SST中的meta entries从第一次读取后就常驻内存(第一次读取可以是构造函数, 也可以是第一次get)- 上层调用
get时, 会从元数据meta_entries中进行二分查找, 找到对应的block的偏移量, 然后调用文件描述对象file从磁盘中读取 - 读取后的字节流交由
Block::decode解码得到内存中的Block - 内存中的
Block调用之前实现的查询函数完成二分查询
2 代码实现
2.1 SSTBuilder::add 函数
Hint: 建议你先看完下一个
finish_block函数的描述后再开始写代码, 因为这个函数中需要使用finish_block函数
SSTBuilder中的block成员变量即为当前正在构建的Block, add函数不断接受上部组件传递的键值对, 并将键值对添加到当前正在构建的Block中, 当Block容量达到阈值时, 将Block写入data数组, 并创建一个新的Block继续构建。
构建结束后,这个data数组就包含了多个Block的编码字节, 经进一步处理后即可刷盘形成SST:
void SSTBuilder::add(const std::string &key, const std::string &value,
uint64_t tranc_id) {
// TODO: Lab 3.5 添加键值对
}
这里的一些阈值参数你同样可以采取
TomlConfig::getInstance().getxxx()的方法获取配置文件config.toml中定义的常量
2.2 SSTBuilder::finish_block 函数
根据前文介绍可知, SSTBuilder只有一个活跃的block支持插入键值对进行构建, 超出阈值后其将会编码为Block并写入data数组, 这个过程就是SSTBuilder::finish_block函数的功能:
void SSTBuilder::finish_block() {
// TODO: Lab 3.5 构建块
// ? 当 add 函数发现当前的`block`容量超出阈值时,需要将其编码到`data`,并清空`block`
}
2.3 SSTBuilder::build 函数
当上层组件已经将所有键值对插入到SSTBuilder中后,调用SSTBuilder::build函数即可完成SST文件的构建, 其会返回一个SST指针:
std::shared_ptr<SST>
SSTBuilder::build(size_t sst_id, const std::string &path,
std::shared_ptr<BlockCache> block_cache) {
// TODO 3.5 构建一个SST
return nullptr;
}
参数列表中, sst_id表示SST的编号, path表示SST文件的存储路径, block_cache表示Block的缓存池。你相比也意识到, 当SST从内存持久化为文件后, 其IO必然收到缓存池的管理, 这也是我们之后的内容, 这里你也不需要考虑缓存池的指针, 当它为nullptr即可
这里涉及到文件IO的操作, 作者已经在
include/utils中封装了一个文件IO管理类FileObj, 你需要阅读include/utils/files.h即src/utils/files.cpp来了解其使用方法
3 测试
到目前位置, 我们只是实现了SST的构建工具类SSTBuilder, 但由于我们很没有实现SST的查询功能, 所以现在我们还无法通过查询接口验证我们SST构建的正确性, 因此单元测试需要完成后续SST相关Lab才能实现。
Lab 3.6 SST 查询
1 概述
首先, 需要声明, 这一小节的实验容量稍大, 你将同时实现SST的基础查询功能和迭代器SstIterator。
为什么需要这样设计呢?答案是因为,我们对组件的查询设计沿用了STL的迭代器风格,查询都是返回迭代器作为结果的。但我们的思路首先应该是实现SST本身, 后续再实现迭代器SstIterator。但STL风格的接口设计导致二者耦合了,因此,这里索性将二者同时实现了。
1.1 SST 的定义
同样,我们先看SST的定义:
class SST : public std::enable_shared_from_this<SST> {
private:
FileObj file;
std::vector<BlockMeta> meta_entries;
uint32_t bloom_offset; // 暂时忽略
uint32_t meta_block_offset;
size_t sst_id;
std::string first_key;
std::string last_key;
std::shared_ptr<BloomFilter> bloom_filter; // 暂时忽略
std::shared_ptr<BlockCache> block_cache; // 暂时忽略
uint64_t min_tranc_id_ = UINT64_MAX; // 暂时忽略
uint64_t max_tranc_id_ = 0; // 暂时忽略
// WiscKey 键值分离字段(后续Lab内容,暂时忽略)
uint8_t storage_mode_ = 0; // 0=inline, 1=WiscKey
std::shared_ptr<VLog> vlog_;
// ...
};
SST最关键的成员变量是meta_entries, 其本质上就是从硬盘中读取了SST文件的Meta Section部分解析后的BlockMeta数组。在接受外部查询请求时, 我们会根据key在meta_entries中查找对应的BlockMeta, 然后从硬盘中读取Block并解码得到内存中的Block, 最后再调用Block的查询接口完成查询。这里的FileObj file成员变量就是实现对应的SST文件的IO操作的类实例。
当然, 如果你完成了后续
Lab, 这里的逻辑存在一些不同:
- 如果后续实现了缓存池, 就可以从缓存池中查询
Block, 而不是从硬盘中读取。- 如果后续实现了
BloomFilter, 那么在查询时, 首先会通过BloomFilter判断key是否有存在的可能, 如果不可能存在, 则直接返回nullptr, 否则继续调用查询接口完成查询。
1.2 SstIterator 的定义
然后是SstIterator的定义:
class SstIterator : public BaseIterator {
// friend xxx
private:
std::shared_ptr<SST> m_sst;
size_t m_block_idx;
uint64_t max_tranc_id_;
std::shared_ptr<BlockIterator> m_block_it;
mutable std::optional<value_type> cached_value; // 缓存当前值
// ...
};
要实现SST的迭代器, 需要记录当前的Block索引, 以及Block中的Entry索引, 因此也需要原SST类的this指针, 之前已经介绍过enable_shared_from_this了, 不再赘述。
这里使用m_sst, m_block_idx和m_block_it分别记录原始的SST类对象、当前Block在SST中的位置、当前迭代器在Block中的位置。cached_value仍然用做缓存值, 因为读取键值对涉及文件IO操作, 因此这里的cached_value就不仅仅是为了实现->的辅助成员变量了, 而是正儿八经的优化手段。
本小节Lab中, 你需要修改的代码文件:
- 实现
SST需要修改的文件src/sst/sst.cppinclude/sst/sst.h(Optional)
- 实现
SstIterator需要修改的文件src/sst/sst_iterator.cppinclude/sst/sst_iterator.h(Optional)
2 SST 基础代码实现
2.1 打开 SST 文件
你需要实现SST::open函数:
// 头文件中将其定义为静态函数
// vlog 参数默认为 nullptr,普通模式下忽略即可;WiscKey 模式下由上层传入(后续Lab内容)
std::shared_ptr<SST> SST::open(size_t sst_id, FileObj file,
std::shared_ptr<BlockCache> block_cache,
std::shared_ptr<VLog> vlog = nullptr) {
// TODO Lab 3.6 打开一个SST文件, 返回一个描述类
return nullptr;
}
尽管我们的SST对数据的查询是惰性地从文件系统中进行读取, 但必要的元信息需要我们加载到内存中。SST::open的工就是将SST文件的元信息进行解码和加载,返回一个描述类SST, 你可以将SST看做是SST文件的操作句柄,或者是文件描述符。
- 如果你后续
Lab实现了布隆过滤器, 那么布隆过滤器的bit数组也需要加载到内存中block_cache是缓存池的指针, 你现在不需要管它是哪里来的, 只需要对类的成员变量进行简单赋值即可
2.2 加载 Block
在接受其他组件的查询请求后, SST会根据元信息定位请求的key可能位于哪一个Block(因为BlockMeta中存储了首尾的key), 接下来就是读取这个Blcok, 这就是你需要实现的read_block函数:
std::shared_ptr<Block> SST::read_block(int64_t block_idx) {
// TODO: Lab 3.6 根据 block 的 id 读取一个 `Block`
return nullptr;
}
注意参数类型为 int64_t(有符号),这是为了与 find_block_idx 的返回值(返回 -1 表示未找到)保持一致。
实现缓存池后, 你的代码逻辑应该是
- 从缓存池获取
Block, 如果缓存命中, 直接返回。- 缓存未命中才从文件系统中读取
- 返回前别忘了更新缓存池
2.3 根据 key 查询 Block
size_t SST::find_block_idx(const std::string &key) {
// 先在布隆过滤器判断key是否存在
// TODO: Lab 3.6 二分查找
// ? 给定一个 `key`, 返回其所属的 `block` 的索引
// ? 如果没有找到包含该 `key` 的 Block,返回-1
return 0;
}
find_block_idx函数的目的是根据key在meta_entries中查找对应的BlockMeta, 返回BlockMeta在meta_entries中的索引。如果key不存在于SST中, 则返回-1。
这里由于Block的数据是有序的, 因此你需要使用二分查找算法提速, 否者你的查询性能会非常差。
3 SstIterator 代码实现
3.1 SstIterator 定位函数
你需要实现下面的迭代器定位函数:
void SstIterator::seek_first() {
// TODO: Lab 3.6 将迭代器定位到第一个key
}
void SstIterator::seek(const std::string &key) {
// TODO: Lab 3.6 将迭代器定位到指定key的位置
}
Hint 这里的逻辑也很简单, 就是先使用记录在
sst中的meta_entries找到包含要查找的key的Block(find_block_idx), 从文件中读取这个Block(read_block), 然后再读取的Block中调用获取指定key的迭代器的构造函数, 通过BlockIterator实现在Block中的定位。
SST创建迭代器时, 会在构造函数中选择是否偏移到指定的key, 你可以查看SstIterator的构造函数, 看看他们是如何与不同组件和函数见衔接的。
3.2 运算符重载函数
作为迭代器, 我们的惯例就行要实现下面几个运算符重载函数:
BaseIterator &SstIterator::operator++() {
// TODO: Lab 3.6 实现迭代器自增
return *this;
}
bool SstIterator::operator==(const BaseIterator &other) const {
// TODO: Lab 3.6 实现迭代器比较
return false;
}
bool SstIterator::operator!=(const BaseIterator &other) const {
// TODO: Lab 3.6 实现迭代器比较
return false;
}
SstIterator::value_type SstIterator::operator*() const {
// TODO: Lab 3.6 实现迭代器解引用
return {};
}
4 补全 SST
在实现了SstIterator后, 你可以补全以SST中以SstIterator作为返回值的几个函数:
SstIterator SST::get(const std::string &key, uint64_t tranc_id) {
// TODO: Lab 3.6 根据查询`key`返回一个迭代器
// ? 如果`key`不存在, 返回一个无效的迭代器即可
throw std::runtime_error("Not implemented");
}
// keep_all_versions=false 时只保留每个 key 的最新版本(事务可见版本)
// keep_all_versions=true 时用于 compact,保留全部历史版本
SstIterator SST::begin(uint64_t tranc_id, bool keep_all_versions = false) {
// TODO: Lab 3.6 返回起始位置迭代器
throw std::runtime_error("Not implemented");
}
SstIterator SST::end() {
// TODO: Lab 3.6 返回终止位置迭代器
throw std::runtime_error("Not implemented");
}
这几个函数都很简单, 因为具体的定位操作是在SstIterator内部完成的(虽然其反过来有调用了SST的find_block_idx等函数), 因此只需要调用SstIterator的构造函数即可。这里作为Lab的内容主要是为了让你对不同组件之间的交互有一个认真, 意思到这样一个设计思路: 迭代器是连接不同组件的桥梁.
5 测试
此次测试包含之前Lab 3.5的实现, 预期的结果是:
✗ xmake
[100%]: build ok, spent 0.517s
✗ xmake run test_sst
[==========] Running 8 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 8 tests from SSTTest
[ RUN ] SSTTest.BasicWriteAndRead
[ OK ] SSTTest.BasicWriteAndRead (3 ms)
[ RUN ] SSTTest.BlockSplitting
[ OK ] SSTTest.BlockSplitting (1 ms)
[ RUN ] SSTTest.KeySearch
[ OK ] SSTTest.KeySearch (0 ms)
[ RUN ] SSTTest.Metadata
[ OK ] SSTTest.Metadata (0 ms)
[ RUN ] SSTTest.EmptySST
[ OK ] SSTTest.EmptySST (0 ms)
[ RUN ] SSTTest.ReopenSST
[ OK ] SSTTest.ReopenSST (0 ms)
[ RUN ] SSTTest.LargeSST
[ OK ] SSTTest.LargeSST (0 ms)
[ RUN ] SSTTest.LargeSSTPredicate
test/test_sst.cpp:235: Failure
Value of: result.has_value()
Actual: false
Expected: true
unknown file: Failure
C++ exception with description "bad optional access" thrown in the test body.
[ FAILED ] SSTTest.LargeSSTPredicate (1 ms)
[----------] 8 tests from SSTTest (8 ms total)
[----------] Global test environment tear-down
[==========] 8 tests from 1 test suite ran. (8 ms total)
[ PASSED ] 7 tests.
[ FAILED ] 1 test, listed below:
[ FAILED ] SSTTest.LargeSSTPredicate
1 FAILED TEST
error: execv(/home/vanilla-beauty/proj/tiny-lsm/build/linux/x86_64/release/test_sst ) failed(1)
如果仅仅是得到一个可以跑的SST, 那么现在你已经完成的SST的大部分功能了。这里的LargeSSTPredicate需要你在实现下一小节的谓词查询后才能通过。
Lab 3.7 范围查询
1 函数功能描述
同样地,我们设计了sst_iters_monotony_predicate函数,用于范围一段连续的区间, 这个区间是单调的, 只会在整个SST中出现一次, 例如包含指定前缀的一段范围。
不过这里我们将次函数定义为静态函数, 并放置于src/sst/sst_iterator.cpp中。因为我们之前进行了模块拆分, SST和SstIterator分别定义在了src/sst/sst.cpp和src/sst/sst_iterator.cpp中,而sst_iters_monotony_predicate函数需要同时访问SST和SstIterator,因此我们需要将sst_iters_monotony_predicate定义为静态函数, 并设定为以上两个类的友元函数.
2 代码实现
你需要更改的文件:
src/sst/sst_iterator.cpp
你需要实现sst_iters_monotony_predicate函数:
// predicate返回值:
// 0: 谓词
// >0: 不满足谓词, 需要向右移动
// <0: 不满足谓词, 需要向左移动
std::optional<std::pair<SstIterator, SstIterator>> sst_iters_monotony_predicate(
std::shared_ptr<SST> sst, uint64_t tranc_id,
std::function<int(const std::string &)> predicate) {
// TODO: Lab 3.7 实现谓词查询功能
return {};
}
Hint
- 这里的实现思路肯定是调用子组件
Block的get_monotony_predicate_iters接口实现范围查询, 但你需要考虑不同Block查询结果的拼接, 即查询的目标可能跨Block分布SST中所有的Block都是有序的, 因此你在定位Block时, 也推荐使用类似二分查询的思路加快定位速度src/sst/sst_iterator.cpp中的sst_iters_monotony_predicate已经被设定为了SST和SstIterator的友元函数, 因此你可以随意访问SST和SstIterator的成员变量和函数, 这样应该可以简化你的实现
3 测试 && 阶段2 结束
现在, 你应该可以完成test_sst的所有测例:
✗ xmake
✗ xmake run test_sst
[==========] Running 8 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 8 tests from SSTTest
[ RUN ] SSTTest.BasicWriteAndRead
[ OK ] SSTTest.BasicWriteAndRead (2 ms)
[ RUN ] SSTTest.BlockSplitting
[ OK ] SSTTest.BlockSplitting (0 ms)
[ RUN ] SSTTest.KeySearch
[ OK ] SSTTest.KeySearch (0 ms)
[ RUN ] SSTTest.Metadata
[ OK ] SSTTest.Metadata (0 ms)
[ RUN ] SSTTest.EmptySST
[ OK ] SSTTest.EmptySST (0 ms)
[ RUN ] SSTTest.ReopenSST
[ OK ] SSTTest.ReopenSST (0 ms)
[ RUN ] SSTTest.LargeSST
[ OK ] SSTTest.LargeSST (0 ms)
[ RUN ] SSTTest.LargeSSTPredicate
[ OK ] SSTTest.LargeSSTPredicate (0 ms)
[----------] 8 tests from SSTTest (6 ms total)
[----------] Global test environment tear-down
[==========] 8 tests from 1 test suite ran. (6 ms total)
[ PASSED ] 8 tests.
4 思考 && 下一步?
现在你已经实现了SST的基本特性, 而剩余的SST特性还包括:
- 不同
Level的SST的压缩合并 - 缓存池和布隆过滤器的优化
- 以
Level层级为单位的迭代器(就是将一整个Level的多个SST组织成一个迭代器)
以上这些内容, 你将在Lab 4 LSM Engine中实现。因为以上的组件需要上层组件的控制,例如我们的缓存池是全局共享而非单个SST独有的, 因此需要上层组件进行初始化和分配。
Lab 4 LSM Engine
本章Lab将串联之前实现的MemTable, SST, Block, 各类Iterator, 实现一个初版的完整的单机KV存储引擎。
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
1 概述
实现了之前的Skiplist, MemTable, SST, Block, 各类Iterator之后, 我们对其进行“简单“地封装, 即可得到一份可以运行的LSM Engine。完成这一章Lab后, 你将得到一个可以被外部结构调用的共享链接库, 其暴露了各种基础的KV存储引擎接口。
同样地, 我们再一次回顾我们的架构:
可以看到, 不同组件之间存在各种交互, 这些交互内容包括:
MemTable和SST之间进行Encoded并刷盘形成SST文件- 不同
SST之间的连接(例如遍历这一层的SST的键值对) - 相邻
Level之间SST的Compact操作 Client发出Get请求到MemTable和SST组件的查询路径
这一章的Lab就是将我们之前已经实现的组件进行串联, 形成初版的LSM Tree存储引擎。
2 思考
同样地, 请先思考下面几个问题, 然后带着问题开始本章的Lab:
- 不同组件之间交互的媒介是什么? 是迭代器吗?
- 之前提到的布隆过滤器和缓存池的优化并未在架构图中给出, 他们位于哪个位置?
- 缓存池缓存的是
Blcok, 但如果SST被压缩形成新的SST文件, 缓存池中的Block将不再有效, 缓存池中的无效的Block将如何处理? - 不同
Level的SST Compact采用什么策略? 他们对Read/Write性能有什么影响? - 我们实现整个
LSM Engine的范围查询等操作时, 去重和排序逻辑和之前的组件有什么区别? - 为什么
Level 0要设计成Unsorted? 所有的Level的SST都是Sorted不好吗? - 不同组件交互过程中, 如何设计并发控制策略, 保证其性能?
- 实现上述的功能, 是不是又要设计新的迭代器?
这些问题你不一定要马上给出一个清晰的答案, 只需要有一个整体的认知和思考即可, 这样有助于你对整个项目代码设计思路的理解。
由于本实现的设计目的就是让更广大的开发者或CS专业的学生对
KV存储有初步的认真, 因此难度是被刻意降低了的, 你不需要进行架构设计层面的思考以及对应代码的编写, 只需要补全作者挖空的关键函数。因此,如果你一味地完成
Lab的代码, 却缺乏对作者给出思考题的理解, 那么你对本实验项目的理解可能是不到位的, 即你知道这么设计的代码能正常运行, 但却不知道他为什么这么设计。
阶段1-Engine 基础功能
在这一阶段中, 你将实现最基本的LSM Tree存储引擎的CRUD接口, 在之后的阶段二中你将实现性能优化部分的内容。
阶段一的内容包括:
- 数据的写入 &&
SST文件的构造 SST文件的加载 && 数据查询
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
Lab 4.1 Engine 的写入
1 概述
与之前的模块不同, LSMEngine部分我们不打算按照CRUD迭代器的顺序进行实验, 因为其Put操作包含了SST的构建流程, 而Get操作是对已经构建的SST进行查询, 因此, 本章的Lab以SST的生命周期为线索, 逐步实现Lab, 这样的设计也有助于你对上层组件运行调度机制的理解。
话不多说,我们先来看看Engine的头文件定义, 然后结合理论知识, 介绍put流程和sst的构建流程
class Level_Iterator;
class LSMEngine : public std::enable_shared_from_this<LSMEngine> {
public:
std::string data_dir;
MemTable memtable;
std::map<size_t, std::deque<size_t>> level_sst_ids;
std::unordered_map<size_t, std::shared_ptr<SST>> ssts;
std::shared_mutex ssts_mtx;
std::shared_ptr<BlockCache> block_cache;
std::shared_ptr<VLog> vlog_; // WiscKey 键值分离(后续Lab内容)
size_t next_sst_id = 0; // 下一个要分配的 sst id
size_t cur_max_level = 0; // 当前最大的 level
};
class LSM {
private:
std::shared_ptr<LSMEngine> engine;
std::shared_ptr<TranManager> tran_manager_; // 本Lab不需要关注
};
这里, 我们使用了LSM包裹了LSMEngine, LSMEngine是你要补全函数实现的类, 其中定义了memtable, level_sst_ids, ssts, block_cache, next_sst_id, cur_max_level等成员变量。这里比较重要的包括:
level_sst_ids: 从level到这一层的sst_id数组, 每一个SST由一个sst_id唯一表示ssts:sst_id到SST的映射next_sst_id:SST的id分配器,LSMEngine在flush形成行的SST时, 会分配一个sst_id给SST, 然后将sst_id和SST映射关系存入ssts中,next_sst_id就是sst_id的分配器, 每次分配sst_id时,next_sst_id都会自增1cur_max_level: 顾名思义, 就是当前SST的最大的leveldata_dir:LSMEngine的data_dir, 即数据文件的存储位置, 这个参数我们在单元测试中会进行指定,SST文件需要存放在这个目录下MemTable: 即整个LSM Tree引擎的内存表部分
剩下的成员变量:
ssts_mtx: 全局的sst文件的访问锁, 这里是一个读写锁, 当然这个变量不是必须的, 你可以按照自己的理解实现并发控制策略(不过建议使用这个变量)block_cache: 全局的缓存池指针, 你实现缓存池之前, 默认其为nullptr即可
这里的
l0_sst_ids记录了所有sst的id, 其排序是从大到小, 因为sst的id越大表示这个sst越新, 需要优先查询。可以使用
l0_sst_ids获取的id从哈希表ssts中查询SST的描述类(类似于文件描述符)。
2 写入/删除流程
结合刚刚对类的成员变量定义的简单介绍, 我们再次回顾一下LSM Tree的读写流程:
- 写入
MemTable:- 如果写入的
KV的value为空, 表示一个删除标记 - 直接调用成员变量
memtable的接口即可 - 同样有批量接口和单次操作的接口
- 如果写入的
- 若当前活跃的
MemTable大小达到阈值, 则将其冻结- 这一部分已经在
MemTable中实现, 你无需再实现
- 这一部分已经在
- 若冻结的
MemTable容量达到阈值, 则将最早冻结的MemTable转为SST- 判断
MemTable容量并决定是否刷盘是你需要在本小节Lab进行实现的内容之一 SST文件的设计是每一层的SST文件数量不能超过指定阈值, 因此你刷盘的Level 0的SST文件可能会哦触发Level 0和Level 1的SST文件的compact, 不过这一任务没有放在Lab 4.1,Lab4.1中你当做就只有Level 0这一个层级即可
- 判断
因此, 本小节Lab的核心就是整合之前创建的MemTable, SST, Block, Iterator, 并调用接口实现对外服务的功能
3 代码实现
本小节你需要更改的代码文件为:
src/lsm/engine.cppinclude/lsm/engine.h
3.1 Put && Remove
你首先需要实现put函数, put函数肯定是操纵memtable成员变量, 另外你也需要根据其容量接口函数判断什么时候需要进行flush操作:
uint64_t LSMEngine::put(const std::string &key, const std::string &value,
uint64_t tranc_id) {
// TODO: Lab 4.1 插入
// ? 由于 put 操作可能触发 flush
// ? 如果触发了 flush 则返回新刷盘的 sst 的 id
// ? 在没有实现 flush 的情况下,你返回 0即可
return 0;
}
uint64_t LSMEngine::remove(const std::string &key, uint64_t tranc_id) {
// TODO: Lab 4.1 删除
// ? 在 LSM 中,删除实际上是插入一个空值
// ? 由于 put 操作可能触发 flush
// ? 如果触发了 flush 则返回新刷盘的 sst 的 id
// ? 在没有实现 flush 的情况下,你返回 0即可
return 0;
}
这个函数的最终版本需要调用flush进行刷盘, 因此建议你将次函数和后面的flush函数一起实现。
此时你仍然可以忽略tranc_id, 将其传递到接口的参数即可。至于返回值uint64_t, 你现阶段返回0即可。
额外说明, 这里说明一下为什么返回值是
uint64_t,而不是void, 这主要是为后续的事务准备的, 刷盘意味着事务操作的持久化完成, 因此需要更新已经成功持久化的最大事务id, 也就是这里的返回值。如果你现在看不懂也没关系, 到实现事务的Lab就明白了。
根据之前部分描述, 此时你可以简化刷盘部分的逻辑, 即默认现在只有Level 0的SST文件, SST文件不会进行Compact形成新的Level
3.2 put_batch && remove_batch
和put/remove函数的逻辑几乎一样, 只是写入时是批量数据:
uint64_t LSMEngine::put_batch(
const std::vector<std::pair<std::string, std::string>> &kvs,
uint64_t tranc_id) {
// TODO: Lab 4.1 批量插入
// ? 由于 put 操作可能触发 flush
// ? 如果触发了 flush 则返回新刷盘的 sst 的 id
// ? 在没有实现 flush 的情况下,你返回 0即可
return 0;
}
uint64_t LSMEngine::remove_batch(const std::vector<std::string> &keys,
uint64_t tranc_id) {
// TODO: Lab 4.1 批量删除
// ? 在 LSM 中,删除实际上是插入一个空值
// ? 由于 put 操作可能触发 flush
// ? 如果触发了 flush 则返回新刷盘的 sst 的 id
// ? 在没有实现 flush 的情况下,你返回 0即可
return 0;
}
3.3 Flush
flush函数会将MemTable中frozen_tables中最旧的一个跳表的数据刷盘,并返回刷盘过程中提取的统计信息tranc_id, 现阶段你只需要返回0即可。
Hint:
flush()的返回值是和put()等接口的返回值一致的
uint64_t LSMEngine::flush() {
// TODO: Lab 4.1 刷盘形成sst文件
return 0;
}
flush函数应该是这一小节的关键函数了, 这里的逻辑就是从memtable的接口将最旧的跳表刷盘成SST文件, 这里涉及到文件IO的操作时, 推荐使用作者定义好的辅助类FileObj, 其定义在include/utils/files.h中。
构造 SSTBuilder 时的注意事项
现阶段你只需要使用普通模式的构造函数:
SSTBuilder builder(TomlConfig::getInstance().getLsmBlockSize(), true);
vlog_ 和 WiscKey 相关逻辑是后续 Lab(键值分离)的内容,现阶段无需关注。
最后,SST文件的命名格式已经在get_sst_path中进行了详细的说明:
std::string LSMEngine::get_sst_path(size_t sst_id, size_t target_level) {
// sst的文件路径格式为: data_dir/sst_<sst_id>.<level>,sst_id格式化为32位数字
std::stringstream ss;
ss << data_dir << "/sst_" << std::setfill('0') << std::setw(32) << sst_id
<< '.' << target_level;
return ss.str();
}
后缀标记了这个
SST文件所属的Level, 在你实现Compact前, 这个后缀设置为0即可
你必须严格遵守SST文件格式的命名规范, 如果你采用自己的文件命名方式, 那么请自行修改对应的单元测试函数(非常不推荐)。
4 测试
由于我们目前仅实现了写入模块, 测试函数无法从引擎读取数据, 因此本小节没有单元测试, 当你实现Lab 4.2 Engine 的读取后会进行统一的单元测试。
5 思考
现在请先思考一下几个问题,然后开启Lab 4.2 Engine 的读取
Lab 4.2 Engine 的读取
1 概述
从之前 Lab 4.1 Engine 的写入中, 我们已经实现了SST的构建流程, 这一章我们将实现Engine的读取流程。(这里的读取还包括引擎的初始化流程中对SST文件的读取)
同样地, 我们想从逻辑上梳理引擎的读取和查询流程:
1 存储引擎启动时
遍历data_dir下的SST文件, 将SST文件的元信息加载到内存中
2 接受查询请求
- 查询当前活跃的
MemTable, 如果查到有效记录或删除记录, 则返回 - 若查询当前活跃的
MemTable未命中, 则遍历冻结的MemTable, 由于冻结的MemTable也存在次序, 需要先查询最近冻结的MemTable - 若查询冻结的
MemTable未命中, 则遍历SST, 由于SST也存在次序, 需要先查询最近创建的SSTSST的顺序先按照Level排序,Level越低的SST越新, 需要先查询- 相同
Level的SST按照sst_id排序, 这里的逻辑有所不同:- 如果是
Level 0的SST, 则按照sst_id排序, 从大到小查询, 越大的sst_id表示这个SST越新, 需要有限查询 - 如果是其他
Level以上的SST, 其所有的SST的key都是有序分布且不重叠的, 既然key不重叠也就无所谓谁的优先级更高、谁会覆盖谁的key, 可以采用二分查询实现更高的效率, 下面是一个SST文件的案例:Level 0: sst_15(key000-key050), sst_14(key005-key030), sst_13(key020-key040) Level 1: sst_10(key100-key120), sst_11(key121-key140), sst_12(key141-key160) Level 2: sst_08(key100-key120), sst_09(key121-key140)
- 如果是
- 整个
SST文件遍历完成后, 若仍未命中, 则返回空指针表示key没有找到
补充
- 在后续实现
WAL后, 在上述所有流程前, 会有一个对WAL日志进行检查并实现崩溃恢复的流程
2 代码实现
本小节你需要更改的代码文件为:
src/lsm/engine.cppinclude/lsm/engine.h
2.1 引擎的初始化
上一章Lab 4.1 Engine 的写入中, 我们在put操作中惰性触发了SST的刷盘操作, 因此在Engine启动时, 我们需要遍历data_dir下的SST文件, 将SST文件的元信息加载到内存中, 以便后续的查询操作:
LSMEngine::LSMEngine(std::string path) : data_dir(path) {
// 初始化日志
init_spdlog_file();
// TODO: Lab 4.2 引擎初始化
}
说明
- 后续实现缓存池后, 构造函数中需要对缓存池进行初始化, 现阶段你的构造函数, 只需要将
block_cache初始化为nullptr即可 - 第一次启动引擎时, 需要创建数据目录
init_spdlog_file函数用于初始化日志, 其内部是对std::call_once的封装, 因此其只有第一次调用时会执行- 引擎初始化时需要初始化
vlog_:vlog_ = VLog::open(data_dir + "/vlog.data");VLog是 WiscKey 键值分离的核心组件(后续Lab内容),这里必须在引擎初始化时打开,即使 WiscKey 阈值为 0,也能保证文件存在、正常重启读取。 - 加载 SST 文件时,需将
vlog_传入SST::open:
对于普通模式(非 WiscKey)的 SST,auto sst = SST::open(sst_id, FileObj::open(sst_path, false), block_cache, vlog_);vlog_不会被使用,传入后忽略即可。
Hint
- 你需要从
SST文件的命名格式中对next_sst_id和cur_max_level进行更新level_sst_ids映射的数组需要你自己维护其优先级顺序, 不同Level的SST文件优先级可能不同, 现在你不需要关心Level 0以外的SST
2.2 查询接口
2.2.1 get
std::optional<std::pair<std::string, uint64_t>>
LSMEngine::get(const std::string &key, uint64_t tranc_id) {
// TODO: Lab 4.2 查询
return std::nullopt;
}
这里传入的uint64_t tranc_id是为了在实现事务功能后控制不同事务的可见性的, 也就是实现事务基础属性中的隔离性, 现阶段你可以忽略它
此外, 这里的返回值是一个由optional包裹的pair, pair的第一个元素是value, 第二个元素是tranc_id, value表示查询到的值, tranc_id表示这个键值对最新的修改事务的的tranc_id(现阶段同样可以忽略), 如果查询不到, 则返回std::nullopt
2.2.2 get_batch
std::vector<
std::pair<std::string, std::optional<std::pair<std::string, uint64_t>>>>
LSMEngine::get_batch(const std::vector<std::string> &keys, uint64_t tranc_id) {
// TODO: Lab 4.2 批量查询
return {};
}
没啥好说的, 就是在get的基础上变成了批量查询
2.2.3 sst_get_
通过后缀你可以看出, 这个查询是专门在SST中进行查询的接口, 其_表示这个函数是不需要进行加锁操作的, 其加锁逻辑是其他上层组件控制的:
std::optional<std::pair<std::string, uint64_t>>
LSMEngine::sst_get_(const std::string &key, uint64_t tranc_id) {
// TODO: Lab 4.2 sst 内部查询
return std::nullopt;
}
思考: 什么情况下会单独对
SST部分进行查询?
