本文将介绍lab3A部分的实现, lab3A要求基于raft实现一个容错的分布式KV数据库, 但不要求实现快照, 难度还是不小
Lab文档见: http://nil.csail.mit.edu/6.5840/2023/labs/lab-kvraft.html
我的代码: https://github.com/Vanilla-Beauty/MIT6.5840/tree/lab3A
1 lab2:Raft bug 修复
首先又是万恶的老旧代码bug修复
1.1 心跳发送逻辑修复
1.1.1 bug描述
在lab3A中, kv数据库的命令要求命令能够尽快被commit, 且要求比一个心跳间隔更快, 但我在lab2的实现中, 无论是否调用了Start, 都不影响心跳的发送频率, 因此自然commit速度很慢, 过不了测试。因此需要修改lab2中Start, 使其立即唤醒一次心跳
1.1.2 修改方案
由于需要在发送心跳的携程函数SendHeartBeats外控制心跳发送, 因此可以简单地修改SendHeartBeats通过事件触发心跳发送, 而不是发送后简单地Sleep,
- 首先设置一个心跳定时器
1
2
3
4
5type Raft struct {
...
heartTimer *time.Timer
...
} SendHeartBeats通过事件触发心跳发送1
2
3
4
5
6
7
8
9
10
11func (rf *Raft) SendHeartBeats() {
for !rf.killed() {
<-rf.heartTimer.C
...
rf.ResetHeartTimer(HeartBeatTimeOut)
}
}
func (rf *Raft) ResetHeartTimer(timeStamp int) {
rf.heartTimer.Reset(time.Duration(timeStamp) * time.Millisecond)
}Start函数理解触发心跳其余重设定时器的地方就不在赘述了1
2
3
4
5
6
7
8func (rf *Raft) Start(command interface{}) (int, int, bool) {
...
defer func() {
rf.ResetHeartTimer(1)
}()
return rf.VirtualLogIdx(len(rf.log) - 1), rf.currentTerm, true
}
1.2 投票逻辑修复
1.2.1 bug描述
简单说就是某节点2轮选举撞在了一起, 首先先回顾选举相关的结构体成员:
1 | type Raft struct { |
这个bug原来本来是没有的, 因为之前Start并不会立即发送心跳,所以不容易出现如RPC重复, RPC乱序等问题, 但修改了Start后, 并发场景更复杂, 因此出现了如下的场景:
- 某一时刻
Follower 2进行选举 Follower 2选举还没结束时, 又收到了新的Leader的心跳, 证明选举结束了, 但由于选举的某个携程的RPC响应很慢, 其还没有进行选举是否结束(自身变为了Follower)的判断- 选举超时又被触发,
Follower 2进行新一轮选举, 由于票数是以结构体成员voteCount保存的, 因此voteCount可能与之前的选票发生冲突
1.2.2 修改方案
既然结构体成员会发生冲突, 那不如为每轮选票临时创建一个成员和投票锁:
1 | func (rf *Raft) Elect() { |