3 测试
完成Lab 4.1 Engine 的写入和本节Lab后, 你应该能通过test/test_lsm.cpp中IteratorOperations前的所有单元测试:
✗ xmake
[100%]: build ok, spent 1.936s
✗ xmake run test_lsm
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from LSMTest
[ RUN ] LSMTest.BasicOperations
[ OK ] LSMTest.BasicOperations (0 ms)
[ RUN ] LSMTest.Persistence
[ OK ] LSMTest.Persistence (228 ms)
[ RUN ] LSMTest.LargeScaleOperations
[ OK ] LSMTest.LargeScaleOperations (1 ms)
[ RUN ] LSMTest.MixedOperations
[ OK ] LSMTest.MixedOperations (0 ms)
[ RUN ] LSMTest.IteratorOperations
unknown file: Failure
C++ exception with description "Not implemented" thrown in the test body.
[ FAILED ] LSMTest.IteratorOperations (0 ms)
阶段2-迭代器 && Compact
子任务1-迭代器
之前你已经完成了具备初步的简单CURD操作的LSM Tree存储引擎, 但你应该发现了, 诸如范围查询、全局迭代器等功能,我们并没有放在 第一阶段, 这是因为以上接口都需要不同组件之间(不同Level的SST和MemTable)进行交互, 而这些组件之间的交互需要我们实现更高级的迭代器才可以完成, 因此这一小节你将实现各种迭代器。
你需要实现的迭代器包括:
TwoMergeIterator- 其主要用于整合2个迭代器, 按照不同的优先级顺序对迭代器进行遍历
- 这里的两个迭代器通常情况下就是内存
MemTable的迭代器和SST部分的迭代器, 前者优先级更高
ConcactIterator- 用于连接某一层
Level的多个SST - 此处默认多个
SST是不重叠且排序的, 因此使用于Level > 0的SST的连接
- 用于连接某一层
LevelIterator- 类似
TwoMergeIterator, 但整合的迭代器数量更多 - 例如, 每个
Level都有一个层间的迭代器
- 类似
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
思考
为什么我们要在实现Compact之前先实现这些迭代器?
子任务2-Compact
这里的Compact操作需要我们的迭代器作为信息交互的接口, 具体原因请参见Lab 4.3 ConcactIterator
Lab 4.3 ConcactIterator
1 概述
其实这一章出现在这里是有一点突兀的, 照理说我们正常实现基础LSMEngine的下一个步骤是Compact。讲到这里我们接得知道Compact的逻辑了。
这里用一个具体案例进行讲解。
我们假设此时的SST状态是这样的:
Level 0: sst_15(key000-key050), sst_14(key005-key030), sst_13(key020-key040)
Level 1: sst_10(key100-key120), sst_11(key121-key140), sst_12(key141-key160)
Level 2: sst_08(key100-key120), sst_09(key121-key140)
我们对每一层的SST需要进行限制, 当这一层的SST数量超过阈值时, 我们需要将这一层所有的SST进行Compact到下一层。
在这个案例中, 我们下一次flush刷盘后, 假设得到了一个Level 0的SST为sst_16(key060-key080), 那么此时Level 0的SST数量超过了阈值4(这个是是假定的, 实际上是可在config.toml中配置的), 我们需要将Level 0的SST进行sst_16, sst_15, sst_14, sst_13到Level 1。但我们新Compact的SST会和Level 1本来的SST的key存在范围重叠, 这是不允许的, 所以实际上, 我们是将原来的Level 0和旧的Level 1的所有SST一并进行重新整理Compact形成新的Level 1 SST, 这里实际上就是用迭代器将2个Level的迭代器进行串联, 遍历这个迭代器, 逐一构建新的Level 1的SST, 那么是怎么个串联法呢?
- 首先,
Level 0的SST之间存在key的重叠, 需要进行去重, 这里我们可以复用已有的HeapIterator, 见Lab 2.2 迭代器 - 其次就是我们将要实现的
ConcactIterator, 这个迭代器会串联Level 1的所有SST形成层间迭代器 - 最后就是之后小节实现的
TwoMergeIterator, 这个迭代器会串联HeapIterator和ConcactIterator, 按照优先级对迭代器进行输出, 遍历TwoMergeIterator即可构建新的Level 1的SST
Question
如果
Compact发生的Level不是Level 0和Level 1, 而是Level x和Level y(x>0)呢?答案显而易见, 还是用
TwoMergeIterator对2个Level的层间迭代器进行遍历, 遍历过程中构造新的Level y的SST。只是TwoMergeIterator中包裹的Level x的迭代器从HeapIterator变成了ConcactIterator。
这一小节我们先实现ConcactIterator。
2 代码实现
你需要修改的文件:
src/sst/concact_iterator.cppinclude/sst/concact_iterator.h(Optional)
2.1 头文件分析
按照惯例, 我们简单分析下头文件定义:
class ConcactIterator : public BaseIterator {
private:
SstIterator cur_iter;
size_t cur_idx; // 不是真实的sst_id, 而是在需要连接的sst数组中的索引
std::vector<std::shared_ptr<SST>> ssts;
uint64_t max_tranc_id_;
};
这里的ssts就是这一层所有SST句柄的数组, cur_idx是当前迭代器指向的SST在ssts中的索引, cur_iter是当前cur_idx指向的SST的迭代器。
max_tranc_id_是调用这个迭代器的事务id, 也就是其最大的事务可见范围, 现在你不需要实现。
2.2 ConcactIterator 实现
这一章由于我们先介绍了Compact过程中的逻辑, 因此就先实现最简单的一个ConcactIterator:
BaseIterator &ConcactIterator::operator++() {
// TODO: Lab 4.3 自增运算符重载
return *this;
}
bool ConcactIterator::operator==(const BaseIterator &other) const {
// TODO: Lab 4.3 比较运算符重载
return false;
}
bool ConcactIterator::operator!=(const BaseIterator &other) const {
// TODO: Lab 4.3 比较运算符重载
return false;
}
ConcactIterator::value_type ConcactIterator::operator*() const {
// TODO: Lab 4.3 解引用运算符重载
return value_type();
}
ConcactIterator::pointer ConcactIterator::operator->() const {
// TODO: Lab 4.3 ->运算符重载
return nullptr;
}
这里基本上都是实现迭代器的运算符重载函数, 算是比较简单的一个小Lab
3 测试
本小节没有测试, 你完成后续迭代器和涉及迭代器的查询操作后有统一的单元测试。
Lab 4.4 TwoMergeIterator
1 概述
根据上一节Lab 4.3 ConcactIterator中对TwoMergeIterator的介绍, TwoMergeIterator就是整合两个优先级不同的迭代器, 生成一个新的迭代器, 该迭代器优先级为两个迭代器中优先级较高的那个。
其余逻辑上一节Lab 4.3 ConcactIterator已经有所介绍, 这里不再赘述, 直接开始看头文件定义:
class TwoMergeIterator : public BaseIterator {
private:
std::shared_ptr<BaseIterator> it_a;
std::shared_ptr<BaseIterator> it_b;
bool choose_a = false;
mutable std::shared_ptr<value_type> current; // 用于存储当前元素
uint64_t max_tranc_id_ = 0;
};
这里也很简单, 就只是存储两个迭代器 的指针it_a和it_b, 以及一个choose_a用于标记当前是否选择了优先级较高的it_a迭代器是, 一个current用于缓存当前迭代器位置的键值对, 一个max_tranc_id_用于记录当前可见事务的最大id。
2 代码实现
2.1 运算符重载
BaseIterator &TwoMergeIterator::operator++() {
// TODO: Lab 4.4: 实现 ++ 重载
}
bool TwoMergeIterator::operator==(const BaseIterator &other) const {
// TODO: Lab 4.4: 实现 == 重载
return false;
}
bool TwoMergeIterator::operator!=(const BaseIterator &other) const {
// TODO: Lab 4.4: 实现 != 重载
return false;
}
BaseIterator::value_type TwoMergeIterator::operator*() const {
// TODO: Lab 4.4: 实现 * 重载
return {};
}
TwoMergeIterator::pointer TwoMergeIterator::operator->() const {
// TODO: Lab 4.4: 实现 -> 重载
return nullptr;
}
老套路, 你需要先实现迭代器的各个运算符重载函数, 不过建议你看看下面的辅助函数, 你在实现这些运算符重载函数的时候会用到这些辅助函数, 不妨一起实现了。
2.2 辅助函数
首先choose_it_a判断当前解引用应该使用哪个迭代器:
bool TwoMergeIterator::choose_it_a() {
// TODO: Lab 4.4: 实现选择迭代器的逻辑
return false;
}
然后是更新当前缓存值的函数:
void TwoMergeIterator::update_current() const {
// TODO: Lab 4.4: 实现更新缓存键值对的辅助函数
}
这个函数你可能会在之前的自增运算符和->运算符重载中调用
最后这个函数是根据事务可见性进行滤除的辅助函数, 当前不需要实现, 只是标记下便于你之后的Lab来更新:
void TwoMergeIterator::skip_by_tranc_id() {
// TODO: Lab xx
}
3 测试
本小节没有测试, 你完成后续迭代器和涉及迭代器的查询操作后有统一的单元测试。
Lab 4.5 Compact
1 概述
完成了ConcactIterator和TwoMergeIterator, 我们就已经可以开始实现我们的Compact流程了。
在LSM(Log-Structured Merge)树中,数据最初写入一个称为 memtable 的内存结构。一旦 memtable 达到一定大小限制,其内容会被刷写到磁盘上作为 SSTable(Sorted String Table)。随着时间的推移,可能会在 LSM 树的不同层级积累多个 SSTable。这些 SSTable 可能会导致以下问题:
- 读放大:查询一个键时,系统可能需要搜索多个不同层级的 SSTable。这会增加 I/O 操作次数,从而降低读取性能。
- 写放大:频繁的写操作生成新的 SSTable,最终需要与现有 SSTable 合并。如果没有压缩,这会导致过多的磁盘写入。
- 空间放大:被删除或覆盖的键可能仍然存在于旧的 SSTable 中,直到它们通过压缩被清除。这浪费了磁盘空间。
为了解决这些问题,需要进行 压缩(compaction)。压缩将较小的 SSTable 合并成较大的 SSTable,移除过时的数据(如已删除或覆盖的键),并平衡各层级之间的数据分布。
由于Compact的策略对LSM Tree的性能有着绝对影响, 因此实际工业界的Compact策略非常多, 我们这一章先介绍不同的Compact策略, 再来实现一种最简单的Compact策略
2. 经典的SST压缩方案
这里先介绍一些经典的SST压缩方案。
2.1 基于大小的分层压缩(Size-Tiered Compaction)
这种方案按大小和层级对 SSTable 进行分组。每一层包含大致相同大小的 SSTable。当某一层的 SSTable 数量超过阈值时,它们会被合并成一个或多个 SSTable 并移动到下一层。
-
流程:
- 将 Level L 的 SSTable 合并成一个或多个 SSTable 并移动到 Level L+1。
- 如果必要,递归执行此过程。
-
优点:
- 实现简单。
- 高效处理高写入吞吐量。
-
缺点:
- 可能导致显著的读放大,因为单次查询可能需要扫描多个层级。
-
示意图:
Level 0: [SST1] [SST2] [SST3] Level 1: [SST4] [SST5] Level 2: [SST6] 压缩后: Level 0: [] Level 1: [Merged(SST1,SST2,SST3)] Level 2: [SST6]
2.2 分层压缩(Leveled Compaction)
这种方案将 SSTable 分布在不同的层级,确保每个层级包含固定数量的数据。较低层级的数据以小块形式逐步移动到较高层级。
-
流程:
- 将 Level L 的 SSTable 按键范围拆分成更小的部分,并与 Level L+1 中重叠的 SSTable 合并。
- 每次压缩只影响 Level L+1 中的一小部分 SSTable。
-
优点:
- 相比基于大小的分层压缩,减少了读放大。
- 确保每个层级的键范围不重叠。
-
缺点:
- 实现复杂度更高。
- 频繁的小规模合并导致较高的写放大。
-
示意图:
Level 0: [SST1] [SST2] [SST3] Level 1: [RangeA] [RangeB] [RangeC] Level 2: [RangeD] [RangeE] 压缩后: Level 0: [] Level 1: [Merged(SST1,RangeA)] [Merged(SST2,RangeB)] [Merged(SST3,RangeC)] Level 2: [RangeD] [RangeE]
2.3 混合压缩(Hybrid Compacti2.3)
一些系统结合了基于大小的分层压缩和分层压缩的优点。例如,前几层使用基于大小的分层压缩,而较深层级切换到分层压缩。
-
优点:
- 在读放大和写放大之间取得平衡。
- 根据工作负载特性提供灵活性。
-
缺点:
- 管理多种压缩策略增加了复杂性。
3 本项目 SST Compact 设计
本项目的compact机制采用了一种混合方法,主要在第0层使用基于大小的分层压缩,而在更高层则转向分层压缩。以下是详细的设计说明
3.1 触发压缩的时机
- Level 0:如果 Level 0 的 SSTable 数量超过一个阈值
LSM_SST_LEVEL_RATIO,则触发全量压缩,将所有 Level 0 的 SSTable 移动到 Level 1。 - 更高层:如果某一层的 SSTable 数量超过
LSM_SST_LEVEL_RATIO,系统会递归检查下一层是否也需要压缩,然后继续执行。
LSM_SST_LEVEL_RATIO定义在config.toml中
这里重点解释一下 LSM_SST_LEVEL_RATIO的含义, 它的含义是相邻两层的单个SST容量之比, 同时也是单层SST数量的阈值。这里我为了方便压缩触发的条件判断的便捷性, 规定每一个Level的SST数量阈值恒定。例如, 每层SST数量超过16时就需要进行compact, 这一层16个SST被合并为下一层的单个SST, 因此这个单个SST的容量是上一个Level中单个SST的容量的16倍。这个案例中, LSM_SST_LEVEL_RATIO就是16。
3.2 递归压缩
-
确定源层和目标层:
- 确定源层 (
src_level) 和目标层 (src_level + 1)。 - 获取这两层的 SSTable ID。
- 确定源层 (
-
判断是否进行递归压缩
- 由于
src_level层是触发了这一次compact操作, 因此其SST数量肯定大于等于LSM_SST_LEVEL_RATIO - 但还需要判断目标层(
src_level + 1)的SST数量是否大于等于LSM_SST_LEVEL_RATIO。如果时, 则需要先将src_level + 1层的SST全部压缩到src_level + 2层 - 上述的判断递归地在更高的
Level中进行
- 由于
-
合并SSTable:
- 对于
Level 0,由于其不同SST中的key有重叠, 需要使用full_l0_l1_compact处理键范围重叠的问题 - 对于更高层, 其
key本来就是从小大大排布的, 使用full_common_compact合并不重叠键范围的SSTable。
- 对于
-
生成新SSTable:
- 使用
gen_sst_from_iter从合并后的迭代器结果生成新的 SSTable。 - 确保新 SSTable 的大小符合
get_sst_size定义的限制。
- 使用
-
更新元数据:
- 删除旧的 SSTable(从内存和磁盘中移除)。
- 将新的 SSTable 添加到适当的目标层。
- 更新
level_sst_ids并对其进行排序以便高效访问。
这里的
full_l0_l1_compact和full_common_compact会在后文中介绍
关键特性
- 事务处理:在压缩过程中,确保只将可见记录(基于事务ID)包含在新的 SSTable 中。
- 并发控制:使用锁(
std::shared_mutex)防止在访问共享资源(如ssts_mtx)时发生竞争条件。 - 高效迭代:利用迭代器(
TwoMergeIterator、HeapIterator、ConcactIterator)高效遍历和合并来自多个 SSTable 的数据。
示例流程
假设初始状态如下:
-
压缩前:
Level 0: [SST1] [SST2] [SST3] Level 1: [SST4] [SST5] Level 2: [SST6] -
触发条件:Level 0 有三个 SSTable,超过了阈值(
LSM_SST_LEVEL_RATIO = 2)。 -
压缩过程:
- 合并
[SST1]、[SST2]和[SST3]成为一个迭代器。 - 将该迭代器的结果与
[SST4]和[SST5]从 Level 1 中合并。 - 生成新的 SSTable 并将其分配到 Level 1。
- 合并
-
压缩后:
Level 0: [] Level 1: [NewSST1] [NewSST2] Level 2: [SST6]
TODO: 后续版本应该在此处添加一张流程图
4 本实验 Compact 策略的优势和劣势
本实验的Compact策略属于 Leveled Compaction (分层合并) 的一种变体。这种全层合并的Leveled Compaction策略,与其他主流策略的对比如下
Size-Tiered Compaction (STCS - 基于大小分层的合并)
Classic Leveled Compaction (经典的、更细粒度的分层合并,如LevelDB/RocksDB采用的策略)
| 特性 (Aspect) | 本实验策略 (Leveled - 全层合并) | Size-Tiered Compaction (STCS) | 经典Leveled Compaction (细粒度合并) |
|---|---|---|---|
| 读放大 (Read Amplification) | L0层: 中等 (需查找多个SSTable) L1+层: 低 (由于SSTable不重叠且有序,每层理论上最多查找一个SSTable) | 高 (通常需要在多个层级(Tier)的多个SSTable中查找,因为不同SSTable间的键范围可能大量重叠) | L0层: 中等 (需查找多个SSTable) L1+层: 低 (与本实验的策略类似,L1+层SSTable不重叠) |
| 写放大 (Write Amplification) | 非常高 (合并Level_N和Level_{N+1}时,两个层级的全部数据都会被读取和重写,即使Level_{N+1}中大部分是“冷”数据) | 低 (数据在其生命周期中被重写的次数相对较少,通常是合并固定数量的SSTable) | 中等 (比STCS高,但显著低于“全层合并”。仅合并Level_N中少量被选中的SSTable及其在Level_{N+1}中的键范围重叠部分) |
| 空间放大 (Space Amplification) | 低 (合并过程频繁且较为彻底地重写数据,有利于快速回收无效数据和墓碑(Tombstone)占用的空间) | 高 (旧版本数据和墓碑可能长时间存在于未被合并的SSTable中,导致总体磁盘占用较大,最坏情况一个键的多个版本都存在) | 低 (与“全层合并”类似,能较好控制空间。因单次合并范围较小,整体回收速度可能略慢于全层合并,但通常有严格的层级大小限制) |
| 合并I/O成本 (Compaction I/O Cost) | 高 (单次合并涉及的数据量通常很大,导致瞬时I/O和CPU压力显著,可能引发性能抖动或“合并风暴”) | 中低 (通常合并固定数量(例如N个)的SSTable,单次合并成本相对可控,但合并操作可能更频繁) | 中等 (单次合并的数据量介于STCS和“全层合并”之间,致力于平滑I/O负载) |
| 实现复杂度 | 中等 (比STCS复杂,因为需要维护层级结构和SSTable元数据;但比经典的细粒度Leveled Compaction简单,因为合并整个层级的逻辑较直接) | 低 (逻辑相对简单,主要是基于SSTable的大小和数量触发合并,易于实现和维护) | 高 (需要复杂的SSTable挑选逻辑(picking logic)来决定哪些SSTable参与合并,键范围管理、并发控制以及避免写暂停等机制都较复杂) |
| 墓碑/旧数据清理效率 | 高 (由于整个层级的数据会定期参与合并过程,墓碑和旧版本数据能得到较快和较彻底的清理) | 低 (清理效率依赖于包含墓碑或旧数据的SSTable何时被选中参与合并,可能存在较长延迟) | 中高 (数据也定期参与合并过程,但由于单次合并涉及的数据范围小于全层合并,整体清理速度和彻底性可能稍逊于全层合并,但仍属高效) |
| 查询性能稳定性/可预测性 | L1+层: 好 (查询路径短且固定,性能稳定) L0层: 一般 (受SSTable数量影响) | 差 (查询性能波动较大,取决于数据具体分布在哪些SSTable以及需要检查的SSTable数量) | L1+层: 好 (查询路径短且固定,性能稳定) L0层: 一般 (受SSTable数量影响) |
5 本实验的代码实现
在完成之前的理论学习后, 你可以开始实现本实验的代码了
本小节你需要更改的代码文件为:
src/lsm/engine.cppinclude/lsm/engine.h(Optional)
5.1 新SST的构造
gen_sst_from_iter从一个迭代器中构造新的SST, 新的SST的容量上限为target_sst_size, 新的SST的层级为target_level。 也就是说, 假设迭代器中所有键值对的容量是128 MB, 而target_sst_size = 32MB, 那么你需要构造4个SST。
std::vector<std::shared_ptr<SST>>
LSMEngine::gen_sst_from_iter(BaseIterator &iter, size_t target_sst_size,
size_t target_level) {
// TODO: Lab 4.5 实现从迭代器构造新的 SST
return {};
}
这里, SST的命名规则参照get_sst_path:
std::string LSMEngine::get_sst_path(size_t sst_id, size_t target_level) {
// sst的文件路径格式为: data_dir/sst_<sst_id>,sst_id格式化为32位数字
std::stringstream ss;
ss << data_dir << "/sst_" << std::setfill('0') << std::setw(32) << sst_id
<< '.' << target_level;
return ss.str();
}
sst的id的分配可以简单地按照如下操作获取:size_t sst_id = next_sst_id++
5.2 full_l0_l1_compact
full_l0_l1_compact负责将L0层和L1层的SST合并到L1层, 因为L0层的SST之间是不排序且存在重叠的, 因此你需要结合之前实现的迭代器对其进行排序和去重, 并和L1迭代器整合成新的迭代器, 出入你刚刚实现的gen_sst_from_iter函数, 完成新的SST的构造:
std::vector<std::shared_ptr<SST>>
LSMEngine::full_l0_l1_compact(std::vector<size_t> &l0_ids,
std::vector<size_t> &l1_ids) {
// TODO: Lab 4.5 负责完成 l0 和 l1 的 full compact
return {};
}
根据我们的
Compact策略设计,Ln层的SST容量应该是Ln-1层的LSM_SST_LEVEL_RATIO倍, 作者已经提供了get_sst_size帮助你计算任意一层SST的容量
5.2 full_common_compact
full_common_compact负责其他相邻Level的SST合并, 你需要参考full_l0_l1_compact的实现, 完成其他相邻Level的SST合并。这里应该会更简单,因为这里相邻的两个Level的SST之间是排序且不重叠的, 因此单个Level的迭代器都是相同的类型:
std::vector<std::shared_ptr<SST>>
LSMEngine::full_common_compact(std::vector<size_t> &lx_ids,
std::vector<size_t> &ly_ids, size_t level_y) {
// TODO: Lab 4.5 负责完成其他相邻 level 的 full compact
return {};
}
5.3 full_compact
full_compact负责整个Compact流程, 你需要根据Compact策略设计, 完成这个函数。另外, 由于每次compact会导致目标Level的SST数量增加, 因此这个compact流程可能会哦递归地进行, 你需要在full_compact中控制这个递归过程。也就是说,你需要按照我们之前描述的策略控制之前实现的full_common_compact和full_l0_l1_compact的调用:
void LSMEngine::full_compact(size_t src_level) {
// TODO: Lab 4.5 负责完成整个 full compact
// ? 你可能需要控制`Compact`流程需要递归地进行
}
点击这里展开/折叠提示 (建议你先尝试自己完成)
这里给出作者对这个函数的的实现思路:
LSMEngine::full_compact 函数的目标是将指定层级 src_level 的所有 SSTable 压缩到下一层级 src_level + 1,并通过合并和优化减少冗余数据,提升读写性能。其步骤为:
a. 递归检查下一层是否需要压缩
- 在对当前层级(
src_level)进行全量压缩之前,先检查下一层级(src_level + 1)是否也需要进行全量压缩。 - 如果
src_level + 1层的 SSTable 数量超过阈值(LSM_SST_LEVEL_RATIO),则递归调用full_compact(src_level + 1)对下一层进行压缩。 - 这种递归机制确保了在压缩当前层之前,目标层已经处于优化状态。
b. 获取源层级和目标层级的 SSTable ID
- 从
level_sst_ids[src_level]和level_sst_ids[src_level + 1]中分别获取当前层级和目标层级的所有 SSTable ID。 - 将这些 ID 转换为两个向量:
lx_ids(源层级)和ly_ids(目标层级),便于后续处理。
c. 根据层级选择不同的压缩方式
- 根据
src_level是否为 Level 0,选择不同的压缩方法:- Level 0:由于 Level 0 的 SSTable 可能存在键范围重叠,调用
full_l0_l1_compact(lx_ids, ly_ids)处理。 - 其他层级:调用
full_common_compact(lx_ids, ly_ids, src_level + 1)处理,这些层级的 SSTable 键范围不重叠。
- Level 0:由于 Level 0 的 SSTable 可能存在键范围重叠,调用
d. 移除旧的 SSTable
- 压缩完成后,删除源层级和目标层级中所有旧的 SSTable:
- 调用
del_sst()方法释放磁盘资源。 - 从
ssts映射中移除这些 SSTable。
- 调用
- 清空
level_sst_ids[src_level]和level_sst_ids[src_level + 1],为新生成的 SSTable 准备空间。
e. 更新最大层级
- 更新
cur_max_level,确保其始终表示当前 LSM 树中的最大层级。
f. 添加新的 SSTable
- 将新生成的 SSTable 添加到目标层级(
src_level + 1):- 将新 SSTable 的 ID 插入到
level_sst_ids[src_level + 1]。 - 将新 SSTable 本身插入到
ssts映射中。
- 将新 SSTable 的 ID 插入到
- 对
level_sst_ids[src_level + 1]进行排序,确保 SSTable 按顺序存储,便于高效访问。
5.4 Compact 的触发时机
最后, full_compact的调用肯定需要有一个触发时机, 你可以选择在put时候惰性地检查每层Level的SST数量是否达到阈值, 也可以单独创建一个线程进行轮训检查, 具体实现方案取决于你自己, 因此这里就没有对指定的函数进行挖空让你实现了。
6 测试
这一章的测试有一点特别, 由于我们常规测试中为了速度考虑, 不会有大量的键值对插入行为。而测试Compact, 需要数据量较大时, 才会触发多个SST文件的持久化以及超出数量后的compact操作, 因此这里的建议是, 将配置文件中单个L0 SST的大小(也就是单个Skiplist的大小)调小(其他相应参数也一并调小), 然后运行Persistence函数。
例如我如下调整配置:
[lsm.core]
# Memory table size limit (64MB)
# LSM_TOL_MEM_SIZE_LIMIT = 67108864 # Calculated from 64 * 1024 * 1024 # 原来的 MemTable 容量限制
LSM_TOL_MEM_SIZE_LIMIT = 65536 # Calculated from 64 * 1024 * 1024
# Per-memory table size limit (4MB)
# LSM_PER_MEM_SIZE_LIMIT = 4194304 # Calculated from 4 * 1024 * 1024 # 原来的单个 Skiplist 容量限制
LSM_PER_MEM_SIZE_LIMIT = 8192 # Calculated from 4 * 1024 * 1024
# Block size (32KB)
# LSM_BLOCK_SIZE = 32768 # Calculated from 32 * 1024 # # 原来的单个 Block 容量限制
LSM_BLOCK_SIZE = 1024 # Calculated from 32 * 1024
# SST level size ratio
LSM_SST_LEVEL_RATIO = 4
需要注意的是, 单元测试读取配置文件默认是当前目录下的
config.toml因此你需要将修改后的配置文件复制到编译单元测试的目录, 一般是:./build/linux/x86_64/release # release 版本 ./build/linux/x86_64/debug # debug 版本
你只需要关注这个测例:
// test/test_lsm.cpp
TEST_F(LSMTest, Persistence) {
// ...
}
通过这个测试即可
TODO: 后期实验项目书应进行优化, 不应该让学员手动来控制这一过程
Lab 4.6 Level_Iterator
1 概述
为什么要将Level_Iterator放在Compact之后呢? 当然是因为Compact之后, 我们才有了Level的概念, 才能对某个Level的所有键值对进行迭代.
Level_Iterator的实现其实非常简单了, 与TwoMergeIterator非常类似, 只不过整合的迭代器数量是不定的, 用一个vector存储, 我们先简单看看定义:
class Level_Iterator : public BaseIterator {
// ...
private:
std::shared_ptr<LSMEngine> engine_;
std::vector<std::shared_ptr<BaseIterator>> iter_vec;
size_t cur_idx_;
uint64_t max_tranc_id_;
mutable std::optional<value_type> cached_value; // 缓存当前值
std::shared_lock<std::shared_mutex> rlock_;
};
这里同样是有上层LSMEngine的智能指针engine_, iter_vec按照索引顺序存储不同优先级的迭代器, 这里的情形就是不同的Level的层间迭代器(ConcactIterator)
当然, 也不一定是
ConcactIterator, 只要多个迭代器存在优先级的概念, 都可以用ConcactIterator进行整合。例如我们之前由于Level 0的不同SST存在重叠且为排序, 这种情况也可以用ConcactIterator进行整合, 因为id更大的SST优先级更高, 需要先遍历。同时也看出我们迭代器设计存在强大的复用性,因为这里的BaseIterator是抽象类,只要实现了BaseIterator的接口,都可以作为iter_vec的元素, 从而实现整合逻辑的复用。
2 代码实现
相比上一章, 这一章轻松不少, 只需要实现几个简单的重载和构造函数初始化流程即可
本小节你需要修改的代码文件:
src/lsm/level_iterator.cppinclude/lsm/level_iterator.h(Optional)
2.1 迭代器初始化
Level_Iterator::Level_Iterator(std::shared_ptr<LSMEngine> engine,
uint64_t max_tranc_id)
: engine_(engine), max_tranc_id_(max_tranc_id), rlock_(engine_->ssts_mtx) {
// TODO: Lab 4.6 Level_Iterator 初始化
}
这里的初始化流程就是提取每一个Level的迭代器然后放入iter_vec中, 不过同样的, Level 0的SST由于存在重叠且未排序, 需要进行额外处理。
思考: 初始化
iter_vec后, 是否需要进行一些额外的判断呢?
2.2 运算符重载
接下来就是我们的传统艺能————运算符函数重载了:
BaseIterator &Level_Iterator::operator++() {
// TODO: Lab 4.6 ++ 重载
return *this;
}
bool Level_Iterator::operator==(const BaseIterator &other) const {
// TODO: Lab 4.6 == 重载
return false;
}
bool Level_Iterator::operator!=(const BaseIterator &other) const {
// TODO: Lab 4.6 != 重载
return false;
}
BaseIterator::value_type Level_Iterator::operator*() const {
// TODO: Lab 4.6 * 重载
return {};
}
BaseIterator::pointer Level_Iterator::operator->() const {
// TODO: Lab 4.6 -> 重载
return nullptr;
}
类似地, 你可以先看看接下来要实现的一些辅助功能函数, 也许你会在实现这些运算符重载时需要用到它们。
2.3 辅助函数
std::pair<size_t, std::string> Level_Iterator::get_min_key_idx() const {
// TODO: Lab 4.6 获取当前 key 最小的迭代器在 iter_vec 中的索引和具体的 key
return {};
}
void Level_Iterator::skip_key(const std::string &key) {
// TODO: Lab 4.6 跳过 key 相同的部分(即被当前激活的迭代器覆盖的写入记录)
}
void Level_Iterator::update_current() const {
// TODO: Lab 4.6 更新当前值 cached_value
// ? 实现 -> 时你也许会用到 cached_value
}
3 测试
次小节的测试将在实现下一小节 Lab 4.7 复杂查询 后统一进行。
Lab 4.7 复杂查询
1 概述
其实也就是我们每个组件实现过程中最后实现的范围查询, 只是我们之前简单的begin和end也是需要实现Level_Iterator, 因此这里就统称其为复杂查询了。
本小节你需要更改的代码文件为:
src/lsm/engine.cppinclude/lsm/engine.h(Optional)
2 全局迭代器
现在你已经有了各种各样的迭代器,那么LSMEngine的begin/end自然也不在话下了:
Level_Iterator LSMEngine::begin(uint64_t tranc_id) {
// TODO: Lab 4.7
throw std::runtime_error("Not implemented");
}
Level_Iterator LSMEngine::end() {
// TODO: Lab 4.7
throw std::runtime_error("Not implemented");
}
这里只需要简单地调用Level_Iterator的构造函数即可
3 范围查询
最后, 比全局迭代器稍微复杂的是谓词查询:
std::optional<std::pair<TwoMergeIterator, TwoMergeIterator>>
LSMEngine::lsm_iters_monotony_predicate(
uint64_t tranc_id, std::function<int(const std::string &)> predicate) {
// TODO: Lab 4.7 谓词查询
return std::nullopt;
}
这里的复杂点在于, 这是一个顶层的范围查询, 你需要完成的是所有组件迭代器的组合、排序和滤除。你需要灵活地运用我们已经实现的各种迭代器, 完成这个复杂的查询。
这个函数你应该能体会到我们实验代码涉及中迭代器复用的精妙之处
4 测试
现在你应该能通过test_lsm的大部分测试了:
✗ xmake
[100%]: build ok, spent 1.389s
✗ xmake run test_lsm
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from LSMTest
[ RUN ] LSMTest.BasicOperations
[ OK ] LSMTest.BasicOperations (1007 ms)
[ RUN ] LSMTest.Persistence
[ OK ] LSMTest.Persistence (2022 ms)
[ RUN ] LSMTest.LargeScaleOperations
[ OK ] LSMTest.LargeScaleOperations (1021 ms)
[ RUN ] LSMTest.MixedOperations
[ OK ] LSMTest.MixedOperations (1043 ms)
[ RUN ] LSMTest.IteratorOperations
[ OK ] LSMTest.IteratorOperations (1001 ms)
[ RUN ] LSMTest.MonotonyPredicate
[ OK ] LSMTest.MonotonyPredicate (1019 ms)
# 其余测试与实物相关
5 总结与思考
这应该是目前为止强度最大的一个阶段的Lab了, 不过现在你已经得到了可以运行并执行部分复杂功能的LSM引擎了, 所以这一阶段标志着LSM Tree项目的初步阶段, 算是一个小小的里程碑, 有没有一点成就感?
不过我们的Lab还需要继续, 首先思考着几个问题:
- 请观察你自己的
LSMTest.Persistence的测试耗时, 是否比我的速度慢很多? 为什么? (如果你比我的速度快, 应该是硬件碾压了 🥵) - 如果你的
LSMTest.Persistence确实慢, 是不是缺少缓存池的优化? - 我们的
compact策略太粗糙, 你是否有更好的策略?
然后, 进入阶段3: 阶段3-LSM Tree 的优化
阶段3-LSM Tree 的优化
上一阶段我们完成了基础的LSM Engine的实现, 但其缺乏性能优化。这一阶段, 你将实现以Blcok为单位的缓存池,以及布隆过滤器的优化。实现这两个优化方案后, 你可以对比前后的单元测试的整体运行时间, 尤其是Persistence这个测例(其数据规模量最大), 你可以直观地感受到这里的优化方案的必要性。
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
Lab 4.8 复杂查询
1 缓存池原理与设计
1.1 缓存池的作用
在LSM Tree的实现中,数据读取是以Block为单位进行的。为了提高热点Block的读取效率,我们引入了缓存池(Buffer Pool)。缓存池的主要作用主要是减少磁盘I/O, 通过将频繁访问的Block缓存到内存中,可以显著减少对磁盘的读取次数,从而提高系统的整体性能。因此这里我们的目的就是尽量让热点Block数据常驻内存。
1.2 LRU-K算法原理
这里我采用LRU-K算法来管理缓存池。其实主要原因是以前做过CMN15445, 里面实现过LRU-K算法, 稍作改进可以直接拿来用, 这里就偷个懒了。照例还是先简单介绍下LRU-K。
LRU-K(Least Recently Used with K accesses)是一种基于访问频率和时间的缓存淘汰策略。相比于传统的LRU(最近最少使用),LRU-K考虑了更复杂的访问模式,能够更好地适应实际应用场景中的数据访问特性。LRU-K仍然是使用键值对来索引缓存内容。
设计思路
- Key:表示在决定淘汰某个缓存项时,会考虑该缓存项在过去K次访问的时间间隔。当K=1时,LRU-K退化为普通的LRU。这里我的的
Blcok可以由(sst_id, block_id)唯一索引, 因此缓存池的的Block索引键可以设计为std::pair<sst_id, block_id> - 访问链表:每个缓存项都有一个访问历史记录,记录其最近K次的访问时间。当最近访问次数大于等于K次, 则放在链表首部, 不足K次的放在后半部分, 按照访问时间排序。
淘汰规则
- 当缓存池满时,选择那些在过去K次访问中时间间隔最长的缓存项进行淘汰。
- 如果多个缓存项的时间间隔相同,则选择最早插入缓存池的那个项。
2 代码实现
2.1 代码思路梳理
这里采用一个简化的LRU-K实现, 我们不需要记录访问的时间戳, 而是用链表的顺序来表达最新的访问记录, 最新的访问置于链表头部。另一方面,为保证快速查询,我们还需要一个哈希表,这个哈希表的索引键为std::pair<sst_id, block_id>, 索引值为链表的迭代器, 因此结合二者可以简单实现查询和新增均为O(1)的缓存池。那怎么表达LRU-K呢? 很简单, 采用2个链表, 一个存储访问次数少于k次的缓存项, 一个存储访问次数大于等于k次的缓存项。
首先看一下头文件的关键定义:
struct CacheItem {
int sst_id;
int block_id;
std::shared_ptr<Block> cache_block;
uint64_t access_count; // 访问计数
};
// 定义缓存池
class BlockCache {
public:
...
private:
size_t capacity_; // 缓存容量
size_t k_; // LRU-K 中的 K 值
// 双向链表存储缓存项
std::list<CacheItem> cache_list_greater_k;
std::list<CacheItem> cache_list_less_k;
// 哈希表索引缓存项
std::unordered_map<std::pair<int, int>, std::list<CacheItem>::iterator,
pair_hash, pair_equal>
cache_map_;
...
};
点击这里展开/折叠提示 (建议你先尝试自己完成)
本思路实现的
LRU-K并不标准, 你可以按照自己的方案实行, 可以大刀阔斧地修改代码, 保证接口统一即可
我们结合cache_list_greater_k, cache_list_less_k和cache_map_来整理一下流程:
查询
- 先通过
cache_map_查询缓存项的迭代器, 通过迭代器的访问次数判断其属于哪个链表。访问次数 < k-> 属于cache_list_less_k- 如果
访问次数 == k-1,更新访问次数后就就等于k了,将其重新置于cache_list_greater_k的头部。 - 否则更新后仍然属于
cache_list_greater_k,但需要将其移动到cache_list_greater_k的头部。
- 如果
访问次数 = k-> 属于cache_list_greater_k, 将其置于cache_list_greater_k的头部。但访问次数就固定在k, 不继续增长了
插入
- 先通过
cache_map_查询缓存项是否存在, 存在则按照之前的步骤更新缓存项即可 - 不存在的话, 判断缓存池是否已满
- 没有满
- 直接插入到
cache_list_less_k头部,并更新cache_map_索引。
- 直接插入到
- 满了
- 如果
cache_list_less_k不为空,从cache_list_less_k末尾淘汰一个缓存项,并插入新的缓存项到cache_list_less_k头部。 - 如果
cache_list_less_k为空,从cache_list_greater_k末尾淘汰一个缓存项,并插入新的缓存项到cache_list_less_k。
- 如果
- 没有满
根据你的实现, 你可以更改
CacheItem的定义和排序规则, 例如记录访问的具体时间戳等
2.2 具体实现
你需要修改的代码文件包括:
src/block/block_cache.cppinclude/block/block_cache.h(Optional)
要实现的函数也很简单, 首先是插入一个Block到缓存池:
void BlockCache::put(int sst_id, int block_id, std::shared_ptr<Block> block) {
// TODO: Lab 4.8 插入一个 Block
}
然后是查询一个Block:
std::shared_ptr<Block> BlockCache::get(int sst_id, int block_id) {
// TODO: Lab 4.8 查询一个 Block
return nullptr;
}
最后是一些辅助函数, 比如你在插入和查询时, 需要更新相应Block的统计信息:
void BlockCache::update_access_count(std::list<CacheItem>::iterator it) {
// TODO: Lab 4.8 更新统计信息
}
具体更新什么统计信息呢? 除了要保证缓存池的基础运行逻辑正确外, 你看到这个获取命中率的函数可能有所启发:
double BlockCache::hit_rate() const {
std::lock_guard<std::mutex> lock(mutex_);
return total_requests_ == 0
? 0.0
: static_cast<double>(hit_requests_) / total_requests_;
}
3 缓存池的构造
现在我们已经实现了BlockCache这个类, 你应该还记得, 之前我们许多函数的参数中都包含了std::shared_ptr<BlockCache>类型的参数, 且其都发起于上层组件LSMEngine, 同时LSMEngine也包含了std::shared_ptr<BlockCache>的成员变量, 因此你需要在LSMEngine的构造函数中初始化这个成员变量, 并在调用的函数中进行传递。
一些配置参数仍然可以查看
config.toml并使用TomlConfig::getInstance().getXXX获取
4 测试
对于缓存池本身, 你应该可以通过下面的测试:
✗ xmake
✗ xmake run test_block_cache
[==========] Running 4 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 4 tests from BlockCacheTest
[ RUN ] BlockCacheTest.PutAndGet
[ OK ] BlockCacheTest.PutAndGet (0 ms)
[ RUN ] BlockCacheTest.CacheEviction1
[ OK ] BlockCacheTest.CacheEviction1 (0 ms)
[ RUN ] BlockCacheTest.CacheEviction2
[ OK ] BlockCacheTest.CacheEviction2 (0 ms)
[ RUN ] BlockCacheTest.HitRate
[ OK ] BlockCacheTest.HitRate (0 ms)
[----------] 4 tests from BlockCacheTest (0 ms total)
[----------] Global test environment tear-down
[==========] 4 tests from 1 test suite ran. (0 ms total)
[ PASSED ] 4 tests.
在SSt和Block的逻辑层面, 本节实验并未新添加任何接口, 只是做出了IO层面的优化, 因此, 你只需要像Lab 4.7 复杂查询那样再次运行单元测试, 观察前后数据读取的效率变化即可。
需要说明的是, 你需要尤其关注Persistence这个测例(位于test/test_lsm.cpp), 因为其会插入大量的数据并刷盘, 此时的大部分查询请求都是在SST文件层面进行的, 能够较为明显地观察出加入缓存池优化后的速度变化。
Lab 4.9 布隆过滤器
除了缓存池之外,我们下一个要实现的优化方案是布隆过滤器。布隆过滤器你可能在各大校招实习的八股文中都遇到过(尤其是和经典问题:如何避免Redis的缓存穿透问题)。本小节我们就将自己实现一个布隆过滤器。
1 布隆过滤器简介
1.1 原理介绍
布隆过滤器是一种 probabilistic 数据结构,用于判断一个元素是否在集合中。它通过一个概率的方式来判断,即使集合中存在一个元素,但是布隆过滤器也依然可以判断出来。
布隆过滤器的核心思想是使用一个位数组和多个哈希函数来表示一个集合。它的特点是可以高效地判断某个元素是否“可能存在”或“确定不存在”,但它有一定的误判率,即可能会误判某个不存在的元素为“可能存在”。其实现方式如下:
- 初始化位数组:布隆过滤器使用一个固定大小的位数组(如长度为
m),所有位初始化为0。 - 插入元素时在位数组记录:当插入一个元素时,使用
k个独立的哈希函数对该元素进行哈希运算,得到k个哈希值(每个值对应位数组的索引)。将这些索引位置的位设置为1。 - 查询元素时在位数组校验:当查询一个元素是否存在时,同样使用
k个哈希函数对该元素进行哈希运算,得到k个哈希值。如果这些哈希值对应的位数组中的所有位都为1,则判断该元素“可能存在”;如果有任意一位为0,则判断该元素“确定不存在”。
特点
- 优点:布隆过滤器的空间效率和查询效率非常高,适合处理大规模数据。
- 缺点:存在一定的误判率(即可能会误判不存在的元素为“可能存在”),并且无法删除元素(删除可能会影响其他元素的判断)。
1.2 案例介绍
下面我们通过一个案例来看看布隆过滤器的运行机制:
- 在新增一个记录时(
put/insert等), 通过预定义数量(案例图片中是2个)的哈希函数对key进行哈希, 将哈希值对位数组的长度取模, 将结果作为索引, 将索引位置的位设置为1 - 在查询时(
get), 通过预定义数量(案例图片中是2个)的哈希函数对key进行哈希, 将哈希值对位数组的长度取模, 将结果作为索引, 如果索引位置的位为1, 则认为该key可能存在, 否则认为该key不存在
2 LSM-Tree中的布隆过滤器
尽管我们之前为整个LSM-Tree设计了bock cache, 但面对大量不存在于LSM-Tree中的key时, bock cache会频繁的进行磁盘IO, 这将导致LSM-Tree的性能降低。
这里的原理类似后端八股文中
Redis常问的缓存击穿、缓存穿透、缓存雪崩,而设置布隆过滤器就是一个景点的解决方案,背过八股的同学们应该会很熟悉。
因此,我们可以在编码SST文件时,为每个SST文件都设计一个bloom filter, 在其中记录整个SST中的所有key, 并将其持久化到文件系统中, 在读取文件时, 相应的布隆过滤器部分也需要被解码并加载到内存中。这样当查询时, 我们只需要判断key是否存在于bloom filter中, 如果不存在, 则认为该key不存在于LSM-Tree, 否则, 我们需要继续在LSM-Tree中查找。这样以来, 我们就可以避免大量的无效访问。
3 布隆过滤器代码解读
同样地, 我们解读下头文件的定义:
class BloomFilter {
public:
// 构造函数,初始化布隆过滤器
// expected_elements: 预期插入的元素数量
// false_positive_rate: 允许的假阳性率
BloomFilter();
BloomFilter(size_t expected_elements, double false_positive_rate);
// ...
private:
// 布隆过滤器的位数组大小
size_t expected_elements_;
// 允许的假阳性率
double false_positive_rate_;
size_t num_bits_;
// 哈希函数的数量
size_t num_hashes_;
// 布隆过滤器的位数组
std::vector<bool> bits_;
private:
// 第一个哈希函数
// 返回值: 哈希值
size_t hash1(const std::string &key) const;
// 第二个哈希函数
// 返回值: 哈希值
size_t hash2(const std::string &key) const;
size_t hash(const std::string &key, size_t idx) const;
};
我们需要完成如下的功能:
- 能够在初始化时通过假阳性率和键的数量来确定哈希函数的数量和位数组的长度
- 支持编码与解码
对于通过假阳性率和键的数量来确定哈希函数的数量和位数组的长度, 我们可以按照指定的公式求取, 但问题在于我们是不知道哈希函数的数量的, 难道我们要手动写很多个哈希函数吗?
我们可以采用这样的方案: 只写2个哈希函数, 通过对这两个哈希函数的线性组合构造新的哈希函数, 这也就是你在头文件定义中看到的hash1和hash2
这里有一个坑,
std::vector<bool>中单个元素存储只占一个位, 而不是一个字节
此外, 你应该从之前的介绍中了解到, 布隆过滤器只能滤除百分百不存在的元素, 但其不能保证一个元素一定存在。不过我们可以给出一个目标概率, 例如,如果目标概率为0.01,则表示我们希望布隆过滤器误判的概率不超过1%。这就是成员变量中的false_positive_rate。
假阳性率和位数组长度之间的关系可以用以下公式表示:
$$m = - \frac{n \cdot \ln(p)}{(\ln(2))^2}$$
其中,m 是位数组的长度,n 是预期插入的元素数量,p 是假阳性率。
而哈希函数的数量由公式: $$k = \frac{m}{n} \cdot \ln(2)$$
为什么公式是这样的? 你可以尝试自己推导, 也可以去
LLM
4 代码实现
4.1 构造函数
// 构造函数,初始化布隆过滤器
// expected_elements: 预期插入的元素数量
// false_positive_rate: 允许的假阳性率
BloomFilter::BloomFilter(size_t expected_elements, double false_positive_rate)
: expected_elements_(expected_elements),
false_positive_rate_(false_positive_rate) {
// TODO: Lab 4.9: 初始化数组长度
}
这里, 构造函数就是按照之前理论介绍部分中的公式, 确定数组长度并初始化容器和哈希函数数量
4.2 hash
如同之前介绍的, hash函数有很多个, 我们不可能手动写出一大堆候选函数出来, 因此这里你需要对hash1和hash2进行组合, 构造出新的哈希函数(idx标识这是第几个哈希函数):
size_t BloomFilter::hash(const std::string &key, size_t idx) const {
// TODO: Lab 4.9: 计算哈希值
// ? idx 标识这是第几个哈希函数
// ? 你需要按照某些方式, 从 hash1 和 hash2 中组合成新的哈希函数
return 0;
}
4.3 add
添加记录时, 我们根据哈希函数的序号, 调用你之前实现的hash函数, 将结果对位数组的长度取模, 将结果作为索引, 将索引位置的位设置为1:
void BloomFilter::add(const std::string &key) {
// TODO: Lab 4.9: 添加一个记录到布隆过滤器中
}
4.4 encode/decode
与缓存池不同, 布隆过滤器需要持久化到文件系统中。这是因为我们的Block在形成后就是只读的形式了, 不会发生变化。如果不持久化到文件系统中, 那么在重启时, 我们就则需要对每个键值对再次进行解码和哈希运算构造新的布隆过滤器实例, 这显然是不合理的。因此你需要实现编码和解码函数:
// 编码布隆过滤器为 std::vector<uint8_t>
std::vector<uint8_t> BloomFilter::encode() {
// TODO: Lab 4.9: 编码布隆过滤器
return std::vector<uint8_t>();
}
// 从 std::vector<uint8_t> 解码布隆过滤器
BloomFilter BloomFilter::decode(const std::vector<uint8_t> &data) {
BloomFilter bf;
// TODO: Lab 4.9: 解码布隆过滤器
return bf;
}
这里我们仍然使用std::vector<uint8_t>作为编码后的数据结构, 你需要将位数组中的每个元素都编码为一个字节, 并将所有字节拼接起来。这里的二进制数组将整合到SST文件中。
5 将 BloomFilter 集成到 SST
现在你已经实现了BloomFilter, 你需要将其集成到SST文件中。具体来说,你需要修改SST文件的编码和解码函数:
- 编码时调用
BloomFilter::encode将编码的布隆过滤器部分的std::vector<uint8_t>拼接到SST文件的正确位置; - 解码时从
SST文件的指定偏移位置取出std::vector<uint8_t>切片, 并解码出BloomFilter放置于SST类实例的控制结构的成员变量中。
这里回顾一下我们的SST文件的结构:
你应该知道这里Bloom Section的...里面放置的是什么了吧?
首先, 之前的SSTBuilder::build和SST::open涉及整个SST的持久化和编解码, 是你肯定需要修改的。此外由于每个人的设计思路不同, 因此其他地方没有固定的修改文件和函数, 你只需要保证编解码过程正确、查询数据时能够正常利用到布隆过滤器即可。
6 测试
对于布隆过滤器本身, 你应该可以通过下面的测试:
✗ xmake
✗ xmake run test_utils # 布隆过滤器的测试包含在 `test_utils` 中
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from BloomFilterTest
[ RUN ] BloomFilterTest.ComprehensiveTest
False positive rate: 0.08
[ OK ] BloomFilterTest.ComprehensiveTest (2 ms)
[----------] 1 test from BloomFilterTest (2 ms total)
[----------] Global test environment tear-down
[==========] 1 test f
类似之前缓存池的小节, 在逻辑层面本节实验并未新添加任何接口, 只是做出了IO层面的优化, 因此, 你只需要像Lab 4.7 复杂查询那样再次运行单元测试, 观察前后数据读取的效率变化即可。
需要说明的是, 你需要尤其关注Persistence这个测例(位于test/test_lsm.cpp), 因为其会插入大量的数据并刷盘, 此时的大部分查询请求都是在SST文件层面进行的, 能够较为明显地观察出加入缓存池优化后的速度变化。
Lab 5 事务 && MVCC && WAL
事务理论知识
本小节主要介绍事务的基本概念,事务的ACID特性,事务的隔离级别, 没有代码任务需要你完成。因此,如果你对这些内容已经熟悉,可以跳过本小节,直接进入下一节。
1 本小节目标
之前大家实现的各种函数中, 都是忽略了tranc_id这个参数的, 这一小节之后, tranc_id的神秘面纱将被揭开, 我们将学习事务的基础知识, 并修改之前所有的涉及tranc_id的函数, 使其能够支持事务特性。
首先给出本章实验后的架构示意图:
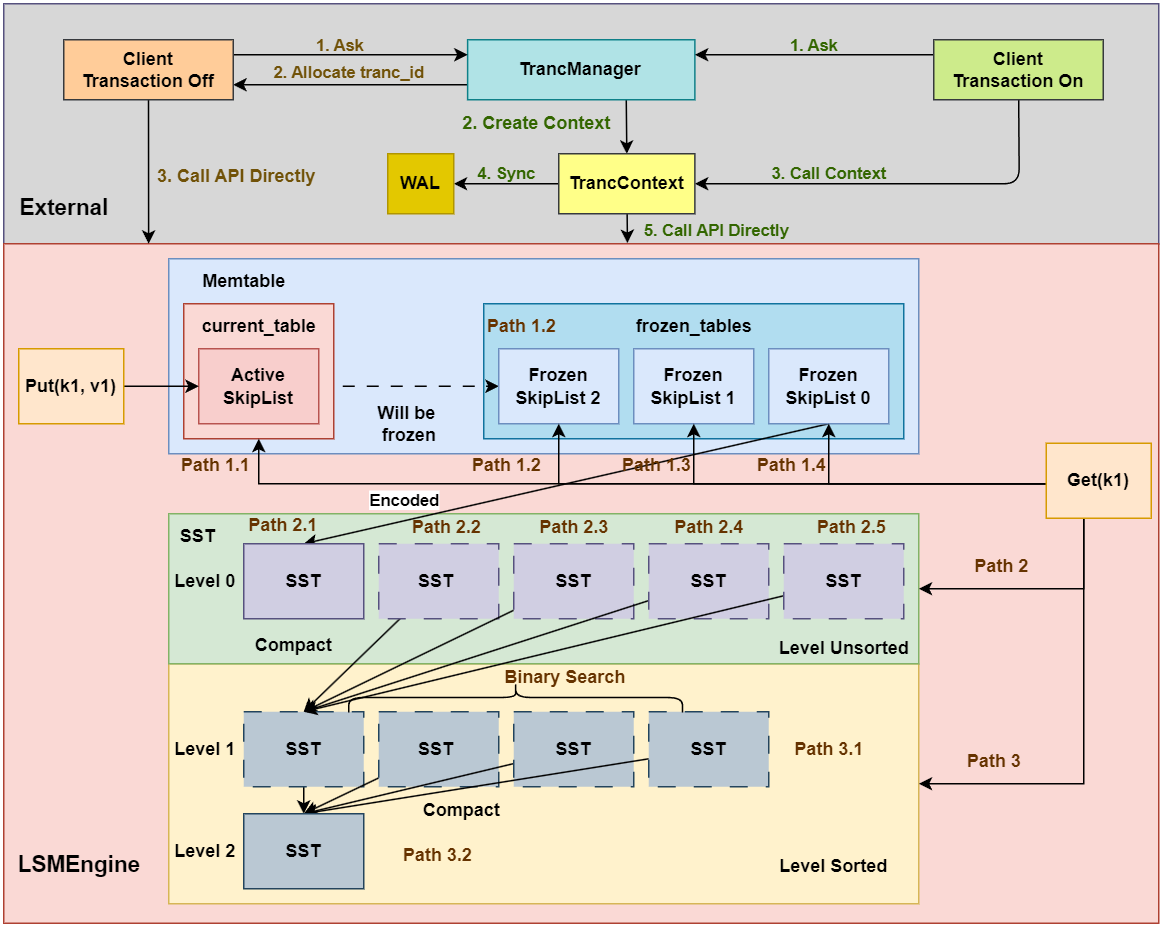
相比之前实现的LSM Engine的基础部分的架构, 这里新增了TrancManager、WAL、TrancContext杰哥模块, 其中TrancManager用于管理事务, WAL用于持久化事务操作, TrancContext用于与客户端进行直接交互。
2 KV存储中的事务
2.1 事务介绍
在数据库系统中,事务(Transaction)是指一组原子性操作的执行单元,需要满足ACID特性。这里简单介绍下ACID的基本性质:
| 特性 | 定义 | 技术实现 | KV存储中的特殊表现 |
|---|---|---|---|
| 原子性 (Atomicity) | 事务内的操作要么全部成功,要么全部失败,不存在中间状态。 | - WAL(Write-Ahead Logging) - 两阶段提交(2PC) - 操作回滚日志 | - 单键操作天然原子 - 跨键原子性需显式事务(如批量提交) - LSM-Tree依赖WAL保证崩溃恢复 |
| 一致性 (Consistency) | 事务执行后数据库必须保持预设的业务规则(如唯一性、完整性约束)。 | - 关系型:外键、触发器 - 声明式约束(DDL) - 事务回滚机制 | - 业务逻辑一致性需应用层实现 |
| 隔离性 (Isolation) | 并发事务相互隔离,避免脏读、不可重复读、幻读。 | - 锁机制(悲观锁) - MVCC(多版本并发控制) - 快照隔离(Snapshot Isolation) | - 通常采用乐观锁(版本号校验) - 全局时间戳实现快照隔离 - 弱隔离级别常见(如Read Committed) |
| 持久性 (Durability) | 事务提交后,数据永久存储,即使系统崩溃也不丢失。 | - 同步刷盘(fsync)- 副本复制(Replication) - 冗余存储(如RAID) | - LSM-Tree依赖SSTable落盘 - 内存数据需通过WAL持久化 - 异步刷盘可能牺牲部分持久性(如Redis AOF) |
在这四个基本性质中, KV存储由于数据较为简单, 不存在类似关系型数据库中的外键、触发器、声明式约束等复杂业务规则, 因此一致性是比较容易实现的,基本上你实现了一致性、隔离性,一致性就自然满足了,这里我们探讨下其他几个形状在KV存储中的实现逻辑:
- 原子性:通过批量化操作即可, 可以将一个事务的操作先暂存起来, 在提交时统一应用到存储引擎的状态机中。
- 隔离性:这里涉及到隔离级别, 会在后面统一介绍。
- 持久性:
LSM-Tree的持久化依赖SSTable落盘,但我们插入一些数据后, 这些数据肯定优先存在于内存中, 在内存容量达到阈值后才会刷盘, 为保证持久性, 可以用以下两个方案- 事务提交后强制刷盘到
SST, 但这样可能导致刷入的L0 SST大小过小, 加大了L0 SST合并时的计算量(后续章节介绍compact) - 事务提交时先将操作写入
WAL(Write-Ahead Logging), 同时存储引擎维护刷入SST的最大事务序号, 在重启或崩溃恢复时根据WAL重放操作(后续会介绍)
- 事务提交后强制刷盘到
2.2 隔离级别
2.2.1 隔离级别的定义与分类
在并发事务场景下,隔离性通过不同的隔离级别实现不同程度的可见性控制。我们先回顾下关系型数据库中的隔离级别:
这里如果对这些隔离级别不熟悉, 建议先学下数据库的课程
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(Non-Repeatable Read) | 幻读(Phantom Read) | 典型实现方案 |
|---|---|---|---|---|
| 读未提交 | 允许 | 允许 | 允许 | - 无版本控制 - 直接读取内存最新值 |
| 读已提交 | 禁止 | 允许 | 允许 | - 单版本快照 - 每次读获取最新提交版本 |
| 可重复读 | 禁止 | 禁止 | 允许 | - 多版本快照 - 事务级版本锚定(如MySQL InnoDB的MVCC) |
| 可串行化 | 禁止 | 禁止 | 禁止 | - 严格锁机制 - 冲突范围检测(如FoundationDB) |
注:快照隔离下幻读仍可能发生,但可通过追加范围锁避免
2.2.2 KV存储中事务冲突和隔离级别的案例
在LSM-Tree结构的KV存储中,我们举一个例子说明隔离级别和实物冲突的联系:
在下面的场景时序图, 事务按照创建的时间从小大大分配ID, 在这个
| Timeline | 事务A (ID=100) | 事务B (ID=101) | Key1状态 |
|---|---|---|---|
| T0 | Begin | Version=0 (初始值) | |
| T1 | Read Key1 (Version=0) | Begin | |
| T2 | Modify Key1→ValueA | Read Key1 (Version=0) | |
| T3 | Modify Key1→ValueB | ||
| T4 | Commit ✅ (Version=1) | Version=1 (ValueB) | |
| T5 | Attempt Commit ❌ | 检测到Key1已更新 |
在这个例子中, 更早创建的事务A和和更晚创建的事务B在读写了同一个Key1, 事务B先提交, 并且更新了Key1的值为ValueB, 事务A在提交后, 数据库中面临这样的问题: 以哪一个版本的修改为准?