collectVote函数就不展示了, 将原来的结构体成员muVote和voteCount换为临时创建的变量即可
2 KV数据库架构
首先先贴出官方提供的架构图:
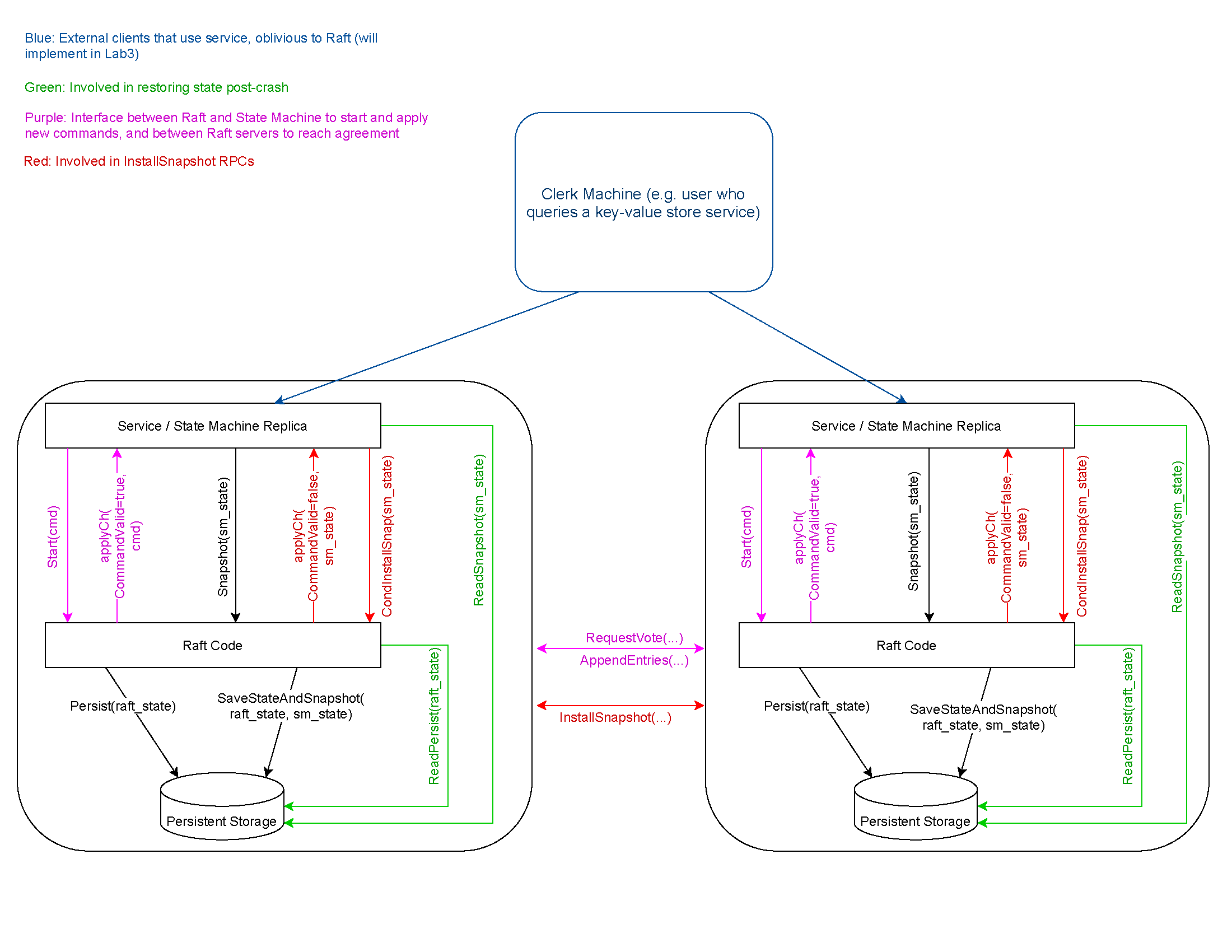
简单说, 我们要建立的KV数据库是位于raft层之上的, 或者说我们的KV数据库使用了raft库。客户端(就是代码中的clerk)调用应用层(server)的RPC,应用层收到RPC之后,会调用Start函数,Start函数会立即返回,但是这时,应用层不会返回消息给客户端,因为它还没有执行客户端请求,它也不知道这个请求是否会被Raft层commit。只有在某一时刻,对应于这个客户端请求的消息在applyCh channel中出现, 应用层才会执行这个请求,并返回响应给客户端。
对于上述过程, 可参考我在课堂笔记中画的图:
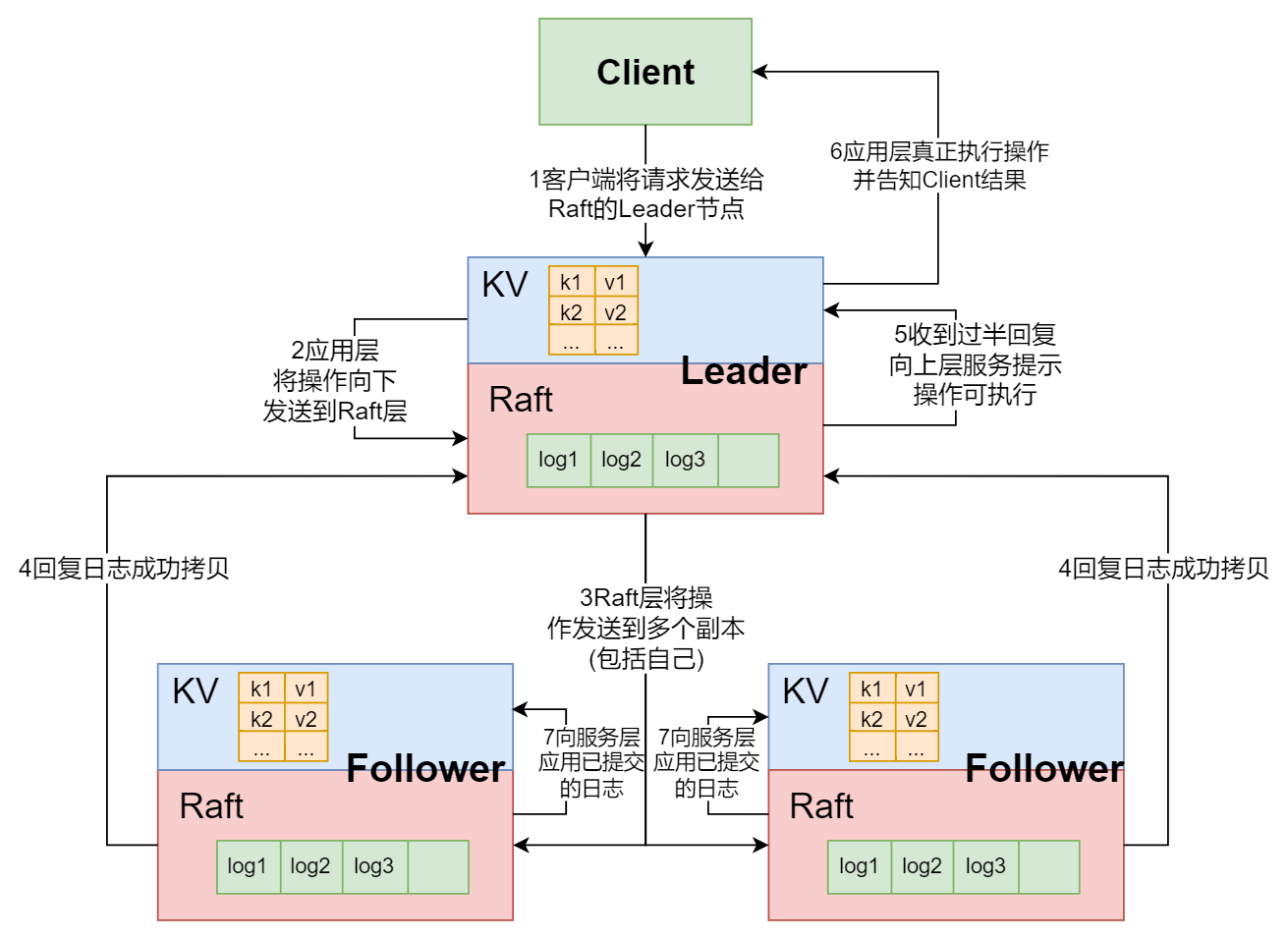
3 设计思路
3.1 为什么会线性不一致?
clerk和真正的客户端交互并管理RPC, 而server收到请求后需要将请求传递给raft层进行集群复制, 然后收到raft的commit, 在应用到状态机并返回给客户端。
但问题在于需要确保以上操作的线性一致性, 那什么时候会出现线形不一致的情况呢?就是重复的请求。因为网络问题,clerk可能认为之前的请求丢包了, 所以会再次发送请求。而raft层是无法判断这个请求是否重复的, 如果server层没有特殊处理, 有的请可能在客户端看来只执行了一次, 但在server执行了多次, 并且如果这是Put等改变状态机的请求, 执行了多次将导致逻辑错误。
3.2 实现线性一致性的思路
3.2.1 如何判断重复请求?