以上问题就是一种事务冲突,在KV存储中,事务冲突的解决方式直接取决于隔离级别的设计。以下是不同隔离级别的处理差异:
| 隔离级别 | 事务A提交结果 | 原因 | 最终Key1值 |
|---|---|---|---|
| 读未提交 | ✅ 成功 | 允许覆盖未提交数据,但导致事务B的修改丢失(违反原子性) | ValueA |
| 读已提交 | ❌ 中止 | 检测到Key1已提交新版本(Version=1 > 事务A的起始版本) | ValueB |
| 可重复读 | ❌ 中止 | 事务A的读快照锁定Version=0,但写冲突仍存在 | ValueB |
| 可串行化 | ❌ 中止 | 通过范围锁阻止事务B写入,或强制事务串行执行 | ValueB |
以上是put时是事务冲突, 基于这个案例, 同时有2个事务再去读取key1:
假设初始时刻
Key1 = Value0
| Timeline | 事务A (ID=100) | 事务B (ID=101) | 事务C (ID=102) | 事务D (ID=103) |
|---|---|---|---|---|
| T0 | Begin | Key1 = Value0 (初始值) | Key1 = Value0 (初始值) | |
| T1 | Read Key1 | Begin | ||
| T2 | Modify Key1→ValueA | Begin | ||
| T3 | Read Key1 (Version=❓) | |||
| T4 | Read Key1 | |||
| T5 | Modify Key1→ValueB | |||
| T6 | Attempt Commit ❓ | |||
| T7 | Begin | |||
| T8 | Read Key1 (Key1=❓) | Read Key1 (Key1=❓) | ||
| T9 | Attempt Commit ❓ | |||
| T10 | Read Key1 (Key1=❓) | Read Key1 (Key1=❓) |
这个场景下, 在事务A和B操作时, 另外还存在2个事务C和D在读取key1的值, 事务C和D的读取结果是仍然取决于隔离级别:
1. 读未提交(Read Uncommitted)
允许读取未提交的中间值(包括可能回滚的脏数据)。
| 事务 | T3(C读取) | T8(C/D读取) | T10(C/D读取) | 事务提交结果 | 结果解释 |
|---|---|---|---|---|---|
| A | - | - | - | ✅ 成功 | 不检测写冲突,直接覆盖事务B的提交(Key1=ValueA) |
| B | - | - | - | ✅ 成功 | 事务B先提交(Key1=ValueB),但被事务A覆盖 |
| C | ValueA | ValueB | ValueA | - | T3读取事务A未提交的ValueA;T8时事务B已经提交,读ValueB;T10事务A提交后读ValueA |
| D | - | ValueB | ValueA | - | T8时事务A未提交,读ValueB;T10事务A提交后读ValueA |
最终Key1值:ValueA(事务A覆盖事务B)
风险:事务B的合法提交被覆盖,数据一致性被破坏。
2. 读已提交(Read Committed)
仅读取已提交的数据,但同一事务内多次读取结果可能不同。
| 事务 | T3(C读取) | T8(C/D读取) | T10(C/D读取) | 事务提交结果 | 结果解释 |
|---|---|---|---|---|---|
| A | - | - | - | ✅ 成功 or ❌中止 | 只确保读取时的数据是提交的, 但不确保提交时没有冲突, 取决于具体的实现 |
| B | - | - | - | ✅ 成功 | 事务B提交成功(Key1=ValueB) |
| C | Value0 | ValueB | ValueA | - | T3时事务A/B均未提交,读Value0;T8时事务B已提交,读ValueB, 最后T10时事务A提交,读ValueA |
| D | - | ValueB | ValueA | - | T8时事务B已提交,读ValueB, 最后T10时事务A提交,读ValueA |
最终Key1值:ValueA(事务A覆盖事务B)
风险:事务B的合法提交被覆盖,数据一致性被破坏。
相较于前者的优化: 读取的数据一定是已经提交的数据
3. 可重复读(Repeatable Read)
基于首次读取时的值锚定,保证多次读取结果一致。
| 事务 | T3(C读取) | T8(C/D读取) | T10(C/D读取) | 事务提交结果 | 结果解释 |
|---|---|---|---|---|---|
| A | - | - | - | ❌ 中止 | 提交时检测到Key1已被事务B修改 |
| B | - | - | - | ✅ 成功 | 事务B提交成功(Key1=ValueB) |
| C | Value0 | Value0 | Value0 | - | 事务C首次读取锚定Value0,后续读取强制复用 |
| D | - | ValueB | ValueB | - | 事务D首次读取时事务B已提交,锚定ValueB |
最终Key1值:ValueB
实现难点:需在内存中维护事务首次读取的键值锚定表,防止Compaction清理旧版本。
5. 可串行化(Serializable)
通过锁机制强制事务串行执行,完全禁止并发冲突。
| 事务 | T3(C读取) | T8(C/D读取) | T10(C/D读取) | 事务提交结果 | 结果解释 |
|---|---|---|---|---|---|
| A | - | - | - | ❌ 中止 | 事务C持有Key1的共享锁,事务A尝试获取排他锁时被阻塞,最终超时中止 |
| B | - | - | - | ✅ 成功 | 事务B在事务C释放锁后获取排他锁并提交 |
| C | Value0 | Value0 | Value0 | - | 事务C持有共享锁,保证读取一致性 |
| D | - | ValueB | ValueB | - | 事务D在事务B提交后读取ValueB |
最终Key1值:ValueB
锁竞争时序:事务C的共享锁阻塞事务A/B,事务B在事务C释放锁后提交。
通过这个案例, 我们可以复习下MVCC在读已提交和可重复读的区别:
- 读已提交: 读取时,快照基于当前这一次操作的时间
- 可重复读: 读取时,快照基于事务创建的时间
3 WAL简单介绍
WAL(Write-Ahead Logging)是一种常用的日志记录机制,用于确保在系统崩溃或故障恢复时,数据的一致性和完整性。WAL的核心思想是:在执行数据修改操作之前,首先将修改操作记录到日志中,然后再对数据进行修改。这样,即使系统在修改数据的过程中崩溃,也可以通过日志中的记录来恢复数据。
WAl主要是一种思想, 具体的日志编码格式、存储方式、检查恢复方式在不同数据库中差异很大,我们会在Lab 5.3中对本实验项目的WAL设计进行详细讲解。
阶段1-事务基础功能
本阶段要求实现事务的基本功能,包括事务的提交和回滚,并在其中实现事务不同隔离级别下的ACID特性。
具体来说, 你首先需要实现一个事务管理器, 这个事务管理器负责事务id的生成、事务上下文的分配。
其次,你需要实现事务上下文的CRUD接口, 事务上下文可以看做一个句柄, 其就是CLient直接操作的对象, 提供包括get、put、remove、commit、abort等接口。
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
2# Lab 5.1 事务基础功能
1 本KV引擎的MVCC和事务设计
通过事前的MVCC运行机制的分析可知, 在可重复读级别下, 我们需要记录这个事务开始的时间, 其实只需要记录这个事务的id就可以了, 因为我们可以设计一个事务管理器, 使得事务开始的时间严格按照事务id排序.
另一方面, 如果是读已提交, 我们需要按理说需要记录每个读操作的时间, 但是实际上, 我们的KV存储引擎是追加写入的, 我们本身读取的相同key就是按照最近时间读取的, 不需要额外记录本次操作的时间戳。换句话说,假设你遍历整个存储引擎的键值对, 其都是按照插入时间从近到久排序的。
故我们首先需要在键值对中记录事务id, 你应该在之前的Lab中已经实现了, 只是那是你不知道其具体的含义:
同时, 你现在应该也明白了我们为什么需要在每个SST中记录事务id的范围, 这样我们才能在查找指定事务的记录时能够通过SST的元数据快速定位到对应的SST文件:
2 代码修改
现在,我们需要对之前的Lab中涉及到事务操作的函数进行修改, 其实也就是参数列表中包含了tranc_id或者max_tranc_id的函数进行逻辑补全。
本章你需要修改的代码文件:
- 之前
Lab中所有涉及tranc_id的函数
注意, 如果
tranc_id == 0, 表示当前操作没有开启事务功能, 你的执行逻辑相当于事务不存在
2.1 SkipList 部分修改
2.1.1 put
之前的Skiplist中, 你的实现思路可能是这样的:
- 定位到指定位置
- 判断是否需要插入
key不存在则插入key存在则更新
现在而言, 以上的逻辑就错误了, 因为之前旧的键值对的记录也需要保留, 其可能会被比当前事务id更小的事务使用, 因此这里就不能进行原位更新了, 而是应该插入一个新的键值对, 同时保留旧的键值对。
你可以查看
SkiplistNode的比较运算符重载函数, 看看为什么如此设计
2.1.2 remove
由于LSM Tree中的remove就是将插入一个value为空的键值对进行标记, 因此这里的修改逻辑和put类似, 不再赘述。
2.1.3 get
加入事务属性后, get函数需要判断查询数据的可见性(也就是实现事务属性中的隔离性), 传入的tranc_id参数表示当前操作所属的事务的id, 因此查询的数据不能是比当前id更大的事务创建的, 如果找到了这样的数据, 你需要进行滤除或跳过。
新的查询逻辑步骤为:
查询时, 我们需要指定一个事务id, 通过id判断如何启用mvcc机制, 目前我们实现的隔离级别只有(读未提交, 读已提交, 可重复读)
- 若为0表示我们的事务隔离级别是
读未提交或读已提交(因为直接查询最新的记录即可, 不需要判断失误id是否合法) - 若指定的事务
id, 并指定了事务的隔离级别为可重复读, 则需要判断id是否合法, 若不合法, 则返回nullptr
本项目只在
commit后才将事务更改的键值对加入数据库, 否则只会暂存, 因此读已提交不需要判断事务id
2.1.4 iters_monotony_predicate && begin_preffix && end_preffix
其实这些范围查询等函数也需要进行修改, 但这不是必须的, 因为范围查询函数被上部组件MemTable包裹, 你可以选择在上层组件中统一实现事务id的滤除逻辑。因此这里的更改你可以选择性实现。
2.2 MemTable 部分修改
2.2.1 iters_preffix && iters_monotony_predicate
MemTable部分对范围查询是内存部分的最顶级组件了, 在上层就是整个LSM Tree的控制结构LSMEngine了, 因此推荐你在此处根据事务可见性原则对键值对进行滤除。
不过这里也有另一个方案, 我们的返回值类型是std::optional<std::pair<HeapIterator, HeapIterator>>, 因此你也可以在HeapIterator中实现类似的根据事务id的滤除逻辑, 这样上层组件就不需要额外处理了。如果你选择用这种方式的话, HeapIterator的运算符重载、之前标记的skip_by_tranc_id函数都需要更改。
HeapIterator中的更新是强烈推荐你实现的, 因为这个去重+排序的组件你可能会在其他地方进行复用, 因此实现其功能的完善有助于简化复用过程中的数据处理
2.2.2 其余接口
其余接口基本上是对底层Skiplist的封装, 因此你只要更新了Skiplist的接口, MemTable的接口则只需要做简单的参数传递, 不需要额外的更新。
2.3 Block 部分修改
2.3.1 add_entry
之前的src/block/block.cpp中的Block::add_entry函数需要写入tranc_id, 当然你大概率已经写入了, 虽然你当时不知道这个tranc_id具体是干嘛的, 如果你之前已经完成了tranc_id的编码, 请跳过这一部分。
除了Block之外, SST的文件编码部分应该只是调用Block的接口, 因此你只需要修改Block
2.3.2 adjust_idx_by_tranc_id
这是之前Lab中标记的一个遗留函数:
int Block::adjust_idx_by_tranc_id(size_t idx, uint64_t tranc_id) {
// TODO Lab5.1 找到最接近 tranc_id 的键值对的索引位置
return -1;
}
这里说明下这个函数的作用:
- 你进行查询定位时发现
idx位置的key是你的目标 - 但
idx位置的tranc_id并不愉参数匹配
因此你需要调用adjust_idx_by_tranc_id函数, 找到最接近tranc_id的键值对索引位置。当然, 这里的最接近不能大于指定的事务id。这个辅助函数有助于你实现新的get_idx_binary函数。
2.3.3 get_idx_binary
get_idx_binary函数用于二分查找定位key在Block中的索引位置, 你需要修改这个函数, 使其能够支持tranc_id的滤除。(可以借助刚刚实现的adjust_idx_by_tranc_id函数)
2.3.4 get_monotony_predicate_iters && iters_preffix
这里的get_monotony_predicate_iters函数需要修改, 使其能够支持tranc_id的滤除。不过和SKiplist中的范围查询类似, Block::get_monotony_predicate_iters会被SST部分的范围查询接口调用, 因此你也可以选择在上层统一实现根据事务id的滤除工作, 这里的实现是可选的。
2.5 各类迭代器
我们实现了多种迭代器都需要在其自增运算符中实现事务id的滤除逻辑, 因此你需要更新的迭代器包括:
HeapIteratorBlockIteratorSSTIteratorConcactIteratorLevelIteratorTwoMergeIterator
当然, 你不一定需要再每一个迭代器中都实现类似的逻辑, 以TwoMergeIterator为例, 如果其中的it_a和it_b都实现了基于事务id的滤除功能, 那么TwoMergeIterator就不需要再实现一次了。
不过这里
it_a和it_b都是基类BaseIterator的指针, 因此你如果想要少实现这个逻辑, 需要好好地进行设计, 提供其是否实现了滤除逻辑的接口。当然,你在所有迭代器全部都实现一次这个滤除逻辑是最保险的做法。
2.6 Engine部分修改
LSMEngine的大部分接口都是对下层组件(包括MemTable、SST等)的封装, 因此你只需要想对应的接口传递正确的tranc_id即可, 不需要额外的修改。
这里只有范围查询(谓词查询)需要你注意, 这里是对包括谓词查询、前缀查询等接口的最顶层封装, 你需要在上层组件中实现根据事务id的滤除逻辑。
2.7 其余部分修改
作者列出了大部分在引入事务id后需要修改的代码部分, 但由于每个人在之前的Lab中实现的方案不同, 因此你可能还需要在其他地方进行一些修修补补。
TODO: 这一部分给参与者的自由度稍高, 引导可能也弱了一点, 后续版本更新的指导书应该加以改正
3 测试
由于事务功能的耦合度较高, 因此现在还没有办法进行单元测试, 你可以按照自己的需要编写测试用例进行测试, 测试用例的编写思路和之前的Lab类似, 你可以参考src/test中的测试用例进行编写。
不过别忘了我们在Lab 1.3中先搁置的SkipListTest.TransactionId单元测试, 此时你应该可以通过这个单元测试测例。
TODO: 后续版本中补全这里的阶段性测试, 而不是2个Lab完成后才有一个大测试
Lab 5.2 引入事务 ID
之前我们已经对各个组件的接口进行了统一, 添加了tranc_id这个事务id参数, 接下来这个章节, 我们将介绍顶层的事务设计, 即事务id是如何生成的, 实现相关的事务管理器。
1 事务的设计思想
我们先给出一个完成后的demo, 演示我们的事务设计是如何工作的, 代码如下:
#include "../include/lsm/engine.h"
#include <iostream>
#include <string>
int main() {
// create lsm instance, data_dir is the directory to store data
LSM lsm("example_data");
// put data
lsm.put("key1", "value1");
// Query data
auto value1 = lsm.get("key1");
std::cout << "key1: " << value1.value() << std::endl;
// transaction
auto tranc_hanlder = lsm.begin_tran();
tranc_hanlder->put("xxx", "yyy");
tranc_hanlder->put("yyy", "xxx");
tranc_hanlder->commit();
auto res = lsm.get("xxx");
std::cout << "xxx: " << res.value() << std::endl;
lsm.clear();
return 0;
}
这里我们可以通过一个begin_tran函数获取一个事务的处理句柄, 然后通过这个句柄进行增删改查操作, 最后通过commit或abort函数完成提交事务或终结事务的流程.
现在我们要完成的就是接受begin_tran的事务管理器. 这里有一些设计问题我们需要提前明确:
begin_tran获取的事务句柄肯定会分配一个事务id, 那么没有开启事务的put/get/remove操作的事务id是什么呢?begin_tran进行增删改查的操作如何保证不同事务的隔离性?
首先回答第一个问题, 我们可以使用一个全局的atomic变量来作为事务id, 这个变量在每次调用begin_tran或put/get/remove时自增, 这样就可以保证每个事务或单次操作都有一个唯一的tranc_id(这里的tranc_id和事务id是同义词). 换句话说, 普通的put/get/remove就是操作数量为1的简单事务。
然后是第二个问题,这实际上取决于我们的事务隔离级别:
Read Uncommitted: 允许读取未提交的数据, 也就是脏读. 这种情况下, 我们可以将事务的句柄(案例代码中的tranc_hanlder)进行增删改查的数据直接写入到memtable中, 这样就可以让其他的事务可以从memtable中读取到未提交的数据, 速度肯定很快. 但是这里有一个场景需要尤其注意, 就是我们事务rokkback(或者是abort)时, 必须撤销已经写入到memtable的数据, 因此这里需要我们记录事务的操作记录和以前的历史记录, 然后在abort时, 将memtable中的数据进行回滚.Read Committed: 允许读取已提交的数据, 也就是不可脏读. 这种情况下, 我们可以将事务的句柄(案例代码中的tranc_hanlder)进行增删改查的数据暂存到句柄的上下文, 因此其他事务从memtable中是查不到这个事务未提交的数据的, 但这个事务自身查询时可以从自己的上下文中读取到未提交的数据.Repeatable Read: 在Read Committed的基础上解决了不可重复读的问题, 也就是在同一个事务中, 多次读取同一数据的结果是一样的. 这种情况下, 我们可以将每次get的数据同样暂存到句柄的上下文, 后续查询相同的key时, 从上下文中读取到相同的数据.Serializable: 这个这个事务隔离级别我们在关系型数据库中是进一步解决幻读现象的, 例如: 在Repeatable Read隔离级别下,事务A读取了年龄>30的员工,得到10条记录。此时事务B插入了一个年龄31的新员工并提交。事务A再次读取同样的条件,可能会看到11条记录(幻读)。但在Serializable隔离级别下,事务B的插入会被阻塞或者事务A的两次读取结果保持一致,避免幻读。在我们的KV数据库中, 我们只需要保证事务提交时进程冲突检查、且按照事务id的顺序依次提交即可(虽然这样性能很低)。
2 事务管理器的设计方案
2.1 组件关系设计
还记得我们之前实现的LSm和LSMEngine吗? 当时我们将LSMEngine包裹在LSM中, LSMEngine中封装了memtable, sst等组件, 我们却进一步将其封装在LSM中, 这样的目的就是在后续中加入其他同级别的组件, 例如本章的事务管理器, LSM的定义为:
class LSM {
private:
std::shared_ptr<LSMEngine> engine;
std::shared_ptr<TranManager> tran_manager_;
public:
// ...
};
这里我们对LSMEngine和TranManager都使用了shared_ptr进行封装。LSMEngine我们之前已经介绍过了,而TranManager就是本章我们要实现的事务管理器。
2.1 功能1-分配事务 id
首先事务管理器的基础职责之一就是分配事务id, 我们看看其中一个put接口:
class TranManager : public std::enable_shared_from_this<TranManager> {
public:
// ...
uint64_t getNextTransactionId();
// ...
private:
mutable std::mutex mutex_;
std::shared_ptr<LSMEngine> engine_;
std::shared_ptr<WAL> wal; // 暂时忽略
std::string data_dir_;
// std::atomic<bool> flush_thread_running_ = true; // 废弃的设计方案
std::atomic<uint64_t> nextTransactionId_ = 1;
std::atomic<uint64_t> max_flushed_tranc_id_ = 0;
std::atomic<uint64_t> max_finished_tranc_id_ = 0;
std::map<uint64_t, std::shared_ptr<TranContext>> activeTrans_;
FileObj tranc_id_file_;
};
void LSM::put(const std::string &key, const std::string &value) {
auto tranc_id = tran_manager_->getNextTransactionId();
engine->put(key, value, tranc_id);
}
这里顺带补充我们的查询接口的设计, 你可以看到, 在没有开启事务的情况下, 即时是一次简单的put操作都会分配一个事务id, 因此这里的tranc_id是必须的, 其并不独属于我们的事务模块, 只是简单的put/get/remove操作数量只有一个而已(或者是一次性的batch接口, 总之不会有多步骤的操作)
2.2 功能2-分配事务上下文
回顾我们之前的Demo:
auto tranc_hanlder = lsm.begin_tran();
这里的begin_tran会返回一个事务上下文(或者叫事务句柄也行), 我们可以在这个上下文中进行增删改查操作, 然后通过commit或abort函数完成提交事务或终结事务的流程. 我们看看这个上下文的定义:
class TranContext {
friend class TranManager;
public:
TranContext(uint64_t tranc_id, std::shared_ptr<LSMEngine> engine,
std::shared_ptr<TranManager> tranManager,
const enum IsolationLevel &isolation_level);
void put(const std::string &key, const std::string &value);
void remove(const std::string &key);
std::optional<std::string> get(const std::string &key);
// ! test_fail = true 是测试中手动触发的崩溃
bool commit(bool test_fail = false);
bool abort();
enum IsolationLevel get_isolation_level();
public:
std::shared_ptr<LSMEngine> engine_;
std::shared_ptr<TranManager> tranManager_;
uint64_t tranc_id_;
std::vector<Record> operations;
std::unordered_map<std::string, std::string> temp_map_;
bool isCommited = false;
bool isAborted = false;
enum IsolationLevel isolation_level_;
private:
std::unordered_map<std::string,
std::optional<std::pair<std::string, uint64_t>>>
read_map_;
std::unordered_map<std::string,
std::optional<std::pair<std::string, uint64_t>>>
rollback_map_;
};
可以看到, 事务上下文主要包含以下内容:
tranc_id_: 事务idengine_:LSM引擎的指针, 需要保证其在自身生命周期内有效tranManager_: 事务管理器的指针, 需要保证其在自身生命周期内有效operations: 事务操作记录, 也就是后续转化为WAL日志的内容temp_map_: 事务上下文中的临时数据, 主要是实现事务的隔离性, 例如Read Committed和Repeatable Read隔离级别下, 我们需要将get的数据暂存到这个临时数据中, 避免被其他事务读取到未提交的数据rollback_map_: 事务回滚记录, 主要用于事务的回滚
2.3 功能3-事务状态的维护
我们继续看我们定义的事务管理器的其他成员:
```cpp
class TranManager : public std::enable_shared_from_this<TranManager> {
private:
mutable std::mutex mutex_;
std::shared_ptr<LSMEngine> engine_;
std::shared_ptr<WAL> wal; // 暂时忽略
std::string data_dir_;
// std::atomic<bool> flush_thread_running_ = true; // 废弃的设计方案
std::atomic<uint64_t> nextTransactionId_ = 1;
std::atomic<uint64_t> max_flushed_tranc_id_ = 0;
std::atomic<uint64_t> max_finished_tranc_id_ = 0;
std::map<uint64_t, std::shared_ptr<TranContext>> activeTrans_;
FileObj tranc_id_file_;
};
这里我们关注几个std::atomic<uint64_t类型的原子变量, 他们的作用和含义解释如下:
- 负责记录当前事务完成状态:
max_flushed_tranc_id_: 最大的已经刷入sst中的事务max_finished_tranc_id_: 最大的已经完成的事务(但数据可能还存在于内存中)nextTransactionId_: 下一个分配事务的id
- 负责事务状态的持久化操作
这里特别进行说明, 为什么要负责是事务的持久化操作, 因为我们后续会实现WAL(Write Ahead Log), 这个日志会记录每次的操作, 当我们的数据库崩溃后重启时, 会根据WAL中的操作记录进行恢复, 这里的操作记录是指put、remove等操作, 但是我们需要在重启时知道哪些操作是已经完成的, 哪些操作是未完成的, 因此我们需要在WAL中记录每个事务的状态, 这个状态就是max_flushed_tranc_id_, 因此在重放WAL的操作时, 我们需要根据这个状态来判断哪些操作是已经完成的, 哪些操作是未完成的。
3 代码实现
这里我们进入今天的主题, 如何实现不同隔离级别下的事务操作。
本小节实验中,你需要修改的代码为:
src/lsm/engine.cpp(Optional, 你也许会自行设计LSM类中TranManager的初始化逻辑)src/lsm/transation.cppinclude/lsm/transaction.h
3.1 事务上下文的创建和分配
3.1.1 事务上下文的构造函数
这里我们从事务上下文的生命周期的历程逐步实现其关键的接口, 首先是构造函数:
TranContext::TranContext(uint64_t tranc_id, std::shared_ptr<LSMEngine> engine,
std::shared_ptr<TranManager> tranManager,
const enum IsolationLevel &isolation_level) {
// TODO: Lab 5.2 构造函数初始化
}
3.1.2 事务上下文的分配
有了TranContext的构造函数中, 我们可以在TranManager::new_tranc接受外部请求完成事务上下文的分配:
std::shared_ptr<TranContext>
TranManager::new_tranc(const IsolationLevel &isolation_level) {
// TODO: Lab 5.2 事务上下文分配
return nullptr;
}
介于之前已经进行了详细的理论介绍, 这里就不过多介绍你需要进行哪些元数据的记录操作了。此外,类定义中的成员变量你不一定需要全部使用,你可以按照自己的理解选择性地使用预定义的成员变量,也可以自行添加新的成员变量。
3.2 事务上下文的接口
接下来是本小节内容的最重要部分,事务上下文接口的实现。这里不同隔离级别的事务操作实现会有所不同,你需要根据不同的事务隔离级别完成不同的CRUD逻辑:
以下的接口在实现
WAL后, 你需要在实现接口时考虑WAL的持久化操作, 本实验中你暂时不需要考虑WAL的持久化操作。
3.2.1 put
void TranContext::put(const std::string &key, const std::string &value) {
// TODO: Lab 5.2 put 实现
}
这里有几个点需要你考虑:
- 事务的可见性设计:
put操作如何实现对其他事务的可见性?put操作如何实现对其他事务的隔离性?
- 回滚设计
- 如果事务最后需要回滚, 如何实现?
- 回滚是否需要额外的数据结构?
3.2.2 get
void TranContext::remove(const std::string &key) {
// TODO: Lab 5.2 remove 实现
}
由于remove本质上也是put, 因此这里的逻辑和put类似, 这里就不做过多解释了。
3.2.3 get
std::optional<std::string> TranContext::get(const std::string &key) {
// TODO: Lab 5.2 get 实现
return {};
}
这里需要考虑:
- 如果是
Read UnCommitted隔离级别, 需要考虑如何读取到最新的修改记录 - 如果是
Read Committed隔离级别, 需要考虑如何避免读取到未提交的数据 - 如果是
Repeatable Read隔离级别, 需要考虑如何避免不可重复读现象
3.2.4 commit
bool TranContext::commit(bool test_fail) {
// TODO: Lab 5.2 commit 实现
return true;
}
commit函数应该是这里最复杂的, 这里的重点就是实现事务提交时的冲突检测, 如果检测无冲突且WAL持久化成功(后续Lab的内容), 返回true表示成功提交, 否则返回false表示提交失败。
本实验的设计采用了类似乐观锁的思想, 所有事务的更新记录只有在提交时才会进行冲突检测, 其逻辑为:
- 如果隔离级别是
READ_UNCOMMITTED, 因为之前就已经将更改的数据写入了MemTable, 现在只需要直接写入wal一个Commit记录(目前不涉及, 可先跳过) - 如果隔离级别是
REPEATABLE_READ或SERIALIZABLE, 需要遍历所有的操作记录, 判断是否存在冲突, 如果存在冲突则终止事务, 否则将所有的操作记录写入wal中, 然后将数据应用到数据库中 - 完成事务数据同步到
MemTable后, 更新max_finished_tranc_id_并持久化数据
这里需要注意的是, 你在进行冲突检测时,
MemTable和SST部分此时应该是不允许写入的, 否则存在并发冲突。这里你的加锁行为可能是类似侵入式的做法(即手动对其他类的内部成员变量进行加锁)同样地, 这里设计
WAL的部分可以先跳过
3.2.5 abort
abort 方法用于回滚事务,具体的回滚逻辑取决于你之前对put函数的设计:
bool TranContext::abort() {
// TODO: Lab 5.2 abort 实现
return true;
}
这里同样用true表示成功回滚, 否则返回false表示回滚失败。
在
commit函数的冲突检测失败后, 也需要进行回滚操作, 不过其回滚是被动的而
abort函数是client主动发起的回滚操作
3.3 事务状态的维护
之前提到过, TranManager中定义了几个std::atomic<uint64_t>类型的原子变量, 这些变量用于记录事务的状态, 在事务的提交和回滚时, 需要更新这些变量的值, 以便在重启时进行恢复:
void TranManager::write_tranc_id_file() {
// TODO: Lab 5.2 持久化事务状态信息
}
void TranManager::read_tranc_id_file() {
// TODO: Lab 5.2 读取持久化的事务状态信息
}
void TranManager::update_max_finished_tranc_id(uint64_t tranc_id) {
// TODO: Lab 5.2 更新持久化的事务状态信息
}
void TranManager::update_max_flushed_tranc_id(uint64_t tranc_id) {
// TODO: Lab 5.2 更新持久化的事务状态信息
}
在你操作原子变量时可以不使用锁而实现并发安全性, 不过你需要了解内存顺序的概念
完成上面的持久化操作后, 你在存储引擎启动后也需要从持久化的文件中恢复这些元信息:
TranManager::TranManager(std::string data_dir) : data_dir_(data_dir) {
auto file_path = get_tranc_id_file_path();
// TODO: Lab 5.2 初始化时读取持久化的事务状态信息
}
试想, 你在第一次存储要求启动时进行了若干操作, 事务id已经分配到了100, 而之后你重启了数据库, 此时事务id如果又从0开始分配, 而不是从100开始分配, 会发生什么问题?
4 测试
现在除了崩溃恢复的部分外, 你应该可以通过所有的test_lsm的测试:
✗ xmake
[100%]: build ok, spent 0.595s
✗ xmake run test_lsm
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from LSMTest
[ RUN ] LSMTest.BasicOperations
[ OK ] LSMTest.BasicOperations (10 ms)
[ RUN ] LSMTest.Persistence
[ OK ] LSMTest.Persistence (1600 ms)
[ RUN ] LSMTest.LargeScaleOperations
[ OK ] LSMTest.LargeScaleOperations (17 ms)
[ RUN ] LSMTest.MixedOperations
[ OK ] LSMTest.MixedOperations (8 ms)
[ RUN ] LSMTest.IteratorOperations
[ OK ] LSMTest.IteratorOperations (9 ms)
[ RUN ] LSMTest.MonotonyPredicate
[ OK ] LSMTest.MonotonyPredicate (17 ms)
[ RUN ] LSMTest.TrancIdTest
[ OK ] LSMTest.TrancIdTest (8 ms)
[ RUN ] LSMTest.TranContextTest
[ OK ] LSMTest.TranContextTest (8 ms)
[ RUN ] LSMTest.Recover
unknown file: Failure
C++ exception with description "bad optional access" thrown in the test body.
阶段2-WAL和崩溃恢复
首先恭喜你进入了WAL与包括恢复的阶段, 这一阶段是我们本课程早轮子部分的最后一个阶段, 再之后就是偏向业务层的Redis协议兼容了。
本阶段你将学习到
WAL的编解码设计- 利用
WAL进行崩溃恢复的策略
本实验的崩溃恢复是一个简易的实现
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab2 git checkout your_branch git merge lab2如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
Lab 5.3 WAL日志编解码
之前我们已经完成了数据库内存中和编码文件中事务信息的融入, 现在我们还需要加上WAL与崩溃恢复的内容。
这一小节我们主要对WAL中的单条日志记录 (即Record) 进行编解码设计和实现。
1 Record 编码设计
1.1 WAL简介
这里首先简单介绍下WAL(预写式日志) , WAL(预写式日志) 是数据库系统中保障数据一致性和事务可靠性的核心技术,核心思想是“日志先行”——任何数据修改必须先记录到日志中,确保日志持久化后,才允许实际数据写入磁盘。这种机制解决了两个关键问题:一是保证已提交的事务不会因系统崩溃而丢失(持久性),二是确保事务要么完全生效、要么完全回滚(原子性)。
具体来说,当一个事务提交时,数据库会先将事务的修改操作(例如数据修改前后的值、事务状态等)按顺序写入日志文件,并强制将日志刷到磁盘存储。由于日志是顺序写入,相比随机修改数据页的I/O操作,这种设计大幅提升了性能。之后,数据库可以灵活地将内存中的脏页批量刷新到磁盘,减少磁盘操作次数。
如果系统崩溃,重启后可通过日志恢复数据。恢复分为两个阶段:Redo 阶段会重放所有已提交但未落盘的日志,确保事务修改生效;Undo 阶段则回滚未提交事务的部分修改,消除中间状态。为了加速恢复,数据库会定期创建检查点(Checkpoint),将当前内存中的脏页刷盘,并记录日志位置,这样恢复时只需处理检查点之后的日志。
WAL的优势不仅在于数据安全,还在于其高性能和可扩展性。例如,PostgreSQL、MySQL InnoDB等数据库依赖WAL实现事务和崩溃恢复;分布式系统(如Raft算法)也借鉴类似思想,通过日志复制保证一致性。不过,WAL的日志文件可能快速增长,需要定期清理或归档,且频繁刷盘可能带来性能损耗,因此在实际应用中需权衡同步/异步提交等策略。
1.2 文件格式设计
根据之前的介绍, 我们的WAL文件中需要满足如下功能:
- 描述事务的开始和结束
- 描述每次事务的操作内容
在KV存储引擎这个领域, WAL的设计已经比关系型数据库简单很多了, 因为其操作类型就只有简单的基于键值对的put/get/remove. 与之相反, 关系型数据库的WAL就复杂很多了, 还涉及到物理日志和逻辑日志的区别
在KV存储引擎中,WAL的设计需要满足简洁性和高效性。由于操作类型仅限于put、remove(get通常不涉及数据修改,因此无需记录),日志结构可以大幅简化。以下是具体的设计要点:
每个日志条目需包含以下核心信息:
- 事务标识(Transaction ID):唯一标识事务的ID,用于关联多个操作。
- 操作类型(Operation Type):如
PUT、REMOVE、GET、BEGIN、COMMIT、ABORT等。 - 键(Key):操作的键值。
- 值(Value):对于
PUT操作记录具体值; - 校验和(Checksum)(可选):用于验证日志条目的完整性(如CRC32)。
- 时间戳(可选):记录操作时间,用于多版本控制或冲突解决。
这样,我们可以通过每一个日志条目判断这个操作类型和数据、是哪一个事务进行操作。同时, 由于我们在上一章中将数据库的事务完成状态也进行了持久化, 因此在崩溃恢复时, 我们可以通过检查当前WAL条目的事务id和以刷盘的事务的状态进行对比, 来判断是否需要重放操作。
1.3 Record 代码概览
基于我们之前的描述, 我们来看看Record中每一类记录项的定义:
// include/wal/record.h
class Record {
private:
// 构造函数
Record() = default;
public:
// 操作类型枚举
static Record createRecord(uint64_t tranc_id);
static Record commitRecord(uint64_t tranc_id);
static Record rollbackRecord(uint64_t tranc_id);
static Record putRecord(uint64_t tranc_id, const std::string &key,
const std::string &value);
static Record deleteRecord(uint64_t tranc_id, const std::string &key);
// 编码记录
std::vector<uint8_t> encode() const;
// 解码记录
static std::vector<Record> decode(const std::vector<uint8_t> &data);
// ...
private:
uint64_t tranc_id_;
OperationType operation_type_;
std::string key_;
std::string value_;
uint16_t record_len_;
};
这里展示了几个关键的成员变量和成员函数, 这里的Record表示的就是WAL中的单个日志条目, 操作类型为OperationType, 通过OperationType可以判断其是否有key, value等附加数据信息。同时,我们通过静态成员函数createRecord, putRecord等构造类的实例。最后,encode和decode函数用于将记录转换为字节流和从字节流恢复记录。
这里的构造函数被标记为
private, 你需要使用createRecord等静态成员函数来构造Record的实例。
1.4 Record 文件格式
Record仅仅是内存中的一个类, 且其会因记录类型的不同导致占据的内存大小不同, 因此我们需要将采用某种编码格式将其序列化到磁盘上, 以便在崩溃恢复时能够从磁盘上恢复出Record。这里我们采用一种简单的序列化方式, 将每一个Record的长度和内容依次写入磁盘, 具体格式如下:
| record_len | tranc_id | operation_type | key_len(optional) | key(optional) | value_len(optional) | value(optional) |
这里, 当operation_type是CREATE, ROLLBACK, COMMIT时, 只需要记录tranc_id和operation_type即可, 其余的optional部分不存在, 当operation_type是PUT时, 需要记录tranc_id, operation_type, key, value; 当operation_type是DELETE时, 需要记录tranc_id, operation_type, key。’
每个条目的第一部分是record_len, 其记录了整个日志条目的长度(16位)。这里的编解码需要注意一下,encode函数是以单个Record为单位, 将其编码为字节流, 而decode函数是以字节流为单位, 将其解码为Record数组。
2 代码实现
现在你已经了解了Record的设计和编码格式, 接下来你需要实现Record的基础构造函数和编解码函数。
你需要修改的文件包括:
src/wal/record.cppinclude/wal/record.h(Optional)
2.1 构造函数
这里的构造函数其实是一系列静态函数, 其们会根据不同的操作类型构造不同的Record实例, 你需要实现这些静态函数:
Record Record::createRecord(uint64_t tranc_id) {
// TODO: Lab 5.3 实现创建事务的Record
return {};
}
Record Record::commitRecord(uint64_t tranc_id) {
// TODO: Lab 5.3 实现提交事务的Record
return {};
}
Record Record::rollbackRecord(uint64_t tranc_id) {
// TODO: Lab 5.3 实现回滚事务的Record
return {};
}
Record Record::putRecord(uint64_t tranc_id, const std::string &key,
const std::string &value) {
// TODO: Lab 5.3 实现插入键值对的Record
return {};
}
Record Record::deleteRecord(uint64_t tranc_id, const std::string &key) {
// TODO: Lab 5.3 实现删除键值对的Record
return {};
}
之所以这样设计, 是因为不同类型的
Record的成员变量数量不同, 比如CREATE类型的Record只需要tranc_id和operation_type两个成员变量, 而PUT类型的Record则需要tranc_id,operation_type,key,value四个成员变量, 因此我们通过静态函数来构造不同的Record实例, 这样可以避免构造函数的参数过多。
2.2 编解码函数
接下来是接触的编解码函数, 这里你只需要编解码成字节数组即可, 文件IO相关操作你在下一个Lab实现:
std::vector<uint8_t> Record::encode() const {
// TODO: Lab 5.3 实现Record的编码函数
return {};
}
std::vector<Record> Record::decode(const std::vector<uint8_t> &data) {
// TODO: Lab 5.3 实现Record的解码函数
return {};
}
TODO: 初版实验代码中,
encode和decode是针对单个Record进行的, 后续版本应进行改进, 使编解码的数据以std::vector<Record>为单位, 这样可以避免内存的频繁分配和释放。
3 测试
本小节没有单元测试, 你在完成下一小节后会有统一的单元测试。
Lab 5.4 WAL 运行机制
上一小节的Lab你已经实现了单条WAL记录Record的设计, 这一小节我们将整合Record, 完成WAL组件的设计。
1 WAL 文件设计
首先,WAL文件的内容本质上分就是Record的数组。但这里却不仅仅是对Record的简单存储,而是需要考虑WAL文件的时效性对其进行清理, 以及写入文件的方式。设计要点包括:
- 刷盘的高效性
- 我们都知道,当一个事务完成时,必须保证其对应的
WAL记录被写入磁盘,否则在系统崩溃时,事务的修改将无法恢复。因此,WAL记录的写入必须保证原子性。但保证原子性的开销是什么呢? 你需要保证你的WAL组件写入磁盘时的效率(例如设置缓冲区, 或者是异步刷盘)
- 我们都知道,当一个事务完成时,必须保证其对应的
- 过时
WAL记录的清理- 事务操作的记录都会记录到
WAL文件中进行持久化, 但其本身对数据库的操作也会随着刷盘形成SST完成真正的持久化, 此时之前的WAL记录已经不再需要, 需要被清理。因此,WAL文件需要有一个机制来清理过时的WAL记录。
- 事务操作的记录都会记录到
2 WAL 组件的设计思路
老规矩, 我们先看看WAL组件的定义:
class WAL {
public:
WAL(const std::string &log_dir, size_t buffer_size,
uint64_t checkpoint_tranc_id, uint64_t clean_interval,
uint64_t file_size_limit);
~WAL();
static std::map<uint64_t, std::vector<Record>>
recover(const std::string &log_dir, uint64_t checkpoint_tranc_id);
// 将记录添加到缓冲区
void log(const std::vector<Record> &records, bool force_flush = false);
// 写入 WAL 文件
void flush();
void set_checkpoint_tranc_id(uint64_t checkpoint_tranc_id);
private:
void cleaner();
void cleanWALFile();
void reset_file();
protected:
std::string active_log_path_;
FileObj log_file_;
size_t file_size_limit_;
std::mutex mutex_;
std::vector<Record> log_buffer_;
size_t buffer_size_;
std::thread cleaner_thread_;
uint64_t checkpoint_tranc_id_; // 已安全刷盘的最大事务id(原 max_finished_tranc_id_)
uint64_t clean_interval_;
};
注意: 原
lab版本中该字段名为max_finished_tranc_id_,当前版本已重命名为checkpoint_tranc_id_,语义相同——记录已经安全持久化到 SST 的最大事务 id,低于此 id 的 WAL 记录可以被清理。
这里我们定义了WAL组件的几个关键成员变量和接口, 其设计思路为:
active_log_path_: 当前写入的WAL文件路径log_file_: 当前写入的WAL文件对象file_size_limit_:WAL文件的大小限制(选择性使用)log_buffer_:WAL记录的缓冲区(选择性使用)buffer_size_: 缓冲区的大小(选择性使用)cleaner_thread_: 清理线程(选择性使用)
这里的成员变量只是给你一些提示, 你不一定需要使用, 但这些成员函数是必须的:
WAL: 构造函数, 初始化WAL组件~WAL(): 析构函数, 关闭WAL组件, 你需要保证析构时所有WAL内容都被持久化recover: 恢复WAL文件, 返回所有未完成的WAL记录(这是下一个Lab的内容)log: 将记录添加到缓冲区或者刷入磁盘 (取决于你的策略选择性使用)flush: 强制将缓冲区中的记录刷入磁盘 (取决于你的策略选择性使用)cleaner: 清理旧数据的线程(选择性使用)
3 代码实现
src/wal/wal.cppinclude/wal/wal.h(Optional)
3.1 WAL 组件的接口实现
你只需要实现下面几个必须实现的函数, 你可以选择性地添加其他功能函数:
WAL::WAL(const std::string &log_dir, size_t buffer_size,
uint64_t checkpoint_tranc_id, uint64_t clean_interval,
uint64_t file_size_limit) {
// TODO Lab 5.4 : 实现WAL的初始化流程
}
WAL::~WAL() {
// TODO Lab 5.4 : 实现WAL的清理流程
}
void WAL::log(const std::vector<Record> &records, bool force_flush) {
// TODO Lab 5.4 : 实现WAL的写入流程
}
// commit 时 强制写入
void WAL::flush() {
// TODO Lab 5.4 : 强制刷盘
// ? 取决于你的 log 实现是否使用了缓冲区或者异步的实现
}
void WAL::cleaner() {
// TODO Lab 5.4 : 实现WAL的清理线程
}
3.2 TranContext 逻辑更新
之前你实现的TranContext的put, get,remove, commit和abort等函数中, 你的实现仅仅是将操作记录记录在了operations数组中(甚至没有记录, 因为那时你可能不知道这个成员变量是做什么的)。
现在你已经实现的WAL的刷盘接口, 因此你需要更新TranContext的这些函数, 使其能够将操作记录写入WAL文件中。不过这里你需要尤其注意冲突检测的问题, 不同的策略的冲突检测实现难度大不相同
commit时统一进行冲突检测并写入WAL文件, 这种方式实现最简单, 但性能较差put,get,remove时进行就分批写入WAL文件, 这种方式实现需要你在从图检测时需要考虑WAL文件中的记录的有效性控制, 实现难度较大, 但性能较好
你在更新TranContext的put, get,remove, commit和abort等函数中, 下面这个辅助函数也许对你有用:
bool TranManager::write_to_wal(const std::vector<Record> &records) {
// TODO: Lab 5.4
return true;
}
4 测试
WAL组件的测试代码在test/lab5/test_wal.cpp中, 你需要保证你的WAL组件能够通过这些测试, 但这个测试文件编写其实非常粗糙, 因为本节Lab对你的实现方案没有做任何限制, 因此你的实现的元数据也不好测试。因此, 这个测试看看就行, 在你完成下一小节(也是本章最后一个Lab)的逻辑后, 你可以通过test _lsm的LSMTest.Recover判断你的实现是否正确。
Lab 5.5 崩溃恢复
1 崩溃恢复运行机制
当某一时刻存储引擎发送崩溃时, 需要进行崩溃恢复,以恢复数据状态。崩溃恢复的关键是回放日志,以确定已提交的事务,并执行其操作。在这个描述中我们不难得到一个信息, 即成功执行的事务一定要先将操作记录持久化到日志中, 然后再在内存中进行操作, 最后返回成功信息给客户端或者调用者。这也是为什么这个机制称为预写式日志。其崩溃恢复的工作流程包括:
- 日志回放:从最后一个检查点开始扫描日志,按顺序处理所有已提交事务(
COMMIT标记后的操作)。 - Redo阶段:重新执行所有已提交事务的
PUT/REMOVE操作,覆盖当前数据状态。 - Undo阶段(可选):若事务未提交(无
COMMIT标记),则直接丢弃其操作记录。
示例场景
假设事务TX100依次执行PUT key1=value1和REMOVE key2,其日志内容如下:
BEGIN TX100
PUT key1 5 value1
DELETE key2
COMMIT TX100
事务TX100在调用commit函数后, 需要将上述日志刷入wal文件完成预写这一步骤后, 才会返回client事务提交成功。一开始提交的事务,其数据一定是只存在于MemTable中的, 此时如果存储引擎崩溃, 刚刚完成的事务是没法刷入到sst文件的, 但我们重启时可以检查wal文件的内容, 将其与数据库持久化的状态进行比对(持久化的状态包括最大已完成的事务id、最大已经刷盘的事务id, 见上一章的内容),如果其事务id比目前已经持久化到sst的最大事务id大,则说明该事务需要进行重放, 另一方面, 如果事务记录的最后一个条目是Rollback,则说明该事务需要被回滚, 则不需要在崩溃恢复时进行重放.
将上述流程总结如下:
情形1: 正常提交事务、SST刷盘正常
- 事务开始, 写入
BEGIN标记到WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件) - 执行若干
PUT/DELETE操作, 将操作记录写入WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件)- 如果隔离级别是
Read Uncommitted, 可以将PUT/DELETE操作直接应用到数据库 - 其他隔离级别则将
PUT/DELETE操作暂存到事务管理的上下文内存中, 等待事务提交时再应用到数据库
- 如果隔离级别是
- 提交事务:
- 将
COMMIT标记写入WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件) - 将
WAL日志刷入磁盘。(此时WAL日志已经刷入磁盘) - 如果隔离级别不是
Read Uncommitted, 则将暂存的PUT/DELETE操作应用到数据库 - 返回给
client成功或失败
- 将
- 之前事务的
PUT/DELETE操作的变化应用到数据库仍然是位于MemTable中的, 其会稍后输入SST
情形2: 正常提交事务、SST刷盘崩溃
- 事务开始, 写入
BEGIN标记到WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件) - 执行若干
PUT/DELETE操作, 将操作记录写入WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件)- 如果隔离级别是
Read Uncommitted, 可以将PUT/DELETE操作直接应用到数据库 - 其他隔离级别则将
PUT/DELETE操作暂存到事务管理的上下文内存中, 等待事务提交时再应用到数据库
- 如果隔离级别是
- 提交事务:
- 将
COMMIT标记写入WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件) - 将
WAL日志刷入磁盘。(此时WAL日志已经刷入磁盘) - 如果隔离级别不是
Read Uncommitted, 则将暂存的PUT/DELETE操作应用到数据库 - 返回给
client成功或失败
- 将
- 之前事务的
PUT/DELETE操作的变化应用到数据库仍然是位于MemTable中的, 其稍后刷入SST奔溃 - 数据库重启后执行崩溃回复
- 检查
WAL文件的记录 - 整合事务
id每条记录, 忽略以Rollback结尾的事务 - 若事务以
Commit结尾, 则将事务id与已经刷盘的SST中的最大事务id进行比对- 若事务
id大于SST的最大事务id, 执行重放操作 - 若事务
id小于SST的最大事务id, 则忽略该事务, 因为其已经被数据库执行过了
- 若事务
- 检查
情形3: 事务回滚
- 事务开始, 写入
BEGIN标记到WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件) - 执行若干
PUT/DELETE操作, 将操作记录写入WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件)- 如果隔离级别是
Read Uncommitted, 可以将PUT/DELETE操作直接应用到数据库 - 其他隔离级别则将
PUT/DELETE操作暂存到事务管理的上下文内存中, 等待事务提交时再应用到数据库
- 如果隔离级别是
- 回滚事务:
- 将
Rollback标记写入WAL日志中。(此时的WAL日志可能存在于缓冲区, 没有刷入文件) - 将
WAL日志刷入磁盘。(此时WAL日志已经刷入磁盘) - 如果隔离级别不是
Read Uncommitted, 则将暂存的PUT/DELETE操作简单丢弃即可 - 如果隔离级别是
Read Uncommitted, 则将操作前的数据库状态进行还原(作者的设计是利用TranContext中的rollback_map_进行还原, 当然这取决于你之前的Lab实现) - 返回给
client成功或失败
- 将
2 崩溃恢复代码实现
本小节实验, 你需要更改的代码文件包括:
src/lsm/engine.cppinclude/lsm/engine.h(Optional)src/wal/wal.cppinclude/wal/wal.h(Optional)src/lsm/transation.cppinclude/lsm/transation.h(Optional)
2.1 WAL::recover
这里的崩溃恢复需要在引擎启动时进行判断, 因此其与不同组件的构造函数息息相关, 由于这里不同组件的耦合程度较高, 故先统一介绍这流程:
-> LSM::LSM 构造函数启动
-> 调用 LSMEngine 的构造函数
-> 调用 TranManager 的构造函数
-> TranManager 初始化除了 WAL 之外的组件
-> TranManager 从磁盘读取已持久化的事务 id 信息(checkpoint_tranc_id)
-> 调用 TranManager::check_recover 检查是否需要重放WAL日志
-> 将重放的 WAL 日志应用到 LSMEngine
-> 调用 TranManager::init_new_wal 初始化 WAL 组件
-> LSM::LSM 的其他逻辑...
-> LSM::LSM 构造函数结束
std::map<uint64_t, std::vector<Record>>
WAL::recover(const std::string &log_dir, uint64_t checkpoint_tranc_id) {
// TODO: Lab 5.5 检查需要重放的WAL日志
return {};
}
这个函数是一个静态函数,第二个参数 checkpoint_tranc_id 是已经安全持久化到 SST 的最大事务 id(即 TranManager 从磁盘读取的 checkpoint_tranc_id_)。WAL 文件中 tranc_id <= checkpoint_tranc_id 的记录已经刷盘,无需重放;只有 tranc_id > checkpoint_tranc_id 的记录才需要考虑重放。举个例子:
T1 ctx1 running, ctx2 running
T2 ctx1 commit, ctx2 running
T3 crash, both data from in ctx1 and ctx2 are not flushed to sst (in `MemTable`)
T4 recover
在这个例子中, ctx1在崩溃前成功提交但数据没有刷入SST, 存在与内存的MemTable中; ctx2在崩溃时仍未提交, 因此在T4进行崩溃恢复时, 属于ctx1的WAL日志需要进行重放, 而属于ctx2的WAL日志则不需要进行重放(因为其根本没有提交)
WAL::recover函数就是整理需要重放的WAL日志, 返回一个map, 其中key为事务id, value为该事务的所有WAL操作记录
2.2 TranManager::check_recover
std::map<uint64_t, std::vector<Record>> TranManager::check_recover() {
// TODO: Lab 5.5
return {};
}
TranManager::check_recover的目的是调用底层WAL的recover函数, 将其返回的map保存到上层组件中, 由上层组件进行重放。
这里需要注意的是, 之前的WAL::recover函数是静态函数, 其会在WAL的类的实例化之前进行调用, 因此在WAL的实例化过程中, 需要调用WAL::recover函数, 并将返回的map保存到上层组件中使其进行重放, 这里在recover崩溃恢复之后进行WAL的初始化的函数是由TranManager::init_new_wal函数进行的:
2.3 WAL 初始化
在重放完成后,需要重新初始化 WAL,以便后续事务的日志记录:
void TranManager::init_new_wal() {
// TODO: Lab 5.5 初始化 wal
}
这里你也需要回顾一下TranManager的头文件定义:
class TranManager : public std::enable_shared_from_this<TranManager> {
public:
// ...
private:
// ...
std::shared_ptr<WAL> wal;
// ...
};
这里的组件构成是:
TranManager内部管理的WAL这个组件, 他们内部的耦合度还是比较高的, 后续的实验版本也需要进行优化
2.4 LSM 的构造函数
你需要在LSM的构造函数中调用之前实现的WAL重放检查相关的函数, 并将重放的WAL日志应用到LSM中, 在之后你需要重新初始化WAL组件:
LSM::LSM(std::string path)
: engine(std::make_shared<LSMEngine>(path)),
tran_manager_(std::make_shared<TranManager>(path)) {
// TODO: Lab 5.5 控制WAL重放与组件的初始化
}
重放时的关键细节:跳过已刷盘的事务
check_recover() 返回的 map 中可能包含已经刷盘到 SST 的事务(例如 WAL 文件中记录了 TX100,但 TX100 在崩溃前恰好完成了 flush)。在重放时,你需要跳过这些已经持久化的事务:
auto check_recover_res = tran_manager_->check_recover();
for (auto &[tranc_id, records] : check_recover_res) {
// 如果该事务 id 已经在 flushed_tranc_ids 集合中,说明已刷盘,跳过
if (tran_manager_->get_flushed_tranc_ids().count(tranc_id)) {
continue;
}
// 重放该事务的所有操作
for (auto &record : records) {
if (record.getOperationType() == OperationType::OP_PUT) {
engine->put(record.getKey(), record.getValue(), tranc_id);
} else if (record.getOperationType() == OperationType::OP_DELETE) {
engine->remove(record.getKey(), tranc_id);
}
}
}
tran_manager_->init_new_wal();
TranManager::get_flushed_tranc_ids() 返回的是一个 std::set<uint64_t>,记录了所有已经安全刷盘到 SST 的事务 id 集合,这比仅用单个 max_flushed_tranc_id 更精确,避免了“部分刷盘“导致的数据缺失问题。
3 事务id信息的维护
这里补充说明一个非常重要的细节。当前实现中使用 flushed_tranc_ids_(一个 std::set<uint64_t>)替代了单一的 max_flushed_tranc_id_,来跟踪哪些事务已经安全持久化到 SST。
为什么用集合而不是单个最大值?