首先,server需要判断某一个请求是否重复,最简单的方法就是让clerk携带一个全局递增的序列号,并且server需要在第一次将这个请求应用到状态机时记录这个序列号, 用以判断后续的请求是否重复。由于clerk不是并发的, 所以server只需要记录某个clerk序列号最高的一个请求即可, 序列号更低的请求不会出现, 只需要考虑请求重复的场景。
3.2.2 如何处理重复请求?
除了记录某个clerk请求的序列号外, 还需要记录器执行结果,因为如果是一个重复的Get请求, 其返回的结果应该与其第一次发送请求时一致, 否则将导致线性不一致。如果是重复的Put等改变状态机的请求,就不应该被执行
总结下来, 思路就是:
- 重复的
Put/Append请求只在第一次出现时应用到状态机 - 记录每次应用到状态机的请求结果和序列号
4 具体实现
4.1 client实现
4.1.1 结构体设计
先贴代码:
1 | type Clerk struct { |
identifier用于标识clerk, seq是单调递增的序列号, 标记请求, identifier和seq一起标记了唯一的请求, leaderId记录领导者
4.1.2 client RPC设计
4.1.2.1 RPC结构体设计
RPC请求只需要额外携带identifier和seq, RPC回复则需要携带结果和错误信息:
1 | type PutAppendArgs struct { |
4.1.2.2 Put/Append
这2个函数很简单 ,不断轮询server即可, 但是需要注意, 如果对方返回了超时错误和通道关闭错误等意料之外的错误, 需要重试
1 | func (ck *Clerk) Get(key string) string { |
重试
RPC时, 需要新建reply结构体, 重复使用同一个结构体将导致labgob报错
4.2 Server实现
4.2.1 Server设计思路
根据前文分析可知, RPC handler(就是Get/Put handler)只会在raft层的commit信息到达后才能回复, 因此其逻辑顺序就是
- 将请求封装后通过接口
Start交付给raft层- 如果
raft层节点不是Leader, 返回相应错误 - 否则继续
- 如果
- 等待
commit信息- 信息到达, 根据
commit信息处理回复(具体是什么样的信息回复后面会说) - 超时, 返回相应错误
- 信息到达, 根据
分析到这里可知, 必然有一个协程在不断地接收raft层的commit日志(此后称为ApplyHandler协程), 那上述提到的重复RPC判别和处理是在ApplyHandler中进行, 还是在RPC handler中进行呢?
我的处理方式是在ApplyHandler中进行, 因为ApplyHandler是绝对串行的, 在其中处理这些日志是最安全的, 否则通过通道发送给RPC handler货条件变量唤醒RPC handler, 都存在一些并发同步的问题, 因此, ApplyHandler需要进行重复RPC判别和处理(可能需要存储), 并将这个请求(commit log就对应一个请求)的结果返回给RPC handler
4.2.2 结构体设计
因此, 通过上述分析, server结构体如下:
1 | type KVServer struct { |
其中:
historyMap记录某clerk的最高序列号的请求的序列号和结果resultresult结构体存储一个请求的序列号和结果, 以及ResTerm记录commit被apply时的term, 因为其可能与Start相比发生了变化, 需要将这一信息返回给客户端waiCh纪录等待commit信息的RPC handler的通道
4.2.3 RPC handler设计
RPC handler设计较为简单,只需要调用Start, 等待commit信息即可, 不过还需要考虑超时的错误处理
1 | func (kv *KVServer) Get(args *GetArgs, reply *GetReply) { |
Get和PutAppend都将请求封装成Op结构体, 统一给HandleOp处理, HandleOp处理ApplyHandler发过来的commit信息并生成回复, 这里我采用的通信方式是管道, 每一个请求会将自己创建的管道存储在waiCh中, 并在函数离开时清理管道和waiCh:
1 | func (kv *KVServer) HandleOp(opArgs *Op) (res result) { |
这里需要额外注意错误处理:
- 超时错误
- 通道关闭错误
Leader可能过期的错误(term不匹配)- 不是
Leader的错误
同时这里还有一个难点, 就是如果出现了重复的RPC, 他们都在等待commit信息, 那么他们的管道存储在waiCh中的key是什么呢? 如果使用Identifier或Seq, 那么必然后来的RPC会覆盖之前的管道, 可能造成错误, 因为两个重复RPC的Identifier或Seq是一样的。 这里可以巧妙地利用Start函数的第一个返回值, 其代表如果commit成功, 其日志项的索引号, 由于raft层不区分重复RPC的log, 因此这个索引号肯定是不同的, 不会相互覆盖
4.2.4 ApplyHandler设计
ApplyHandler是3A的最核心的部分, 其思路是:
- 先判断
log请求的Identifier和Seq是否在历史记录historyMap中是否存在, 如果存在就直接返回历史记录 - 不存在就需要应用到状态机, 并更新历史记录
historyMap - 如果
log请求的CommandIndex对应的key在waiCh中存在, 表面当前节点可能是一个Leader, 需要将结果发送给RPC handler1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66func (kv *KVServer) ApplyHandler() {
for !kv.killed() {
log := <-kv.applyCh
if log.CommandValid {
op := log.Command.(Op)
kv.mu.Lock()
// 需要判断这个log是否需要被再次应用
var res result
needApply := false
if hisMap, exist := kv.historyMap[op.Identifier]; exist {