考虑如下场景:
- 事务 TX100 写入 key1、key2,事务 TX101 写入 key3
- flush 发生时,只有 key1 进入了最终的 SST(例如 TX100 的部分 key 在旧 MemTable 中被 flush 了)
- 若用单一最大值,flush 后
max_flushed_tranc_id = 100,下次恢复时 TX100 被跳过 - 但 key2 可能还在 MemTable 中未刷盘,崩溃后 key2 丢失
flushed_tranc_ids_ 集合的语义是:只有当某个事务的所有操作都已随同一次 flush 完整写入 SST 时,该事务 id 才会被加入集合。具体来说,MemTable::flush_last 在刷盘时会收集 “begin 标记记录”(key="" value="" 的特殊记录)对应的 tranc_id,并通过 LSMEngine::flush 传递给 TranManager::add_flushed_tranc_id。
checkpoint_tranc_id_ 的作用
checkpoint_tranc_id_ 是 WAL 清理的依据,其含义是“已知安全持久化的最大事务 id 的保守估计“,用于 WAL 的 cleanWALFile 函数判断某个历史 WAL 文件是否可以删除。TranManager 在恢复完成后会将其从磁盘读取并传给 WAL 构造函数。
实验不限制你对上述问题的解决方案, 你能通过后续测试即可
4 测试
现在你应该可以通过之前所有的测试了:
✗ xmake
[100%]: build ok, spent 0.773s
✗ xmake run test_lsm
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from LSMTest
[ RUN ] LSMTest.BasicOperations
[ OK ] LSMTest.BasicOperations (1003 ms)
[ RUN ] LSMTest.Persistence
[ OK ] LSMTest.Persistence (2020 ms)
[ RUN ] LSMTest.LargeScaleOperations
[ OK ] LSMTest.LargeScaleOperations (1000 ms)
[ RUN ] LSMTest.IteratorOperations
[ OK ] LSMTest.IteratorOperations (1027 ms)
[ RUN ] LSMTest.MixedOperations
[ OK ] LSMTest.MixedOperations (1001 ms)
[ RUN ] LSMTest.MonotonyPredicate
[ OK ] LSMTest.MonotonyPredicate (1016 ms)
[ RUN ] LSMTest.TrancIdTest
[ OK ] LSMTest.TrancIdTest (18 ms)
[ RUN ] LSMTest.TranContextTest
[ OK ] LSMTest.TranContextTest (0 ms)
[ RUN ] LSMTest.Recover
[ OK ] LSMTest.Recover (1001 ms)
[----------] 9 tests from LSMTest (8091 ms total)
[----------] Global test environment tear-down
[==========] 9 tests from 1 test suite ran. (8091 ms total)
[ PASSED ] 9 tests.
Lab 6 Redis 兼容
之前章节的Lab, 你已经实现了一个功能较为完备的LSM Tree, 这一章我们将目光向上层移动, 来设计一个兼容Redis协议的服务层, 使其能替代redis-server处理redis-cli的请求。
需要注意的是,本章的实验实现了Redis的RESP协议的解析与命令功能的实现, 底层使用的是我们的LSM Tree存储引擎的KV接口。
此外本章不会额外介绍Redis是什么, 你可以参考Redis官网进行简短的学习(只需要了解基础命令的使用即可)。
1 Resp协议简介
这里就不再对Redis本身的基础概念进行介绍了, 毕竟Redis是校招八股必背知识点, 大家想必都非常熟悉了. 但大多数朋友可能对Redis通信的Resp协议完全不熟悉, 这里简单介绍一下Resp协议.
Redis的RESP(REdis Serialization Protocol)是Redis客户端与服务器之间通信的协议, 也就是redis-cli和redis-server之间进行通信的协议,它简单、高效,支持多种数据类型。因此, 其只需要描述Redis中的数据类型和请求类型就可以了。
需要说明的是, Resp协议应该属于TCP这一层的协议, 其没有HTTP等协议的头, 实现时我们也不需要http层的框架
1.1 一个简单的案例
假设你在 redis-cli 中输入了以下命令:
SET k1 v1
redis-cli客户端会将该命令转换为 RESP 协议格式并发送给 Redis 服务器。具体表示如下:
*3
$3
SET
$2
k1
$2
v1
这里其实显式地表达了换行符
\r\n, 真实的内容是:*3\r\n$3\r\nSET\r\n$2\r\nk1\r\n$2\r\nv1\r\n
解释:
*3:表示这是一个包含 3 个元素的数组。$3:表示第一个元素是一个长度为 3 的批量字符串(Bulk String),内容为SET。$2:表示第二个元素是一个长度为 2 的批量字符串,内容为k1。$2:表示第三个元素是一个长度为 2 的批量字符串,内容为v1。
\r\n为不同字段之间的分隔符, 且不计入长度
Redis 服务器接收到上述请求后,执行 SET k1 v1 操作,并返回响应。例如:
+OK
解释:
+OK:表示这是一个简单字符串(Simple String),值为OK,表示操作成功。
如果客户端发送的命令或参数有误,Redis 服务器可能会返回错误信息。例如:
-ERR syntax error
解释:
-ERR:表示这是一个错误消息(Error),内容为syntax error。
1.2 数据类型语法
通过之前的案例我们可以看到, RESP使用一些符号来对数据类型进行标记, 这里简单总结如下:
- 简单字符串(Simple Strings):以“+“开头,如
+OK\r\n。 - 错误(Errors):以“-“开头,如
-ERR unknown command\r\n。 - 整数(Integers):以“:“开头,如
:1000\r\n。 - 批量字符串(Bulk Strings):以“$“开头,如
$6\r\nfoobar\r\n。 - 数组(Arrays):以“*“开头,如
*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n。
2 Redis实现思路
这里我们将利用自身的LSM Tree接口来设计一个兼容Redis协议的服务层, 使其能替代redis-server处理redis-cli的请求.
首先我们回顾一下我们的LSM Tree接口支持什么api:
Put(key, value): 将键值对插入到数据库中。Get(key): 根据键获取对应的值。Delete(key): 根据键删除对应的值。Scan(start_key, end_key): 根据起始键和结束键范围获取键值对。(就是上一章实现的谓词查询, 这里的Scan是一个虚拟的接口)
然后我们想一下Redsis的不同数据结构的接口
- 字符串(String):和
LSM Tree一样, 我们也只需要实现Put(key, value)和Get(key)即可 - 列表(List):相当于不同字符串之间有连接
- 哈希(Hash):一个哈希的
key由很多个filed即value组成 - 集合(Set): 一个集合的
key由很多个member, 但不需要排序 - 有序集合(Sorted Set): 集合的
key由很多个member和score组成, 并且需要按照score排序
同时很多key还有一些基础属性, 最常用的就是TTL(过期时间), 当TTL过期时, 该key将不再存在, 我们也可以通过TTL来判断一个key是否过期, 也可以使用EXPIRE来设置一个key的过期时间
其实本质上, 由于我们的存储引擎是KV存储, 我们的哈希的所有数据都将作为基础的key和value进行存储, 这与Redis中的字符串是一致的。而List, Set, Sorted Set等数据结构就需要将多对key进行组合, 并且需要根据一定的规则进行排序, 而且回想我的LSM Tree接口支持的api, 核心思路就只有2类:
List,Set,Sorted Set等数据结构的key的value中要记录所管理成员的元信息- 归属于某个大数据结构(
List,Set,Sorted Set等)的成员的key需要包含统一的前缀, 这样才能通过我的的存储引擎进行前缀查询
现在你已经对RESP和Redis的兼容层的设计思想有一个大致的认知, 接下来我们就可以开始实现我们的兼容层了: Lab 6.1 简单字符串
!!! 你做
Lab时如果对RESP协议的格式不熟悉, 可以参考附录中的RESP 常见格式进行学习
Lab 6.1 简单字符串
1 简单字符串的设计
你也许会认为, 简单字符串不就是调用我们LSM Tree的get和put方法吗? 其实不然, 你是否忘记了我们的Redis是支持对键值对进行过期时间设置的?
那么, 由于过期时间的存在, 你的代码实现需要解决以下几个难点:
1 如何实现过期时间?
你也许会认为, 我们只需要在value或者key中拼接一个字段来表示过期时间即可, 但虽然是一个可行的方案, 但因为我们过期时间是支持重新设置的, 这样以来你在查询数据后需要进行一定的字符串处理流程。
另一种方案,是每个实际的键值对绑定一个表示其生命周期的额外键值对,比如你插入的键值对是 (a, b), 那你可以同时插入一个键值对 (expire_a, expire_time), 其中expire_time表示与键a的绑定的表示过期时间的key。这样,当你查询a时,只需要查询expire_a的表示过期时间的expire_time即可,如果过期时间小于当前时间,则删除a和expire_a,并返回nil。
上面两种方案是最简单且容易想到的方案, 当然你也不一定局限于作者推荐的实现方案, 可以有自己的设计
2 采取何种过期清理策略?
那么key只要存在过期时间, 你的实现策略有以下3种:
- 惰性检查: 相同的
key在下一次被查询时, 检查是否过期, 如果过期则删除, 返回nil- 优点: 实现简单
- 缺点: 如果这个
key是个冷key(即访问频率低), 那么即时其过期很久之后, 仍然占据了内存(虽然我们的LSM Tree是追加写入的, 但在Compact时, 我们是需要移除已经完成的事务且被覆写的键值对的)
- 后台线程检查: 在后台开启一个线程, 每隔一段时间检查所有键值对, 如果过期则删除
- 优点: 过期的
key能较为及时地被删除 - 缺点: 需要额外的线程, 代码组织和并发控制复杂
- 优点: 过期的
- 前两种结合: 惰性检查+后台线程检查
3 代码组织简介
这一小节我们首先对Redis的兼容层代码进行简要介绍, 我们的代码组织为:
├── config.toml # 配置文件的常量 (你需要复制到单元测试编译的目录下才能生效)
├── include
│ ├── redis_wrapper # Redis 兼容层的头文件定义
│ │ └── redis_wrapper.h
├── server # 调用 Redis 兼容层的 Webserver
│ ├── include
│ │ └── handler.h # Redis 命令处理函数的声明
│ └── src
│ ├── handler.cpp # Redis 命令处理函数的实现, 就是对 redis_wrapper 的转发
│ └── server.cpp # Webserver 的实现
├── src
│ ├── redis_wrapper
│ │ └── redis_wrapper.cpp # Redis 兼容层的实现
├── test
│ ├── test_redis.cpp # Redis 兼容层的单元测试
└── xmake.lua
各个代码文件的作用如上所示, 这里我们主要介绍今天要修改的redis_wrapper.cpp和redis_wrapper.h文件。
首先看redis_wrapper.h文件:
class RedisWrapper {
private:
std::unique_ptr<LSM> lsm;
std::shared_mutex redis_mtx;
public:
RedisWrapper(const std::string &db_path);
void clear();
void flushall();
// ************************* Redis Command Parser *************************
// ...
private:
// ************************* Redis Command Handler *************************
// 基础操作
std::string redis_incr(const std::string &key);
std::string redis_decr(const std::string &key);
std::string redis_expire(const std::string &key, std::string seconds_count);
std::string redis_set(std::string &key, std::string &value);
std::string redis_get(std::string &key);
std::string redis_del(std::vector<std::string> &args);
std::string redis_ttl(std::string &key);
// 哈希操作
std::string redis_hset(const std::string &key, const std::string &field,
const std::string &value);
std::string redis_hset_batch(
const std::string &key,
std::vector<std::pair<std::string, std::string>> &field_value_pairs);
std::string redis_hget(const std::string &key, const std::string &field);
std::string redis_hdel(const std::string &key, const std::string &field);
std::string redis_hkeys(const std::string &key);
// 链表操作
std::string redis_lpush(const std::string &key, const std::string &value);
std::string redis_rpush(const std::string &key, const std::string &value);
std::string redis_lpop(const std::string &key);
std::string redis_rpop(const std::string &key);
std::string redis_llen(const std::string &key);
std::string redis_lrange(const std::string &key, int start, int stop);
// 有序集合操作
std::string redis_zadd(std::vector<std::string> &args);
std::string redis_zrem(std::vector<std::string> &args);
std::string redis_zrange(std::vector<std::string> &args);
std::string redis_zcard(const std::string &key);
std::string redis_zscore(const std::string &key, const std::string &elem);
std::string redis_zincrby(const std::string &key,
const std::string &increment,
const std::string &elem);
std::string redis_zrank(const std::string &key, const std::string &elem);
// 无序集合操作
std::string redis_sadd(std::vector<std::string> &args);
std::string redis_srem(std::vector<std::string> &args);
std::string redis_sismember(const std::string &key,
const std::string &member);
std::string redis_scard(const std::string &key);
std::string redis_smembers(const std::string &key);
};
这里的成员变量只有一把锁和一个LSM对象, 锁用于保护LSM对象, 防止并发访问。不过这个锁的只是一个可选的使用项, 如果你之前的LSMEngine的接口实现了对某些批量化操作的并发控制, 那么你可以直接使用LSMEngine的接口, 而不需要使用RedisWrapper的锁。
其余部分的redis_xxx函数都是你需要在本大章节的Lab中需要实现的, 其对应于具体的Redis命令
4 代码实现
本小节我们实现字符串处理相关命令函数, 你需要修改的代码文件包括:
src/redis_wrapper/redis_wrapper.cppinclude/redis_wrapper/redis_wrapper.h(Optional)
4.1 set
std::string RedisWrapper::redis_set(std::string &key, std::string &value) {
// TODO: Lab 6.1 新建(或更改)一个`key`的值
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "+OK\r\n";
}
这里我们不需要你支持在set一个key时就指定其过期时间, 我们的单元测试只会在expire中手动设置过期时间。
4.2 expire
std::string RedisWrapper::redis_expire(const std::string &key,
std::string seconds_count) {
// TODO: Lab 6.1 设置一个`key`的过期时间
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":1\r\n";
}
该命令用于设置一个key的过期时间, 单位为秒。
如同之前理论部分的介绍, 你既可以选择为其额外设置一个表示过期时间的键值对, 也可以在键值对的字符串中拼接表示过期时间的部分, 亦或是其他方案。
4.3 ttl
std::string RedisWrapper::redis_ttl(std::string &key) {
// TODO: Lab 6.1 获取一个`key`的剩余过期时间
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":1\r\n"; // 表示键不存在
}
该命令是与expire成对的, 你在expire中如何设置过期时间, 就需要在ttl中如何获取剩余过期时间。
4.4 get
std::string RedisWrapper::redis_get(std::string &key) {
// TODO: Lab 6.1 获取一个`key`的值
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "$-1\r\n"; // 表示键不存在
}
查询一个key的值, 如果不存在则返回nil。
你可能需要再此时判断一下key是否已经过期, 如果已经过期则删除该key。
4.5 incr && decr
std::string RedisWrapper::redis_incr(const std::string &key) {
// TODO: Lab 6.1 自增一个值类型的key
// ? 不存在则新建一个值为1的key
return "1";
}
std::string RedisWrapper::redis_decr(const std::string &key) {
// TODO: Lab 6.1 自增一个值类型的key
// ? 不存在则新建一个值为-1的key
return "-1";
}
对一个值类型的key进行自增或自减操作, 如果不存在则新建一个值为1或-1的key。
如果该键值对的值不是数值类型, 则返回error。在RESP中如何表示error你需要自行回顾Lab 6 Redis 兼容中的简单介绍, 或者看官方文档(甚至是问LLM)。
4.6 del
std::string RedisWrapper::redis_del(std::vector<std::string> &args) {
// TODO: Lab 6.1 删除一个key
int del_count = 0;
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":" + std::to_string(del_count) + "\r\n";
}
删除一个key。
5 测试
完成上面的代码后, 你可以运行以下命令并通过对应的测试:
✗ xmake
[100%]: build ok, spent 2.013s
✗ xmake run test_redis
[==========] Running 11 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 11 tests from RedisCommandsTest
[ RUN ] RedisCommandsTest.SetAndGet
[ OK ] RedisCommandsTest.SetAndGet (12 ms)
[ RUN ] RedisCommandsTest.IncrAndDecr
[ OK ] RedisCommandsTest.IncrAndDecr (9 ms)
[ RUN ] RedisCommandsTest.Expire
[ OK ] RedisCommandsTest.Expire (2014 ms)
[ RUN ] RedisCommandsTest.HSetAndHGet # Failed
Lab 6.2 哈希表
1 Redis 实现思路
Redis的哈希结构就是一个key中管理了一个哈希表, 这里的实现有以下方案
方案1-序列化整个哈希数据结构到value
你可以采用自己编码或者引入第三方库的形式, 将整个哈希数据结构序列化成字符串, 然后存储到value中, 这样查询的时候直接反序列化即可。
- 优点: 查询方便, 不需要关心序列化功能的具体实现
- 缺点: 序列化/反序列化耗时, 占用内存, 不利于扩展。比如,你对哈希结构中的一个
field进行修改, 需要重新序列化整个哈希数据结构
方案2-field分离存储
这里的方案类似我们之前设置超时时间的一种解决方案, 你可以将每个field作为额外的键值对进行存储, 然后代表整个哈希结构的key的value中可以存储这些field的元信息, 下面给出一种具体的实现思路供你参考:
- 整个
hash数据结构的key存储的value是其所有field的集合拼接的字符串 - 每个
field的value单独用另一个键值对存储, 但field不能直接作为一个key, 而是需要加上指定的前缀以标识这是一个哈希结构的field
那么查询的逻辑就是, 将key和field拼接起来形成实际存储的key, 然后查询对应的value即可
2 TTL 设计
同样, 你的哈希结构也需要支持TTL和Expire命令, 不过这2个命令针对的对象是整个哈希结构, 你不需要考虑对哈希中的一个field设计超时时间。
需要注意的是,你的实现方案同样需要考虑到旧数据的清理流程。
最后, 如果你的哈希结构采用的是分离存储field的方式(这个方式其实更推荐),你需要对内部函数的并发控制进行处理,因为这里你操作的对象可能涉及底层LSM Tree中的多个Key, 因此你需要灵活地利用批量化的操作接口, 以及自身组件的上锁与解锁逻辑控制。
你在不同操作时, 建议利用好读写锁相比独占锁的优势, 以及在必要时进行锁升级
3 代码实现
你需要修改的代码文件包括:
src/redis_wrapper/redis_wrapper.cppinclude/redis_wrapper/redis_wrapper.h(Optional)
下面的接口中, 你仍然需要进行
TTL超时时间的判断, 同时你可能需要更新之前的redis_ttl和redis_expire以兼容Hash的TTL机制。
3.1 hset
std::string RedisWrapper::redis_hset_batch(
const std::string &key,
std::vector<std::pair<std::string, std::string>> &field_value_pairs) {
std::shared_lock<std::shared_mutex> rlock(redis_mtx);
// TODO: Lab 6.2 批量设置一个哈希类型的`key`的多个字段值
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
int added_count = 0;
return ":" + std::to_string(added_count) + "\r\n";
}
std::string RedisWrapper::redis_hset(const std::string &key,
const std::string &field,
const std::string &value) {
std::shared_lock<std::shared_mutex> rlock(redis_mtx); // 读锁线判断是否过期
// TODO: Lab 6.2 设置一个哈希类型的`key`的某个字段值
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "+OK\r\n";
}
hset允许单次的field设置, 也可以批量设置多个field。
3.2 hget
std::string RedisWrapper::redis_hget(const std::string &key,
const std::string &field) {
// TODO: Lab 6.2 获取一个哈希类型的`key`的某个字段值
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "$-1\r\n"; // 表示键不存在
}
类似之前的简单字符串的get操作, 你可能需要再此时判断一下key是否已经过期, 如果已经过期则删除该key及其field(如果是分离存储的实现方案)。
3.3 hdel
std::string RedisWrapper::redis_hdel(const std::string &key,
const std::string &field) {
// TODO: Lab 6.2 删除一个哈希类型的`key`的某个字段
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":1\r\n";
}
你需要删除单个哈希结构的field。
3.4 hkeys
std::string RedisWrapper::redis_hkeys(const std::string &key) {
// TODO: Lab 6.2 获取一个哈希类型的`key`的所有字段
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "*0\r\n";
}
_hkeys就是返回哈希结构中所有的field。
同时,这也是为什么在之前的理论介绍中 (在分离存储field的实现方案中), 为什么建议你在代表整个哈希结构的大key的value中存储所有field的元信息。长这样你在实现 hkeys的时候就会方便很多, 只需要查询单个key就可以了。否则你需要调用前缀查询来获取所有的field的键值对。
Redis中涉及哈希的命令还有很多, 这里并没有完全实现, 毕竟本Lab的主题是介绍实现Redis命令的设计方法, 有了上述基础命令, 其他的命令实现应该非常简单了, 都是简单重复的操作了, 有兴趣你可以自己补充其余命令
4 测试
在完成上面的功能后, 你应该能通过下面的测试:
✗ xmake
✗ xmake run test_redis
[==========] Running 11 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 11 tests from RedisCommandsTest
[ RUN ] RedisCommandsTest.SetAndGet
[ OK ] RedisCommandsTest.SetAndGet (14 ms)
[ RUN ] RedisCommandsTest.IncrAndDecr
[ OK ] RedisCommandsTest.IncrAndDecr (9 ms)
[ RUN ] RedisCommandsTest.Expire
[ OK ] RedisCommandsTest.Expire (2009 ms)
[ RUN ] RedisCommandsTest.HSetAndHGet
[ OK ] RedisCommandsTest.HSetAndHGet (17 ms)
[ RUN ] RedisCommandsTest.HDel
[ OK ] RedisCommandsTest.HDel (9 ms)
[ RUN ] RedisCommandsTest.HKeys
[ OK ] RedisCommandsTest.HKeys (9 ms)
[ RUN ] RedisCommandsTest.HGetWithTTL
[ OK ] RedisCommandsTest.HGetWithTTL (2113 ms)
[ RUN ] RedisCommandsTest.HExpire
[ OK ] RedisCommandsTest.HExpire (1111 ms)
[ RUN ] RedisCommandsTest.ListOperations
Lab 6.3 无序集合
1 实现原理
相比之前实现的哈希, Redis的无序数据结构功能简单不少, 其只需要将字符串存储在这个Set中即可, 也不要求数据的有序性, 其行为类似C++中的std::unordered_set。
因此, 这里你需要面对的问题就是, 如何组织这么多个字符串, 并且保证其唯一性?
在这里就不建议将Set中所有的字符串都编码或者拼接后存储在单个键值对的value中, 因为通常的业务中, 一个Set中的字符串数量是远大于哈希结构的filed的, 这里若还采用整体编码存储在单个键值对中, 在CRUD的过程中, 编解码会消耗大量的时间。
我们最后会兼容
Redis的官方压测工具redis-benchmark, 你可以用这个测试工具比较不同实现方案的性能差距
这里唯一推荐的方式就是利用我们的LSM Tree中实现的谓词查询接口(这里的谓词就是判断前缀是否匹配), 为同一Set的所有字符串添加相同的前缀后进行分离的键值对存储, 然后通过这个前缀进行范围查询, 这样就可以保证查询的效率, 并且保证唯一性。
2 代码实现
你需要修改的代码文件包括:
src/redis_wrapper/redis_wrapper.cppinclude/redis_wrapper/redis_wrapper.h(Optional)
下面的接口中, 你仍然需要进行
TTL超时时间的判断, 同时你可能需要更新之前的redis_ttl和redis_expire以兼容Set的TTL机制。
2.1 sadd
std::string RedisWrapper::redis_sadd(std::vector<std::string> &args) {
// TODO: Lab 6.3 如果集合不存在则新建,添加一个元素到集合中
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":1\r\n";
}
需要注意的是, sadd是支持一次性在集合中新增多个元素的, 这里你可能需要调用批量化操作的接口提高以性能。
2.2 srem
std::string RedisWrapper::redis_srem(std::vector<std::string> &args) {
// TODO: Lab 6.3 删除集合中的元素
int removed_count = 0;
return ":" + std::to_string(removed_count) + "\r\n";
}
需要注意的是, srem是支持一次性从集合中删除多个元素的, 这里你可能需要调用批量化操作的接口提高以性能。
2.3 sismember
std::string RedisWrapper::redis_sismember(const std::string &key,
const std::string &member) {
// TODO: Lab 6.3 判断集合中是否存在某个元素
return ":1\r\n";
}
对于查询单个字符串是否在集合中, 你只需要按照规则拼接这个分离存储的key, 再从Lsm Tree中查询即可。
2.4 scard
std::string RedisWrapper::redis_scard(const std::string &key) {
// TODO: Lab 6.3 获取集合的元素个数
return ":1\r\n";
}
这里同样, 你可以直接在代表整个集合的大key中, 通过value中的元信息直接获取到集合的元素个数。如果你没有在大key中存储元信息, 调用谓词查询接口也可以获取到所有元素, 然后返回元素个数即可。
2.5 smembers
std::string RedisWrapper::redis_smembers(const std::string &key) {
// TODO: Lab 6.3 获取集合的所有元素
return "*0\r\n";
}
smembers用于获取所有的元素, 这里你可以直接调用LSM Tree的谓词查询接口, 查询所有前缀匹配的键值对, 然后从这些键值对的value构造RESP协议的数组返回即可。
3 测试
在完成上面的功能后, 你应该能通过下面的测试:
✗ xmake
✗ xmake run test_redis
[==========] Running 11 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 11 tests from RedisCommandsTest
[ RUN ] RedisCommandsTest.SetAndGet
[ OK ] RedisCommandsTest.SetAndGet (14 ms)
[ RUN ] RedisCommandsTest.IncrAndDecr
[ OK ] RedisCommandsTest.IncrAndDecr (9 ms)
[ RUN ] RedisCommandsTest.Expire
[ OK ] RedisCommandsTest.Expire (2009 ms)
[ RUN ] RedisCommandsTest.HSetAndHGet
[ OK ] RedisCommandsTest.HSetAndHGet (17 ms)
[ RUN ] RedisCommandsTest.HDel
[ OK ] RedisCommandsTest.HDel (9 ms)
[ RUN ] RedisCommandsTest.HKeys
[ OK ] RedisCommandsTest.HKeys (9 ms)
[ RUN ] RedisCommandsTest.HGetWithTTL
[ OK ] RedisCommandsTest.HGetWithTTL (2113 ms)
[ RUN ] RedisCommandsTest.HExpire
[ OK ] RedisCommandsTest.HExpire (1111 ms)
[ RUN ] RedisCommandsTest.ListOperations
Lab 6.4 有序集合
1 Redis ZSet 实现思路
1.1 实现思路
这里也不介绍Redis zset的语法了, 既然看这篇文章, 相比大家对Redis非常熟悉了, 这里本实验选择实现如下常见的api:
zaddzremzrangezcardzscorezincrbyzrank
相较于之前实现的set, zset额外加入了了score字段, 并且需要支持按照score排序的查询, 因此这里的实现又类似于hash的实现, 因为存储的filed(就是集合中的数据成员)和score正好可以构成分离存储的一对键值对。
在分离存储键值对的方案下, zset最大的难点就是需要双向的查询索引: 既要能够通过zscore查询指定成员的分数, 也要能够通过zrank、zrange按照分数排序。对于按照分数排序查询, 由于我们的LSM Tree本来就是按照key排序的, 所以我们只需要将所有的成员按照他们的分数构建一个符合顺序的key就可以了; 对于按照成员查询分数, 我们只能再额外存储一个key.
因此我们使用如下的方案:
- 整个
zset控制结构的键值对只标记其存在, 不在value中存储有效信息(但不能为空, 因为value为空表示被删除) - 需要存储
(score, elem)键值对,score为固定的前缀+key+真正的score拼接而成 - 需要存储
(elem, score)键值对,elem为固定的前缀+key+真正的elem拼接而成
需要注意的是
score为固定的前缀+key+真正的score拼接而成, 为保证这个key在我们的LSM Rree中排序符合score的顺序, 这个score我们限制器为整型数, 且其长度对其到32位, 否则如果支持小数的话, 排序和解析就会复杂很多
1.2 TTL
类似上一章的TTL设计, 我们需要为这个zset也实现TTL机制. 首先需要明白, Redis 的 TTL 只能对整个键(key)设置过期时间,而不能针对列表(list)、集合(set)、哈希(hash)等数据结构中的单个成员单独设置过期时间。
类似上一章节的lsit和hash的工作流程, 我们每次读写zset时, 都需要检查TTL是否过期, 如果过期, 则删除zset
2 一个存储案例
这里zset应该是最复杂的数据结构, 因此这里用一个demo详细说明下作者推荐的实现方案是如何工作的:
ZADD student 100 tom # 添加一个学生及其成绩
# 主key: (student, 1) 1 表示成员的数量
# -> 分离存储的key1: (student_score_000100, tom) # 支持从分数查找 student, 这里填充为六位数`000100`, 保证字符串排序
# -> 分离存储的key2: (student_tom, 100) # 支持从 tom 分数查找分数
ZADD student 90 jerry # 添加一个学生及其成绩
# 主key: (student, 2) 2 表示成员的数量
# -> 分离存储的key1: (student_score_000100, tom)
# -> 分离存储的key2: (student_filed_tom, 100)
# -> 分离存储的key1: (student_score_000090, jerry)
# -> 分离存储的key2: (student_filed_jerry, 90)
ZSCORE student tom # 查询 tom 的成绩
# 直接调用kv引擎的 get接口, 查询 (student_tom, 100) 即可
ZCARD student # 查询学生数量
# 直接调用kv引擎的 get接口, 查询 (student, 2) 返回2
ZINCRBY student 10 tom # tom 成绩加10分
# 1. 先查询 tom 的成绩
# 2. 将 tom 的成绩加10分
# 3. 更新 (student_filed_tom, 110)
# 4. 插入 (student_score_000110, tom) , 删除 (student_score_000100, tom)
# PS: 如果 tom 不存在则直接新建
ZRANGE student 0 1 # 查询前两名学生
# 使用谓词查询, 谓词为查询所有前缀为 student_score_ 的key, 并按照key排序, 返回前两个key中的value即可
3 代码实现
通过上面的理论讲解和案例说明, 你应该对此非常熟悉了…
你需要修改的代码文件包括:
src/redis_wrapper/redis_wrapper.cppinclude/redis_wrapper/redis_wrapper.h(Optional)
下面的接口中, 你仍然需要进行
TTL超时时间的判断, 同时你可能需要更新之前的redis_ttl和redis_expire以兼容ZSet的TTL机制。
3.1 zadd
std::string RedisWrapper::redis_zadd(std::vector<std::string> &args) {
// TODO: Lab 6.4 如果有序集合不存在则新建,添加一个元素到有序集合中
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":1\r\n";
}
注意, 这里支持一次性添加多个filed, 返回值表示多少个filed添加成功
3.2 zrem
std::string RedisWrapper::redis_zrem(std::vector<std::string> &args) {
// TODO: Lab 6.4 删除有序集合中的元素
int removed_count = 0;
return ":" + std::to_string(removed_count) + "\r\n";
}
注意, 这里支持一次性删除多个filed, 返回值表示多少个filed删除成功
3.3 zrange
std::string RedisWrapper::redis_zrange(std::vector<std::string> &args) {
// TODO: Lab 6.4 获取有序集合中指定范围内的元素
return "*0\r\n";
}
查询指定范围的元素, 返回值表示查询到的元素的数组(RESP格式), 你需要使用LSM的谓词查询接口
3.4 zcard
std::string RedisWrapper::redis_zcard(const std::string &key) {
// TODO: Lab 6.4 获取有序集合的元素个数
return ":1\r\n";
}
查询有序集合的元素个数
3.5 zscore
std::string RedisWrapper::redis_zscore(const std::string &key,
const std::string &elem) {
// TODO: Lab 6.4 获取有序集合中元素的分数
return "$-1\r\n";
}
查询有序集合中指定filed的分数, 你只需要按照指定格式拼接key进行查询即可
3.6 zincrby
std::string RedisWrapper::redis_zincrby(const std::string &key,
const std::string &increment,
const std::string &elem) {
// TODO: Lab 6.4 对有序集合中元素的分数进行增加
return "$-1\r\n";
}
对有序集合中指定元素的分数进行增加, 返回值表示增加后的分数
3.7 zrank
std::string RedisWrapper::redis_zrank(const std::string &key,
const std::string &elem) {
// TODO: Lab 6.4 获取有序集合中元素的排名
return "$-1\r\n";
}
获取有序集合中指定元素的排名, 返回值表示排名
4 测试
在完成上面的功能后, 你应该能通过下面的测试:
✗ xmake
✗ xmake run test_redis
✗ xmake run test_redis
[==========] Running 11 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 11 tests from RedisCommandsTest
[ RUN ] RedisCommandsTest.SetAndGet
[ OK ] RedisCommandsTest.SetAndGet (13 ms)
[ RUN ] RedisCommandsTest.IncrAndDecr
[ OK ] RedisCommandsTest.IncrAndDecr (9 ms)
[ RUN ] RedisCommandsTest.Expire
[ OK ] RedisCommandsTest.Expire (2011 ms)
[ RUN ] RedisCommandsTest.HSetAndHGet
[ OK ] RedisCommandsTest.HSetAndHGet (17 ms)
[ RUN ] RedisCommandsTest.HDel
[ OK ] RedisCommandsTest.HDel (9 ms)
[ RUN ] RedisCommandsTest.HKeys
[ OK ] RedisCommandsTest.HKeys (9 ms)
[ RUN ] RedisCommandsTest.HGetWithTTL
[ OK ] RedisCommandsTest.HGetWithTTL (2111 ms)
[ RUN ] RedisCommandsTest.HExpire
[ OK ] RedisCommandsTest.HExpire (1109 ms)
[ RUN ] RedisCommandsTest.SetOperations
[ OK ] RedisCommandsTest.SetOperations (8 ms)
[ RUN ] RedisCommandsTest.ZSetOperations
[ OK ] RedisCommandsTest.ZSetOperations (8 ms)
[ RUN ] RedisCommandsTest.ListOperations # failed
Lab 6.5 链表
最后我们来实现Redis中的链表。之前的Lab中, 作者对设计方案都进行了详细的介绍, 也许你觉得这限制了你自己的设计, 因此这一小节作者打算不给你任何提示, 你需要自己设计并实现一个链表, 并通过对应的单元测试。
1 代码实现
你需要修改的代码文件包括:
src/redis_wrapper/redis_wrapper.cppinclude/redis_wrapper/redis_wrapper.h(Optional)
下面的接口中, 你仍然需要进行
TTL超时时间的判断, 同时你可能需要更新之前的redis_ttl和redis_expire以兼容List的TTL机制。
// 链表操作
std::string RedisWrapper::redis_lpush(const std::string &key,
const std::string &value) {
// TODO: Lab 6.5 新建一个链表类型的`key`,并添加一个元素到链表头部
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":" + std::to_string(1) + "\r\n";
}
std::string RedisWrapper::redis_rpush(const std::string &key,
const std::string &value) {
// TODO: Lab 6.5 新建一个链表类型的`key`,并添加一个元素到链表尾部
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":" + std::to_string(1) + "\r\n";
}
std::string RedisWrapper::redis_lpop(const std::string &key) {
// TODO: Lab 6.5 获取一个链表类型的`key`的头部元素
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "$-1\r\n"; // 表示链表不存在
}
std::string RedisWrapper::redis_rpop(const std::string &key) {
// TODO: Lab 6.5 获取一个链表类型的`key`的尾部元素
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "$-1\r\n"; // 表示链表不存在
}
std::string RedisWrapper::redis_llen(const std::string &key) {
// TODO: Lab 6.5 获取一个链表类型的`key`的长度
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return ":1\r\n"; // 表示链表不存在
}
std::string RedisWrapper::redis_lrange(const std::string &key, int start,
int stop) {
// TODO: Lab 6.5 获取一个链表类型的`key`的指定范围内的元素
// ? 返回值的格式, 你需要查询 RESP 官方文档或者问 LLM
return "*0\r\n"; // 表示链表不存在或者范围无效
}
2 测试
现在你应该可以通过所有的单元测试:
✗ xmake
[100%]: build ok, spent 0.607s
✗ xmake run test_redis
[==========] Running 11 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 11 tests from RedisCommandsTest
[ RUN ] RedisCommandsTest.SetAndGet
[ OK ] RedisCommandsTest.SetAndGet (10 ms)
[ RUN ] RedisCommandsTest.IncrAndDecr
[ OK ] RedisCommandsTest.IncrAndDecr (8 ms)
[ RUN ] RedisCommandsTest.Expire
[ OK ] RedisCommandsTest.Expire (2011 ms)
[ RUN ] RedisCommandsTest.HSetAndHGet
[ OK ] RedisCommandsTest.HSetAndHGet (8 ms)
[ RUN ] RedisCommandsTest.HDel
[ OK ] RedisCommandsTest.HDel (8 ms)
[ RUN ] RedisCommandsTest.HKeys
[ OK ] RedisCommandsTest.HKeys (8 ms)
[ RUN ] RedisCommandsTest.HGetWithTTL
[ OK ] RedisCommandsTest.HGetWithTTL (2108 ms)
[ RUN ] RedisCommandsTest.HExpire
[ OK ] RedisCommandsTest.HExpire (1121 ms)
[ RUN ] RedisCommandsTest.SetOperations
[ OK ] RedisCommandsTest.SetOperations (8 ms)
[ RUN ] RedisCommandsTest.ZSetOperations
[ OK ] RedisCommandsTest.ZSetOperations (9 ms)
[ RUN ] RedisCommandsTest.ListOperations
[ OK ] RedisCommandsTest.ListOperations (8 ms)
[----------] 11 tests from RedisCommandsTest (5314 ms total)
[----------] Global test environment tear-down
[==========] 11 tests from 1 test suite ran. (5314 ms total)
[ PASSED ] 11 tests
此外, 不出意外, 整个Lab的所有单元测试你应该都能正常通过:
✗ xmake run test_redis
# ...
Lab 6.6 redis-server实现
1 概述
之前我们完成了利用KV接口实现常见Redis命令的常见命令, 我们的Lab即将迎来最后一个部分, 即实现Redis服务器的部分。
这一部分内容其实也很简单,网络框架作者已经为你搭建好了,你只需要实现Resp请求的解析, 利用解析出的参数调用我们之前实现的各个命令的接口即可。
在初版的
Lab中, 我们使用了muduo作为网络框架, 但由于muduo仅支持Linux, 因此在后续版本中我们将其替换为asio, 这是一个跨平台的网络库, 支持Windows,MacOS和Linux。使用asio后,本实验可以在所有主流操作系统上运行:Linux+MacOS+Windows(Wsl)
2 代码实现
这节课你可以修改server文件夹下的任何文件
├── server # 调用 Redis 兼容层的 Webserver
│ ├── include
│ │ └── handler.h # Redis 命令处理函数的声明
│ └── src
│ ├── handler.cpp # Redis 命令处理函数的实现, 就是对 redis_wrapper 的转发
│ └── server.cpp # Webserver 的实现
你需要实现的接口为:
std::string handleRequest(const std::string &request) {
// TODO: Lab 6.6 处理网络传输的RESP字节流
// TODO: Lab 6.6 形成参数并调用 redis_wrapper 的api
// TODO: Lab 6.6 返回结果
return "";
}
handleRequest前后的网络包收发逻辑已经为你写好, 你只需要在这个函数中解析RESP协议, 调用redis_wrapper的接口即可。当然, 你也可以直接新增各种辅助函数。
除了我们之前实现的各种命令外, 你还需要实现
PING命令, 这个命令不需要任何参数, 只需要返回"+PONG\r\n"即可。其内在含义表示服务器正在运行。
3 测试
你可以安装并使用redis-cli来测试你的Redis服务器, 过程为
cd tiny-lsm
xmake
xmake run server
上述操作将启动你实现的Redis服务器
然后在另一个终端中运行:
redis-cli
此时你就可以在redis-cli中输入我们之前Lab实现的命令和server进行交互了
预期的结果应该如下所示:
4 redis-benchmark 压测
由于我们已经实现了支持Resp的服务器, 其提供类似官方的redis-server的服务。同时, redis官方提供了压测工具redis-benchmark, 我们可以利用其进行压测。
4.1 redis-benchmark 安装
redis-benchmark是一个官方的压测工具,无论你是从apt/yum等源安装的redis,还是从源码编译的,其默认安装选项中都提供了redis-benchmark。
4.2 redis-benchmark 使用
redis-benchmark的使用非常简单,只需要指定-h参数,指定redis服务器的ip地址,然后就可以进行压测了。
redis-benchmark 是 Redis 官方自带的性能测试工具,用于模拟多个客户端同时向 Redis 服务器发送命令,并评估其性能表现。它可以帮助你了解 Redis 在不同负载下的吞吐量和延迟情况。
基本的命令格式如下:
redis-benchmark [选项] [测试]
如果不带任何选项,redis-benchmark 会使用默认设置连接到本地 (127.0.0.1) 的 6379 端口,并执行一组预定义的测试。
常用选项
以下是一些常用的 redis-benchmark 选项:
-
主机和端口:
-h <hostname>: 指定要连接的 Redis 服务器的主机名或 IP 地址 (默认为127.0.0.1)。-p <port>: 指定 Redis 服务器的端口号 (默认为6379)。-a <password>: 如果 Redis 服务器设置了密码,使用此选项进行身份验证。--tls: 如果 Redis 服务器启用了 TLS/SSL 加密,使用此选项。
-
并发和请求数:
-c <clients>: 指定并发客户端的数量 (默认为50)。这模拟了同时有多少个连接在向 Redis 发送请求。-n <requests>: 指定总的请求数量 (默认为100000)。
-
数据大小:
-d <size>: 指定 SET/GET 命令操作的数据大小,单位是字节 (默认为3)。
-
测试命令:
-t <tests>: 指定要执行的测试命令列表,用逗号分隔。例如-t SET,GET,LPUSH。如果不指定,则执行默认的测试集 (PING_INLINE, PING_BULK, SET, GET, INCR, LPUSH, RPUSH, LPOP, RPOP, SADD, HSET, SPOP, LRANGE_100, LRANGE_300, LRANGE_500, LRANGE_600, MSET)。
-
Pipeline:
-P <numreq>: 指定每个连接 pipeline 的请求数量 (默认为1)。Pipeline 可以显著提高吞吐量,因为它允许客户端在等待前一个命令的响应之前发送多个命令。
-
随机性:
-r <keyspacelen>: 对 SET/GET/INCR 等命令使用随机的 key,对 SADD 等命令使用随机的 value。<keyspacelen>定义了随机 key 的范围后缀。例如,-r 100000会生成类似mykey_rand:000000000000到mykey_rand:000000099999这样的 key。这有助于模拟更真实的缓存场景,避免总是命中同一个 key。
-
安静模式:
-q: 安静模式,只输出 QPS (每秒查询数) 结果。
-
线程 (较新版本):
--threads <num>: 指定使用的线程数 (默认为1)。对于多核 CPU,使用多线程可以更好地压测 Redis。
-
集群模式:
--cluster: 如果测试的是 Redis 集群,需要添加此参数。
输出结果解析
redis-benchmark 会为每个测试的命令输出类似以下的信息:
====== SET ======
100000 requests completed in 1.23 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.76% <= 1 milliseconds
100.00% <= 1 milliseconds
81300.81 requests per second
关键指标包括:
- requests completed in … seconds: 完成指定请求数所花费的时间。
- parallel clients: 并发客户端数量。
- bytes payload: 数据负载大小。
- …% <= … milliseconds: 不同百分位的请求延迟。例如,
99.76% <= 1 milliseconds表示 99.76% 的请求在 1 毫秒内完成。这有助于了解延迟的分布情况。 - requests per second (QPS): 每秒处理的请求数。这是衡量 Redis 吞吐量的主要指标。
示例
-
测试本地 Redis 默认端口,执行默认测试集:
redis-benchmark -
测试特定主机和端口,使用 100 个并发连接,总共 100 万个请求:
redis-benchmark -h myredishost -p 6380 -c 100 -n 1000000 -
只测试 SET 和 GET 命令,数据大小为 256 字节,使用 pipeline (每个 pipeline 16 个请求):
redis-benchmark -t SET,GET -d 256 -P 16 -
安静模式,只看 QPS:
redis-benchmark -q
4.3 测试结果
我们指定如下测试选项:
# 1. 在一个 Terminal 中启动 server
➜ ~ xmake run server
# 2. 在另一个 Terminal 开启 redis-benchmark
➜ ~ redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000 -q -t SET,GET,INCR,SADD,HSET,ZADD
WARNING: Could not fetch server CONFIG
SET: 142653.36 requests per second, p50=0.527 msec
GET: 134589.50 requests per second, p50=0.503 msec
INCR: 132802.12 requests per second, p50=0.503 msec
SADD: 131233.59 requests per second, p50=0.519 msec
HSET: 123456.79 requests per second, p50=0.583 msec
ZADD: 126422.25 requests per second, p50=0.615 msec
启动测试时, 你需要确保以下几点:
- 使用
release模型编译- 更改日志级别为
info, 否则会输出大量日志, 影响测试结果。你如果确定代码没有bug,甚至可以关闭日志输出- 日志输出使用
reset_log_level进行
这是作者的实现的测试结果, 同时我们可以用官方的redis-server测试进行对比:
# 1. 在一个 Terminal 中启动 server
➜ ~ redis-server
# 2. 在另一个 Terminal 开启 redis-benchmark
➜ ~ redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000 -q -t SET,GET,INCR,SADD,HSET,ZADD
SET: 117647.05 requests per second, p50=0.527 msec
GET: 134228.19 requests per second, p50=0.527 msec
INCR: 132450.33 requests per second, p50=0.535 msec
SADD: 125628.14 requests per second, p50=0.551 msec
HSET: 128205.13 requests per second, p50=0.527 msec
ZADD: 137362.64 requests per second, p50=0.535 msec
这里我们对SET,GET,INCR,SADD,HSET,ZADD命令的实现的性能与redis-server的性能相近, 且有些许性能优势。你可以对比你自己的实现和redis-server的QPS, 预期的结果是与redis-server的QPS在同一数量级。
压测之后呢? 这里的压测本身不是我们的目的, 你需要关注的是压测反映出的性能不足问题, 并修改相应代码的实现。
Lab 7 WiscKey 键值分离
1 背景:LSM Tree 的写放大问题
1.1 写放大的根源
在前几个 Lab 中,我们已经完整地实现了 LSM Tree 的核心流程:
put(k, v) → MemTable → flush → L0 SST → Compact → L1/L2/... SST
每次 Compact,系统需要把多个 SST 文件读入内存,归并排序后再写回磁盘。这个“读 + 重写“的过程对 key 来说是必要的(因为要合并多个版本、消除重复),但对 value 来说却是纯粹的冗余开销——value 本身并没有发生任何变化,但它随着 key 被反复读写。
以一个具体例子量化这个问题。假设:
- LSM Tree 共 3 层(L0、L1、L2),层间放大系数为 10
- 平均 value 大小为 1 KB,key 大小为 16 B
- 一条数据从 L0 最终沉降到 L2,需要参与约 30 次 Compact
那么每写入 1 KB 的有效数据,实际产生的磁盘写入约为 30 KB,写放大系数达 30 倍。当 value 更大(如视频、图片的元数据、JSON blob),写放大会随之线性增长,成为系统吞吐量的主要瓶颈。
1.2 问题的本质
观察 Compact 做的两件事:
- key 的合并:消除旧版本,对多个 SST 的 key 排序归并 → 这是 LSM Tree 的核心语义,不可省略
- value 的重写:将 value 随 key 一起拷贝到新 SST → 这是附带代价,可以避免
写放大的本质是:Compact 的逻辑复杂度由 key 决定,但 I/O 开销由 key + value 共同决定。当 value 占主导时,大量 I/O 用于搬运与合并逻辑无关的数据。
1.3 WiscKey 的解法
WiscKey(来自论文 WiscKey: Separating Keys from Values in SSD-Conscious Storage,FAST 2016)提出了一个直接的解法:
将 key 和 value 分开存储。SST 中只存 key 和一个 12 字节的位置引用;value 本体追加写入一个独立的顺序日志文件(Value Log,简称 VLog)。
这样 Compact 时只需重写体量很小的 key 部分。value 始终待在 VLog 中原地不动,写放大因此大幅降低。
这个思路简单,但实现涉及多个组件的协调,以及一些微妙的边界情况。本 Lab 将带你一步步实现它。
2 整体架构
2.1 组件拓扑对比
引入 WiscKey 前后,系统多了一个顺序追加的 VLog 文件。其余组件(MemTable、SST 层级、Compact 流程)的结构完全不变,变化仅在于 SST 文件中存什么:
┌─────────────────────────────────────────────────────────────────────────────┐
│ 原有架构(内联模式) │
│ │
│ put(k, v) ──► MemTable ──► flush ──► SST ◄── get(k) │
│ │ │
│ Block: [ key | value(完整) | tranc_id ] │
└─────────────────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────────┐
│ WiscKey 架构(大 value 分离) │
│ │
│ put(k, v) ──► MemTable ──► flush ──► SST ◄── get(k) │
│ │ │ │ │
│ (大value时) Block: resolve_value() │
│ │ [ key | vlog_ref(12B) | tranc_id ] │
│ │ │ │ │
│ ▼ └──────────────┘ │
│ VLog │ │
│ ┌─────────────┐ │ read_value(offset, size) │
│ │ append-only │ ◄───────────┘ │
│ │ .data file │ │
│ └─────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
关键区别:
- 小 value(
<= wisckey_threshold)继续内联存入 SST Block,行为与原来完全一致 - 大 value(
> wisckey_threshold)在 flush 时被分流写入 VLog,SST Block 中只存 12 字节的位置引用 - Compact 时 SST 中的 key 部分照常重写,但 VLog 中的 value 原地不动,写放大因此降低
2.2 为什么设置阈值?
你可能会问:既然分离 value 能降低写放大,为什么不把所有 value 都分离?
原因在于读放大的代价。对于内联存储,get 操作在找到 SST 条目后立刻得到 value;对于 WiscKey 模式,get 需要额外一次随机磁盘读(读 VLog)。对于小 value,这次额外的随机读代价远超写放大收益。
因此 WiscKey 采用阈值策略:
- 小 value(如短字符串、数字):内联存储,读性能不变
- 大 value(如 JSON、二进制 blob):分离到 VLog,显著降低 Compact I/O
在我们的实现中,阈值由 config.toml 的 wisckey_value_threshold 配置,默认为 0(禁用,完全内联)。
2.3 写入与读取路径概览
写入路径(大 value):
put("k", "large_value")
│
▼
MemTable.put("k", "large_value") ← 内存中仍存完整 value
│
│ (触发 flush)
▼
SSTBuilder.add("k", "large_value")
│
├──► VLog.append("k", "large_value") ──► 返回 offset=X, size=N
│
└──► Block.add_entry("k", [X:8B][N:4B], tranc_id)
└─ 12字节 vlog 引用写入 SST
读取路径:
get("k")
│
▼
MemTable.get("k") ── 未命中 ──► SST.get("k")
│
▼
SstIterator 定位到 entry
│
▼
(*iter).second
= resolve_value([X:8B][N:4B])
│
▼
VLog.read_value(offset=X, size=N)
│
▼
返回 "large_value"
注意 MemTable 中始终存储完整 value——分离只发生在 flush 到磁盘时,而不是写入时。这样可以保证内存中的读取路径不受影响。
3 VLog 文件格式
VLog 是一个只追加的二进制文件,所有记录顺序写入,偏移量单调递增。
3.1 为什么存 key?
你可能注意到 VLog 的记录格式中包含 key,而 key 已经在 SST 中存储了。重复存储 key 的原因是:
- 数据校验:CRC32 覆盖 key + value,可以检测 VLog 文件的物理损坏
- 垃圾回收(GC):VLog GC 时需要顺序扫描 VLog,判断某条记录是否仍被 SST 引用。有了 key,GC 才能在不读 SST 的情况下定位当前最新的 vlog 引用(本 Lab 不要求实现 GC,但格式设计需要支持它)
3.2 单条记录的字节布局
每次调用 VLog::append(key, value) 追加一条记录,格式如下:
VLog 文件内部结构(每条记录):
┌──────────┬─────────────┬──────────┬──────────────┬──────────┐
│ key_len │ key │ val_len │ value │ crc32 │
│ uint16 │ key_len 字节 │ uint32 │ val_len 字节 │ uint32 │
│ (2B) │ │ (4B) │ │ (4B) │
└──────────┴─────────────┴──────────┴──────────────┴──────────┘
↑ offset ↑ value 起始位置 ↑ 校验覆盖范围结束
= offset + 2 + key_len + 4
CRC32 校验覆盖:从 key_len 到 value 末尾的所有字节(不含 crc32 本身)
VLog::append 返回该条记录的起始偏移量(即写入前 file_.size() 的值),这个值会被存入 SST Block 的 vlog 引用中。
3.3 VLog 文件全局视图
VLog 文件(vlog.data):
offset=0 offset=A offset=B offset=C
↓ ↓ ↓ ↓
┌───────────────┬───────────────────┬───────────────────┬────────── ...
│ record for │ record for │ record for │
│ key1/value1 │ key2/value2 │ key3/value3 │ ...
└───────────────┴───────────────────┴───────────────────┴────────── ...
└─ SST中存 A=0 └─ SST中存 B=... └─ SST中存 C=...
SST Block 中对应的 vlog 引用(12 字节):
┌─────────────────────┬────────────────┐
│ vlog_offset │ value_size │
│ uint64 (8B) │ uint32 (4B) │
└─────────────────────┴────────────────┘
记录在 VLog 中的起始偏移 value 的原始字节长度
(即 VLog::append 的返回值)(用于定位 value 结束位置)
读取时,resolve_value 持有这 12 字节,调用 VLog::read_value(offset, size) 即可取回原始 value,整个过程对上层迭代器完全透明。
4 SST 文件格式扩展(WiscKey Footer)
4.1 为什么需要扩展 footer?
系统重启时,SST::open 需要从磁盘加载所有 SST 文件。此时有一个关键问题:
这个 SST 文件里存的是完整 value,还是 12 字节的 vlog 引用?
如果判断错误——把 vlog 引用当作真实 value 返回,或者把真实 value 当作 vlog 引用去读——数据将发生损坏。
一个简单的解法是:把存储模式写入 SST footer。这样只要看 footer 就能知道该如何解析 Block 中的 value 字段。
4.2 两种 footer 格式对比
老格式 footer(24 字节):
[meta_offset : uint32] @ size-24
[bloom_offset: uint32] @ size-20
[min_tranc_id: uint64] @ size-16
[max_tranc_id: uint64] @ size-8
WiscKey footer(26 字节):
[meta_offset : uint32] @ size-26
[bloom_offset: uint32] @ size-22
[min_tranc_id: uint64] @ size-18
[max_tranc_id: uint64] @ size-10
[storage_mode: uint8 ] @ size-2 (1 = WiscKey)
[magic : uint8 ] @ size-1 (0x4B,作为格式标识)
最后 1 字节的 magic 值 0x4B(即字符 'K',取自 WiscKey 首字母)是格式探测的锚点——SST::open 通过检查这一字节来决定使用哪种 footer 解析方式,从而实现与旧格式的向后兼容。
SST::open 在读取时,会检查文件末尾字节是否等于 0x4B(WISCKEY_MAGIC)来决定使用哪种 footer 解析方式。
5 代价与权衡
WiscKey 不是免费的午餐,引入它会带来新的代价:
| 指标 | 内联模式 | WiscKey 模式 |
|---|---|---|
| 写放大 | 高(value 随 key 多次重写) | 低(value 只写一次) |
| 读放大 | 低(单次 SST 读取) | 略高(SST + VLog 随机读) |
| 空间放大 | 低(Compact 清理旧版本) | 高(VLog 死记录不自动清理) |
空间放大是 WiscKey 的主要代价:Compact 后,新 SST 可能不再引用 VLog 中的某些旧记录,但那些记录仍然占据磁盘空间。解决方案是 VLog GC(垃圾回收),它通过扫描 VLog 并与当前 SST 中的引用对比,回收无效记录。本 Lab 不要求实现 GC,但了解这个代价有助于理解 WiscKey 的整体设计逻辑。
6 涉及的组件和文件
本 Lab 你需要修改或实现的文件:
| 文件 | 主要内容 |
|---|---|
src/vlog/vlog.cpp | VLog 的打开、追加、读取 |
src/sst/sst.cpp | SSTBuilder WiscKey 构造函数、SST::open footer 检测、resolve_value |
src/lsm/engine.cpp | LSMEngine 构造函数初始化 VLog,flush 和 gen_sst_from_iter 按配置选择 WiscKey 模式 |
include/vlog/vlog.h | VLog 类定义(已提供,只需实现 cpp) |
config.toml | wisckey_value_threshold 配置项 |
建议按顺序完成:
- Lab 7.1:实现 VLog 的三个核心接口(open / append / read_value)
- Lab 7.2:在 SSTBuilder 和 SST 中接入 VLog,处理 WiscKey footer
- Lab 7.3:在 LSMEngine 中初始化 VLog,在 flush 和 compact 路径中选择正确的 SSTBuilder
每个 Lab 完成后可以运行 xmake run test_wisckey 验证进度。
Lab 7.1 VLog 实现
1 VLog 的设计目标
在开始写代码之前,先思考 VLog 需要满足哪些约束:
-
只追加:写入操作只在文件末尾追加,不修改已有记录。这使得 VLog 天然适合顺序写,也简化了并发控制——多个写入者只需保证追加的原子性,不需要锁整个文件。
-
重启恢复:系统重启后,VLog 文件中已有的记录必须保留(
open时不截断),否则 SST 中指向旧记录的引用将失效。 -
随机读:
get操作需要根据 SST 中存储的偏移量直接跳到 VLog 文件的任意位置读取 value,不需要顺序扫描。 -
数据校验:每条记录附带 CRC32 校验,以检测磁盘静默错误或写入中断导致的数据损坏。
这些约束共同决定了 VLog 的接口和文件格式设计。
先看头文件定义:
// include/vlog/vlog.h
class VLog {
public:
// 打开或创建 VLog 文件(不截断已有内容)
static std::shared_ptr<VLog> open(const std::string &path);
// 追加一条 KV 记录,返回该记录在文件中的起始偏移量
uint64_t append(const std::string &key, const std::string &value);
// 从指定偏移量读取 value(需要提供 value 的长度)
std::string read_value(uint64_t offset, uint32_t value_size);
// 返回当前文件的末尾偏移(== 文件大小)
uint64_t tail_offset() const;
void sync();
void del_vlog();
private:
FileObj file_;
std::string path_;
mutable std::mutex append_mtx_; // 保护并发 append
};
接口设计上有一个值得注意的细节:read_value 接受 value_size 参数,而不是自己从 VLog 记录中解析出 value 长度。这是因为调用方(SST::resolve_value)已经从 vlog 引用中拿到了 value 大小,避免一次多余的读取;同时也使 read_value 的职责更单一——它只负责“在给定位置读取给定长度的数据“。
2 代码实现
需要修改 src/vlog/vlog.cpp。
2.1 VLog::open
open 是 VLog 的工厂函数,负责打开或创建 VLog 文件:
std::shared_ptr<VLog> VLog::open(const std::string &path) {
// TODO: Lab 7.1 打开或创建 VLog 文件
// ? 1. 若文件不存在则创建空文件
// ? 2. 用 FileObj::open(path, false) 打开(不截断,保留已有记录)
// ? 3. 记录 path_ 和 file_
return nullptr;
}
这里使用 FileObj::open(path, false) 而非截断模式,目的是重启后不丢失已有的 vlog 记录。如果在 open 时截断,所有 SST 中指向旧 VLog 偏移的引用就会失效,导致数据损坏。
2.2 VLog::append
append 是 VLog 的核心写入接口,将一条 KV 记录顺序追加到文件末尾:
uint64_t VLog::append(const std::string &key, const std::string &value) {
// TODO: Lab 7.1 追加一条 KV 记录到 VLog,返回记录起始偏移量
// ? 加 append_mtx_ 互斥锁(支持并发写)
// ? offset = file_.size()(追加前的文件大小即为本次记录的起始偏移)
// ? 记录格式: [key_len:uint16][key][val_len:uint32][value][crc32:uint32]
// ? CRC32 覆盖除自身之外的所有字段
// ? 使用 file_.append(buf) 写入
return 0;
}
记录格式的字节布局,结合 Lab 7 概述中的格式描述:
offset + 0 : key_len (uint16_t, 2 bytes)
offset + 2 : key (key_len bytes)
offset + 2 + key_len : val_len (uint32_t, 4 bytes)
offset + 2 + key_len + 4 : value (val_len bytes)
offset + 2 + key_len + 4 + val_len : crc32 (uint32_t, 4 bytes)
CRC32 的计算需要覆盖从 key_len 字段到 value 末尾的所有字节——也就是除 crc32 本身之外的所有内容。这样一旦任何字段发生损坏,校验就会失败。
注意:append 返回的是写入前的 file_.size(),也就是本次记录的起始偏移量。这个值将被 SSTBuilder 编码进 SST Block 的 vlog 引用中(8 字节的 vlog_offset 字段)。
2.3 VLog::read_value
read_value 根据偏移量随机读取 VLog 中的 value:
std::string VLog::read_value(uint64_t offset, uint32_t value_size) {
// TODO: Lab 7.1 从指定 offset 读取 value
// ? 先读 key_len (uint16_t, 2 bytes) 以跳过 key
// ? value 起始位置 = offset + 2 + key_len + 4
// ? 读取 value_size 个字节返回
return "";
}
读取流程:
- 从
offset处读 2 字节,得到key_len - 跳过
key_len字节的 key 内容 - 再跳过 4 字节的
val_len字段(我们不需要用它,因为调用方已经传入了value_size) - 从当前位置读取
value_size字节,返回 value
这里故意不校验 CRC,理由是:
- 写入路径已经通过 CRC 保证了数据完整性
- 若 VLog 末尾有不完整的写入(如崩溃时),对应的 SST 引用在 WAL 恢复阶段已被处理,
read_value不会被调用到那些损坏的偏移 - CRC 校验主要用于 GC 扫描时检测死记录,本 Lab 不涉及
3 测试
完成 VLog 实现后,可以单独验证 append 和 read_value 的正确性:
// 验证思路
auto vlog = VLog::open("/tmp/test.data");
uint64_t off = vlog->append("key1", "hello_world");
assert(vlog->read_value(off, 11) == "hello_world");
需要同时完成 Lab 7.2 和 Lab 7.3 后,才能运行完整的端到端测试:
xmake run test_wisckey
完成 VLog 实现后,继续阅读 Lab 7.2,了解如何在 SST 层接入 VLog,以及 WiscKey footer 的格式设计。
Lab 7.2 SSTBuilder 和 SST 的 WiscKey 支持
在 Lab 7.1 中,我们实现了 VLog 的底层存储接口。现在需要让 SST 层“感知“VLog 的存在,在写入时将大 value 分流到 VLog,在读取时透明地完成解引用。
这一层的核心挑战是透明性:上层调用方(MemTable、Compact 迭代器)不应感知到 value 被分离了——get 返回的 value 必须和内联模式下完全一致。
1 SSTBuilder WiscKey 构造函数
SSTBuilder 已有一个普通构造函数(Lab 3.5 中实现)。WiscKey 模式通过新增一个重载构造函数来引入:
// 普通模式(已有)
SSTBuilder::SSTBuilder(size_t block_size, bool has_bloom);
// WiscKey 模式:value 超过阈值时写入 vlog,SST 中只存 12 字节引用
SSTBuilder::SSTBuilder(size_t block_size, bool has_bloom,
std::shared_ptr<VLog> vlog,
size_t wisckey_threshold)
: block(block_size), vlog_(std::move(vlog)),
wisckey_threshold_(wisckey_threshold), storage_mode_(1) {
// ...