if hisMap.LastSeq == op.Seq {
// 历史记录存在且Seq相同, 直接套用历史记录
res = *hisMap
} else if hisMap.LastSeq < op.Seq {
// 否则新建
needApply = true
}
} else {
// 历史记录不存在
needApply = true
}
_, isLeader := kv.rf.GetState()
if needApply {
// 执行log
res = kv.DBExecute(&op, isLeader)
res.ResTerm = log.SnapshotTerm
// 更新历史记录
kv.historyMap[op.Identifier] = &res
}
if !isLeader {
// 不是leader则继续检查下一个log
kv.mu.Unlock()
continue
}
// Leader还需要额外通知handler处理clerk回复
ch, exist := kv.waiCh[log.CommandIndex]
if !exist {
// 接收端的通道已经被删除了并且当前节点是 leader, 说明这是重复的请求, 但这种情况不应该出现, 所以panic
DPrintf("leader %v ApplyHandler 发现 identifier %v Seq %v 的管道不存在, 应该是超时被关闭了", kv.me, op.Identifier, op.Seq)
kv.mu.Unlock()
continue
}
kv.mu.Unlock()
// 发送消息
func() {
defer func() {
if recover() != nil {
// 如果这里有 panic,是因为通道关闭
DPrintf("leader %v ApplyHandler 发现 identifier %v Seq %v 的管道不存在, 应该是超时被关闭了", kv.me, op.Identifier, op.Seq)
}
}()
res.ResTerm = log.SnapshotTerm
*ch <- res
}()
}
}
}
这里有几大易错点:
- 需要额外传递
Term以供RPC handler判断与调用Start时相比,term是否变化, 如果变化, 可能是Leader过期, 需要告知clerk - 发送消息到通道时, 需要解锁
- 因为发送消息到通道时解锁, 所以通道可能被关闭, 因此需要单独在一个函数中使用
recover处理发送消息到不存在的通道时的错误 - 这个
ApplyHandler是leader和follower都存在的协程, 只不过follower到应用到状态机和判重那里就结束了,leader多出来告知RPC handler结果的部分
DBExecute就是将日志项应用到状态机, 逻辑很简单:
1 | func (kv *KVServer) DBExecute(op *Op, isLeader bool) (res result) { |
5 测试
执行测试命令
1 | go test -v -run 3A |
结果如下: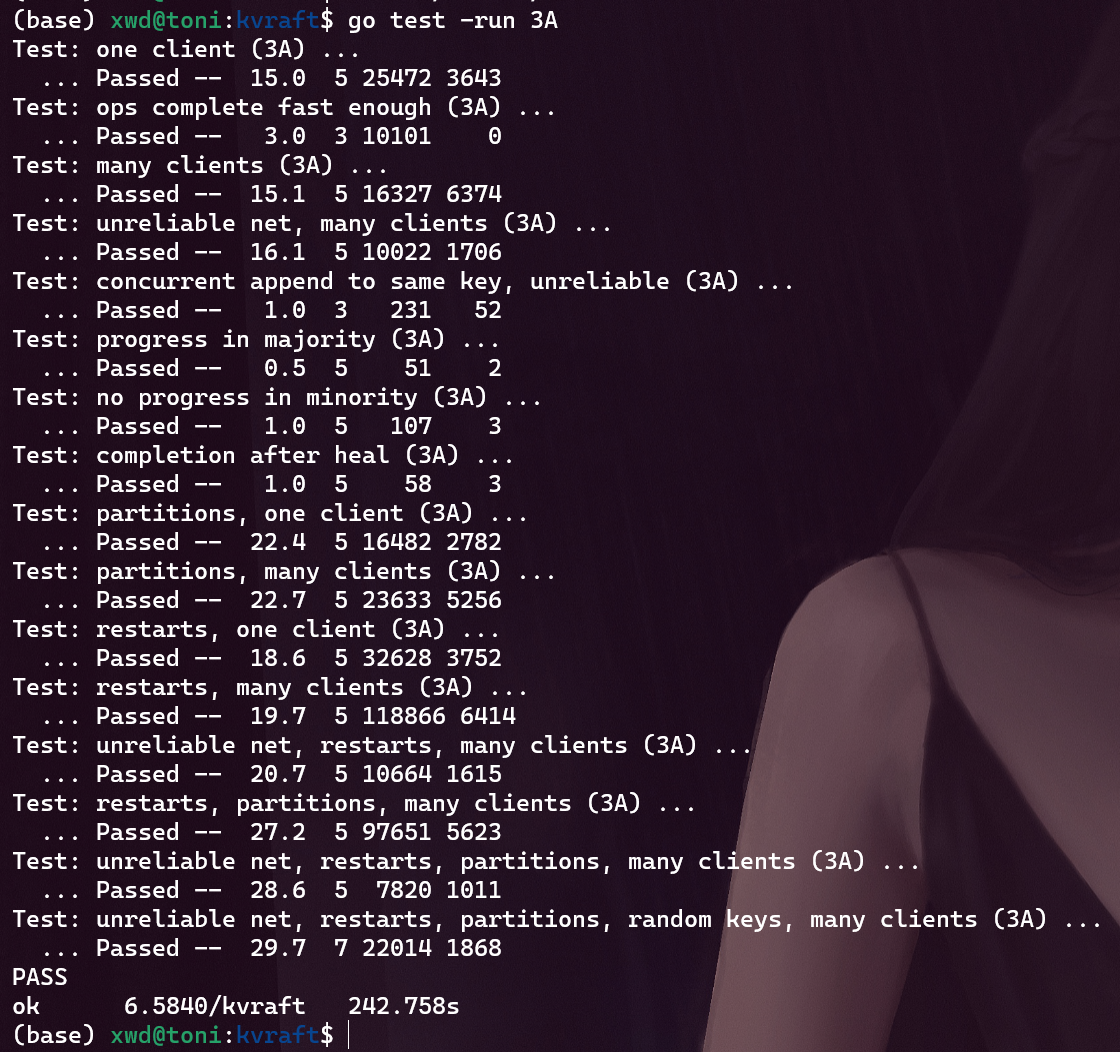
该代码经过150次测试没有报错