}
注意 storage_mode_ 被初始化为 1,这个值在 build 时会写入 SST footer,以便重启后的 SST::open 能正确识别文件格式(详见第 4 节)。
add 方法的 WiscKey 分支
WiscKey SSTBuilder 的 add 方法在满足以下全部条件时触发 value 分离:
storage_mode_ == 1(WiscKey 模式)vlog_非空value非空(删除标记不分离)value.size() > wisckey_threshold_
此时核心逻辑变为:
// WiscKey: 将大 value 写入 vlog,SST 中存储 12 字节引用
uint64_t offset = vlog_->append(key, value);
// 构造 12 字节的 vlog 引用
vlog_ref.resize(sizeof(uint64_t) + sizeof(uint32_t));
uint32_t val_size = static_cast<uint32_t>(value.size());
memcpy(vlog_ref.data(), &offset, sizeof(uint64_t));
memcpy(vlog_ref.data() + sizeof(uint64_t), &val_size, sizeof(uint32_t));
actual_value = &vlog_ref; // 用引用代替原始 value 写入 block
12 字节的构成:
- 前 8 字节:
vlog_offset(uint64_t),即VLog::append返回的起始偏移量 - 后 4 字节:
value_size(uint32_t),原始 value 的字节数(用于告知read_value读多少字节)
2 SST::open 的 WiscKey 检测
SST::open 在读取 footer 时需要先探测文件格式:
std::shared_ptr<SST> SST::open(size_t sst_id, FileObj file,
std::shared_ptr<BlockCache> block_cache,
std::shared_ptr<VLog> vlog) {
// ...(原有 Lab 3.6 逻辑)...
// 新增:检测 WiscKey footer
// 1. 若 file_size >= 26 且 file[-1] == WISCKEY_MAGIC (0x4B)
// 则使用 26 字节 footer,读取 storage_mode_ = file[-2]
// 2. 否则使用 24 字节老 footer
// 新增:将 vlog 赋值给 sst->vlog_
}
对于普通模式的 SST,vlog 参数为 nullptr,storage_mode_ 保持 0,resolve_value 直接返回原始值,完全向后兼容。
3 SST::resolve_value
resolve_value 是 WiscKey 的“解引用“接口,在读取 SST 时被迭代器调用,对上层完全透明:
std::string SST::resolve_value(const std::string &raw_value) const {
if (storage_mode_ == 0 || raw_value.empty()) {
return raw_value; // 普通模式,直接返回
}
// WiscKey 模式:raw_value 是 12 字节引用
// 解析 [offset:8][size:4] 并调用 vlog_->read_value
uint64_t off = 0;
uint32_t sz = 0;
memcpy(&off, raw_value.data(), sizeof(uint64_t));
memcpy(&sz, raw_value.data() + sizeof(uint64_t), sizeof(uint32_t));
return vlog_->read_value(off, sz);
}
这个函数由 SstIterator 在对外返回 value 时调用。调用方得到的 value 与内联模式下完全相同,不需要感知 WiscKey 的存在。
4 build 中的 WiscKey footer
4.1 为什么要扩展 footer?
回顾你在 Lab 3.5 中实现的普通 SST footer(24 字节):
SST 文件末尾(普通模式,24 字节 footer):
┌─────────────────────────────────────────────────────────────────┐
│ ...Block Section... │ Meta Section │ Bloom Section │ Footer│
└─────────────────────────────────────────────────────────────────┘
Footer 内部布局(共 24 字节,从 size-24 开始读):
┌──────────────────┬──────────────────┬──────────────────┬──────────────────┐
│ meta_offset │ bloom_offset │ min_tranc_id │ max_tranc_id │
│ uint32 (4B) │ uint32 (4B) │ uint64 (8B) │ uint64 (8B) │
└──────────────────┴──────────────────┴──────────────────┴──────────────────┘
↑ file[size-24] ↑ file[size-20] ↑ file[size-16] ↑ file[size-8]
这个 footer 记录了各 Section 的位置和事务 id 范围,使得 SST::open 能从文件末尾反向定位所有内容。
WiscKey 模式的问题:重启后 SST::open 如何知道这个 SST 文件存的是内联 value 还是 vlog 引用?如果判断错了,会把 12 字节的 vlog 引用当成真实 value 返回,或者反过来把真实 value 当成 vlog 引用去读,数据就会损坏。
4.2 解决方案:追加 2 个标志字节
在原有 24 字节 footer 末尾追加 2 个字节,形成 26 字节的 WiscKey footer:
SST 文件末尾(WiscKey 模式,26 字节 footer):
┌──────────────────┬──────────────────┬──────────────────┬──────────────────┬──────┬───────┐
│ meta_offset │ bloom_offset │ min_tranc_id │ max_tranc_id │ mode │ magic │
│ uint32 (4B) │ uint32 (4B) │ uint64 (8B) │ uint64 (8B) │ 1B │ 1B │
└──────────────────┴──────────────────┴──────────────────┴──────────────────┴──────┴───────┘
↑ file[size-26] ↑ file[size-22] ↑ file[size-18] ↑ file[size-10] ↑ -2 ↑ -1
= 0x01 = 0x4B
mode:存储模式,0x01表示 WiscKey,0x00表示内联(普通模式不写这两字节)magic:固定值0x4B(即字符'K',取自 WiscKey 首字母),作为格式标识符
4.3 SST::open 的格式探测
SST::open 的检测逻辑基于最后 1 字节:
SST::open 的 footer 检测流程:
file[-1] == 0x4B ?
├── Yes → WiscKey footer(从 size-26 开始读)
│ → storage_mode_ = file[-2](= 1)
│ → sst->vlog_ = vlog 参数
└── No → 普通 footer(从 size-24 开始读)
→ storage_mode_ = 0
→ sst->vlog_ = nullptr
这个检测对旧格式完全向后兼容:旧 SST 文件的最后 1 字节是 max_tranc_id 的低字节,通常不等于 0x4B,因此不会被误判为 WiscKey 格式。
4.4 build 时写入 WiscKey footer
SSTBuilder::build 在 WiscKey 模式下写 footer 时,在原有 24 字节后追加这 2 个字节:
// WiscKey 额外的 2 字节(追加在普通 24 字节 footer 之后)
if (storage_mode_ == 1) {
file_content.push_back(storage_mode_); // 0x01
file_content.push_back(WISCKEY_MAGIC); // 0x4B
}
注意字段顺序:mode 在前,magic 在后。读取时从文件末尾往前读,先遇到 magic(file[-1]),再读 mode(file[-2])。
5 测试
完成本节实现后,可以运行:
xmake run test_wisckey
[==========] Running N tests from 1 test suite.
[ RUN ] WiscKeyTest.BasicPutGet
[ OK ] WiscKeyTest.BasicPutGet (X ms)
[ RUN ] WiscKeyTest.LargeValue
[ OK ] WiscKeyTest.LargeValue (X ms)
[ RUN ] WiscKeyTest.Persistence
[ OK ] WiscKeyTest.Persistence (X ms)
[ RUN ] WiscKeyTest.MixedInlineAndVLog
[ OK ] WiscKeyTest.MixedInlineAndVLog (X ms)
完成 SST 层的 WiscKey 支持后,继续阅读 Lab 7.3,了解如何在 LSMEngine 中将 VLog 初始化并接入到 flush 和 compact 路径中。
Lab 7.3 Engine 集成 WiscKey
在 Lab 7.1 和 Lab 7.2 中,我们分别实现了 VLog 的存储接口和 SST 层的 WiscKey 支持。现在需要在 LSMEngine 层把这两者连接起来——初始化 VLog,并在 flush 和 compact 时将它传入 SSTBuilder。
这一层的工作相对简单,但有几个细节值得注意。
1 配置项
WiscKey 的行为由 config.toml 中的配置项控制:
[lsm.wisckey]
# value 超过此阈值(字节)才会被分离到 VLog
# 设置为 0 表示禁用 WiscKey,完全使用内联模式
wisckey_value_threshold = 1024
在代码中通过 TomlConfig::getInstance().getWisckeyValueThreshold() 获取此值。
当阈值为 0 时,所有 value 都走内联路径,行为与引入 WiscKey 之前完全一致。这是默认的非破坏性配置,确保现有测试(test_lsm、test_sst 等)不受影响。
2 LSMEngine 构造函数
2.1 为什么无论如何都要初始化 VLog?
LSMEngine 在初始化时必须打开 VLog,即使 WiscKey 阈值为 0:
// 无论是否启用 WiscKey,都初始化 vlog_
vlog_ = VLog::open(data_dir + "/vlog.data");
原因如下:
-
重启恢复的正确性:即使当前配置禁用了 WiscKey,磁盘上可能已经存在之前以 WiscKey 模式写入的 SST 文件。如果
vlog_为空,这些 SST 在resolve_value时会因为vlog_为空而崩溃。 -
开销可忽略:
VLog::open只是打开(或创建)一个文件,不加载任何数据。对非 WiscKey 场景几乎没有影响。
2.2 加载 SST 时传入 VLog
加载 SST 文件时,将 vlog_ 传入 SST::open:
auto sst = SST::open(sst_id, FileObj::open(sst_path, false), block_cache, vlog_);
SST::open 内部会通过 footer magic 判断该文件是否为 WiscKey 格式,再决定是否使用传入的 vlog_。对于普通格式的 SST,vlog_ 参数被忽略(sst->vlog_ 设为 nullptr)。
3 flush 中的 SSTBuilder 选择
LSMEngine::flush 在构造 SSTBuilder 时,根据 WiscKey 配置选择不同的构造函数:
size_t wk = TomlConfig::getInstance().getWisckeyValueThreshold();
SSTBuilder builder = (wk > 0 && vlog_)
? SSTBuilder(TomlConfig::getInstance().getLsmBlockSize(), true, vlog_, wk)
: SSTBuilder(TomlConfig::getInstance().getLsmBlockSize(), true);
两个条件缺一不可:
wk > 0:配置层面启用了 WiscKeyvlog_非空:VLog 已成功初始化
两者都满足时,使用 WiscKey 构造函数,add 会对超过阈值的 value 自动调用 vlog_->append 分流。
4 gen_sst_from_iter 中的 SSTBuilder 选择
Compact 时同样需要根据配置选择 WiscKey 或普通模式:
std::vector<std::shared_ptr<SST>>
LSMEngine::gen_sst_from_iter(BaseIterator &iter, size_t target_sst_size,
size_t target_level) {
size_t wk = TomlConfig::getInstance().getWisckeyValueThreshold();
auto new_sst_builder = (wk > 0 && vlog_)
? SSTBuilder(block_size, true, vlog_, wk)
: SSTBuilder(block_size, true);
// ...
}
4.1 Compact 路径的特殊情况
Compact 时,迭代器遍历的 entry 其 value 可能已经是 12 字节的 vlog 引用(来自之前 flush 的 WiscKey 格式 SST)。此时 SSTBuilder::add 收到的 value 大小为 12 字节:
full_compact(level=0)
│
▼
gen_sst_from_iter(iter, ...)
│
│ iter 遍历 L0 + L1 的所有 entry
│ entry.value = [X:8B][N:4B] ← 仍是 vlog 引用(12字节)
│
▼
SSTBuilder(WiscKey 模式).add("key", [X:8B][N:4B], tranc_id)
│
│ value.size() == 12 ≤ threshold(vlog 引用本身很小)?
│
├── 若 threshold > 12:引用被当作"小 value"直接内联 ← 此处有潜在问题
│ 实现时需特别注意
└── 若 threshold ≤ 12:引用再次被 append 到 VLog
← 产生 VLog 空间放大(旧记录变垃圾)
← GC 是进阶内容,本 Lab 不要求
这里有一个微妙的情况:当阈值大于 12 时,12 字节的 vlog 引用被视为“小 value“内联写入了新 SST,而不是再次追加到 VLog——这实际上是正确的行为,Compact 后新 SST 中仍然存储的是 vlog 引用,读取时 resolve_value 依然能正确解析。
注意:Compact 过程中,若 threshold ≤ 12,已经存入 VLog 的 value 会被再次调用
vlog_->append写入,这会产生 VLog 的空间放大。VLog 的垃圾回收(GC)是 WiscKey 的进阶内容,本 Lab 不要求实现,仅需保证功能正确性。
5 整体数据流
5.1 写路径:flush 时的分流
put("key", "large_value") [large_value.size() > threshold]
│
▼
┌─────────────┐
│ MemTable │ put("key", "large_value") ← 内存中仍存完整 value
└─────────────┘
│ 触发 flush(内存超限)
▼
┌───────────────────────────────────────────────────────┐
│ SSTBuilder(WiscKey 模式) │
│ │
│ add("key", "large_value", tranc_id) │
│ │ │
│ ├─ value.size() > threshold ? │
│ │ │ Yes │
│ │ ▼ │
│ │ VLog::append("key", "large_value") │
│ │ │ │
│ │ └──► 写入 vlog.data │
│ │ 返回 offset=X, size=N │
│ │ │
│ └─► Block::add_entry( │
│ key = "key", │
│ value = [X:8B][N:4B], ← 12字节引用 │
│ tranc_id) │
└───────────────────────────────────────────────────────┘
│ build()
▼
┌──────────────────────────────────────────────────────────────┐
│ sst_00000...001.0 (磁盘文件) │
│ │
│ Block_0: [ "key" | offset=X,size=N | tranc_id ] ... │
│ ... │
│ Meta Section | Bloom Section | Footer(26B, magic=0x4B) │
└──────────────────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ vlog.data (磁盘文件) │
│ │
│ offset=0 offset=X │
│ ↓ ↓ │
│ [rec0: k0/v0] ... [rec: "key"/"large_value" | crc32] ... │
└──────────────────────────────────────────────────────────────┘
5.2 读路径:resolve_value 透明解引用
get("key")
│
▼
MemTable::get("key") ── 未命中 ──► SST::get("key")
│
│ find_block_idx → read_block
▼
BlockIterator 定位到 entry
│
│ entry.value = [X:8B][N:4B]
▼
SstIterator::operator*()
│
▼
sst_->resolve_value([X:8B][N:4B])
│
storage_mode_ == 1 ?
│ Yes
▼
解析 offset=X, size=N
│
▼
vlog_->read_value(X, N)
│
│ 定位到 vlog.data[X]
│ 跳过 key_len + key + val_len
│ 读取 N 字节
▼
返回 "large_value"
│
◄──────┘ 对调用方透明,
与内联模式返回值格式完全相同
5.3 Compact 路径:key 重写,value 不动
full_compact(level=0)
│
▼
gen_sst_from_iter(iter, ...)
│
│ iter 遍历 L0 + L1 的所有 entry
│ entry.value = [X:8B][N:4B] ← 仍是 vlog 引用
│
▼
SSTBuilder(WiscKey 模式).add("key", [X:8B][N:4B], tranc_id)
│
│ value.size() == 12 ≤ threshold(vlog 引用本身很小)
│ → 直接内联写入新 SST(不再次写 VLog)
│
▼
compact 结果:新 SST 中 key 重新排布,vlog.data 内容原地不变
Compact 后 VLog 中可能积累大量已无 SST 引用的“死记录“,这是 WiscKey 的空间放大代价。论文中通过在线 GC 线程解决,本 Lab 仅需实现写入和读取的正确性,GC 留作后续拓展。
6 代价与收益的再审视
完成所有实现后,可以从数据流的视角再次对比两种模式的代价:
写放大的变化:
- 内联模式:value 随 key 参与每次 Compact,每层一次重写
- WiscKey 模式:value 只在 flush 时写入 VLog 一次,此后 Compact 不再触碰 value 内容
读放大的变化:
- 内联模式:
get→ SST 随机读 1 次 - WiscKey 模式:
get→ SST 随机读 1 次 + VLog 随机读 1 次
空间放大的变化:
- 内联模式:Compact 会清除旧版本,空间放大受控
- WiscKey 模式:VLog 只追加不删除,旧版本数据在 GC 之前一直占用磁盘空间
WiscKey 最适合 value 远大于 key、且以写密集型负载为主的场景(如对象存储、时序数据库的大值存储)。对于 key/value 大小相近或读密集型场景,内联模式的综合性能可能更优。
7 测试
xmake run test_wisckey
你应该能通过所有 WiscKey 相关测试,同时原有的 test_lsm、test_sst 等测试不应受到影响(因为 WiscKey 阈值默认配置为 0 时完全退化为原有行为)。
结语
本项目的初衷是作为LSM Tree的入门课程, 使参与者入门数据存储领域。这个Lab从代码实现, 到最后Lab文档的设计, 耗时半年, 花费了作者非常多的心血。因此, 如果您觉得这个Lab对您有帮助, 请在GitHub上给这个Lab一个Star。
致谢
感谢网友koi对本项目文档的校正与补全, 让这个Lab的文档更加完善。
同时感谢以下为本项目贡献过源码的网友:
下一步?
当然,这个项目的定位只是让你初步入门LSM Tree和存储领域, 如果你想深入理解LSM Tree,建议阅读leveldb/rocksdb的源码。
此外,以下是一些存储领域的开源学习资料和项目,供进一步学习:
- Apache Cassandra: 一个分布式 NoSQL 数据库,广泛使用 LSM Tree 作为其存储引擎的核心。
- HBase: 一个基于 Hadoop 的分布式数据库,适合处理大规模结构化数据。
- TiDB: 一个开源的分布式 SQL 数据库,支持水平扩展和强一致性。
- ClickHouse: 一个用于在线分析处理 (OLAP) 的列式数据库管理系统。
- FoundationDB: 一个分布式数据库,提供事务支持,适合构建复杂的存储系统。
- DuckDB: 一个嵌入式分析数据库,适合处理小型到中型数据集。
- SQLite: 一个轻量级嵌入式数据库,适合学习存储引擎的基础知识。
- bbolt: 一个嵌入式键值数据库,基于 B+ 树实现,适合学习与 LSM Tree 不同的存储结构。
- Ceph: 一个统一的分布式存储系统,支持对象存储、块存储和文件存储,广泛应用于云计算和大规模存储场景。
通过研究这些项目的源码和文档,你可以更全面地了解存储系统的设计与实现。
附录
这里列出一些学习资源或参考资料,供读者参考。
RESP 常见格式
常见 Redis 命令及其 RESP 编码
1. SET
设置指定键的值。
-
命令格式:
*3 $3 SET $3 key $5 value -
解释:
*3表示接下来有 3 个元素。$3表示第一个元素是长度为 3 的字符串"SET"。$3表示第二个元素是长度为 3 的字符串"key".$5表示第三个元素是长度为 5 的字符串"value"。
2. GET
获取指定键的值。
-
命令格式:
*2 $3 GET $3 key -
解释:
*2表示接下来有 2 个元素。$3表示第一个元素是长度为 3 的字符串"GET".$3表示第二个元素是长度为 3 的字符串"key".
3. DEL
删除一个或多个键。
-
命令格式:
*3 $3 DEL $3 key1 $3 key2 -
解释:
*3表示接下来有 3 个元素。$3表示第一个元素是长度为 3 的字符串"DEL".$3表示第二个元素是长度为 3 的字符串"key1".$3表示第三个元素是长度为 3 的字符串"key2".
4. INCR
将键存储的数字值增加 1。
-
命令格式:
*2 $4 INCR $3 key -
解释:
*2表示接下来有 2 个元素。$4表示第一个元素是长度为 4 的字符串"INCR".$3表示第二个元素是长度为 3 的字符串"key".
5. DECR
将键存储的数字值减少 1。
-
命令格式:
*2 $4 DECR $3 key -
解释:
*2表示接下来有 2 个元素。$4表示第一个元素是长度为 4 的字符串"DECR".$3表示第二个元素是长度为 3 的字符串"key".
6. EXPIRE
设置键的过期时间(秒)。
-
命令格式:
*3 $7 EXPIRE $3 key $2 60 -
解释:
*3表示接下来有 3 个元素。$7表示第一个元素是长度为 7 的字符串"EXPIRE".$3表示第二个元素是长度为 3 的字符串"key".$2表示第三个元素是长度为 2 的字符串"60".
7. TTL
获取键的剩余生存时间(秒)。
-
命令格式:
*2 $3 TTL $3 key -
解释:
*2表示接下来有 2 个元素。$3表示第一个元素是长度为 3 的字符串"TTL".$3表示第二个元素是长度为 3 的字符串"key".
8. HSET
设置哈希表中字段的值。
-
命令格式:
*4 $4 HSET $3 hash $3 field $5 value -
解释:
*4表示接下来有 4 个元素。$4表示第一个元素是长度为 4 的字符串"HSET".$3表示第二个元素是长度为 3 的字符串"hash".$3表示第三个元素是长度为 3 的字符串"field".$5表示第四个元素是长度为 5 的字符串"value".
9. HGET
获取哈希表中字段的值。
-
命令格式:
*3 $4 HGET $3 hash $5 field -
解释:
*3表示接下来有 3 个元素。$4表示第一个元素是长度为 4 的字符串"HGET".$3表示第二个元素是长度为 3 的字符串"hash".$5表示第三个元素是长度为 5 的字符串"field".
10. LPUSH
将一个或多个值插入列表头部。
-
命令格式:
*3 $5 LPUSH $5 mylist $4 item -
解释:
*3表示接下来有 3 个元素。$5表示第一个元素是长度为 5 的字符串"LPUSH".$5表示第二个元素是长度为 5 的字符串"mylist".$4表示第三个元素是长度为 4 的字符串"item".
11. LRANGE
获取列表中指定范围的元素。
-
命令格式:
*4 $6 LRANGE $5 mylist $1 0 $1 1 -
解释:
*4表示接下来有 4 个元素。$6表示第一个元素是长度为 6 的字符串"LRANGE".$5表示第二个元素是长度为 5 的字符串"mylist".$1表示第三个元素是长度为 1 的字符串"0".$1表示第四个元素是长度为 1 的字符串"1".
测试与验证
你可以使用 redis-cli 来测试这些新实现的命令:
# 测试 DEL
redis-cli -p 6379 SET key1 "value1"
redis-cli -p 6379 SET key2 "value2"
redis-cli -p 6379 DEL key1 key2
# 测试 INCR 和 DECR
redis-cli -p 6379 SET counter 10
redis-cli -p 6379 INCR counter
redis-cli -p 6379 DECR counter
# 测试 EXPIRE 和 TTL
redis-cli -p 6379 SET tempKey "tempValue"
redis-cli -p 6379 EXPIRE tempKey 60
redis-cli -p 6379 TTL tempKey
# 测试 HSET 和 HGET
redis-cli -p 6379 HSET myhash field1 "Hello"
redis-cli -p 6379 HGET myhash field1
# 测试 LPUSH 和 LRANGE
redis-cli -p 6379 LPUSH mylist item1 item2 item3
redis-cli -p 6379 LRANGE mylist 0 2
通过这些测试命令,你可以验证你的服务器是否正确实现了这些 Redis 命令。如果有任何问题,请检查日志输出并进行相应的调试。
后续更新计划
本实验目前处于持续迭代中,已完成的更新和后续计划如下:
已更新(相较于 1.0 版本)
- 接口同步:将所有实验文档中的函数签名与
master分支最新代码对齐,包括:MemTable::flush_last新增flushed_tranc_ids输出参数Block::encode/Block::decode统一with_hash参数Block::get_tranc_id_at返回类型由uint16_t修正为uint64_tSST::open新增vlog参数(默认nullptr,向后兼容)SST::read_block参数类型改为int64_t(支持返回 -1)SST::begin新增keep_all_versions参数WAL构造函数参数max_finished_tranc_id重命名为checkpoint_tranc_id
- WAL 崩溃恢复机制更新:用
flushed_tranc_ids(std::set<uint64_t>)替代单一最大值,更精确地追踪哪些事务已完全持久化,避免“部分刷盘“导致的数据缺失。详见 Lab 5.5。 - 新增 Lab 7 WiscKey 键值分离:讲解 WiscKey 论文的核心思路、VLog 文件格式、SSTBuilder 和 SST 的 WiscKey 支持、Engine 集成方式。
后续更新计划
- 自由度提升:
1.0版本的Lab, 基本上就是在既有的项目代码下进行关键函数的挖空, 在组件设计层面没有给实验参与者太多的发挥空间, 后续应该添加更多的自由度, 允许实验者自由设计组件, 并且在组件设计中添加更多的测试用例。 - 测试用例覆盖率不足:
1.0版本的Lab中, 测试用例的覆盖率比较低, 比如对崩溃恢复的各种边界条件的考虑不足, 当然这确实也比较难控制就是了。 - 各个
Lab工作量不尽相同, 现在的Lab设计是按照功能模块进行划分的, 但这导致Lab 5和Lab 6的测代码量和难度远大于之前的Lab, 难度曲线可能不太合理, 后续应考虑对各个Lab进行更加均衡的划分。 - 进一步补充一些背景理论知识, 尤其是实际场景中的各种性能优化方案。
Lab 7 WiscKey 键值分离✅ 已完成(见 Lab 7)- Lab 7 VLog GC(垃圾回收)章节待补充。
如果你有兴趣参与本实验的建设,欢迎在下面的分支上提交PR: