Lab2的内容是实现Raft算法, Raft算法是一种分布式系统中的一致性的共识算法, 于2014年提出。本次实现的Raft是下一个K/V实验的基础, 因此十分重要。就个人体验而言,本次实验的难度比之前的MapReduce复杂不少, 因此强烈建议先大致浏览一遍Raft的原论文
由于这个Lab难度较大, 内容较多, 我将按照文档的任务分块进行, 这一部分先介绍第一个任务: 2A: leader election
Lab文档见: https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
我的代码: https://github.com/Vanilla-Beauty/MIT6.5840/tree/lab2A
1 任务描述
首先贴一张原论文的图, 这张图描述了每个RPC的逻辑, 非常重要:

2A部分要求完成的是Raft中的Leader选取和心跳函数, 通过阅读论文和文档, 我们知道Raft的运行状况是这样的:
- 正常运行
Leader不断发送心跳函数给Follower,Follower回复, 这个心跳是通过AppendEntries RPC实现的, 只不过其中entries[]是空的。 - 选举
- 当指定的心跳间隔到期时,
Follower转化为Candidate并开始进行投票选举, 会为自己投票并自增term - 每一个收到投票请求的
Server(即包括了Follower,Candidate或旧的Leader), 判断其RPC的参数是否符合Figure2中的要求, 符合则投票 - 除非遇到了轮次更靠后的投票申请, 否则投过票的
Server不会再进行投票 - 超过一半的
Server的投票将选举出新的Leader, 新的Leader通过心跳AppendEntries RPC宣告自己的存在, 收到心跳的Server更新自己的状态 - 若超时时间内无新的
Leader产生, 再进行下一轮投票, 为了避免这种情况, 应当给不同Server的投票超时设定随机值
- 当指定的心跳间隔到期时,
2 代码逻辑
通过分析可知, 需要实现的功能包括:
- 一个协程不断检测一个投票间隔内是接收到心跳或
AppendEntries RPC(其实是一个东西), 如果没有接受到, 则发起投票 - 处理投票的协程, 发起投票并收集投票结果以改变自身角色
- 不断发送心跳的
Leader的心跳发射器协程 - 处理投票请求的
RPC - 处理心跳的
RPC
官方提供的代码里指明用ticker实现选举, 并给出了RPC的实现案例
3 结构体设计
第一步就是先将Figure 2.5的字段填入各个结构体。
3.1 Raft结构体
1 | const ( |
除了Figure 2中的字段外, 还有 role, timeStamp, muVote, voteCount四个自定义字段:
role: 一个枚举量, 记录当前实例的角色, 取值包括:Follower,Candidate,LeadervoteCount: 得票计数muVote: 用于保护voteCount的锁, 因为投票时只需要更改voteCount, 而全部使用mu明细会增加锁的竞争, 这里是细化锁的粒度timeStamp: 记录最后一次收到合法消息的时间戳, 每次判断是否要选举时, 通过判断与这个时间戳的差值来决定是否达到超时
为什么不使用定时器time.Timer?
主要原因是官方的Hint中明确表示:
Don’t use Go’s time.Timer or time.Ticker, which are difficult to use correctly.
个人实际使用后确实出现了很多不明所以的bug, 因此就选择记录时间戳timeStamp + Sleep的方式实现
3.2 RPC结构体
RPC结构体直接照搬Figure 2:
RequestVote RPC1
2
3
4
5
6
7
8
9
10
11
12
13
14
15type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int // candidate’s term
CandidateId int // candidate requesting vote
LastLogIndex int // index of candidate’s last log entry (§5.4)
LastLogTerm int // term of candidate’s last log entry (§5.4)
}
// example RequestVote RPC reply structure.
// field names must start with capital letters!
type RequestVoteReply struct {
// Your data here (2A).
Term int // currentTerm, for candidate to update itself
VoteGranted bool // true means candidate received vote
}AppendEntries RPC1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17type AppendEntriesArgs struct {
// Your data here (2A, 2B).
Term int // leader’s term
LeaderId int // so follower can redirect clients
PrevLogIndex int // index of log entry immediately preceding new ones
PrevLogTerm int // term of prevLogIndex entry
Entries []Entry // log entries to store (empty for heartbeat; may send more than one for efficiency)
LeaderCommit int // leader’s commitIndex
}
// example RequestVote RPC reply structure.
// field names must start with capital letters!
type AppendEntriesReply struct {
// Your data here (2A).
Term int // currentTerm, for leader to update itself
Success bool // true if follower contained entry matching prevLogIndex and prevLogTerm
}
4 投票设计
4.1 投票发起方
ticker函数判断是否需要投票:这里1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19func (rf *Raft) ticker() {
rd := rand.New(rand.NewSource(int64(rf.me)))
for !rf.killed() {
// Your code here (2A)
// Check if a leader election should be started.
// pause for a random amount of time between 50 and 350
// milliseconds.
rdTimeOut := GetRandomElectTimeOut(rd)
rf.mu.Lock()
if rf.role != Leader && time.Since(rf.timeStamp) > time.Duration(rdTimeOut)*time.Millisecond {
// 超时
go rf.Elect()
}
rf.mu.Unlock()
time.Sleep(ElectTimeOutCheckInterval)
}
}timeStamp就是上一次正常收到消息的时间, 判断当前的时间差再与随机获取的超时时间比较即可
另外, 根据官方的提示可知:
You may find Go’s rand useful.
确定超时间隔时, 需要为不同的server设置不同的种子, 否则他们大概率会同时开启选票申请, 这里我直接使用其序号rf.me作为随机种子。
Elect函数负责处理具体的投票任务:这个函数的任务很简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24func (rf *Raft) Elect() {
rf.mu.Lock()
rf.currentTerm += 1 // 自增term
rf.role = Candidate // 成为候选人
rf.votedFor = rf.me // 给自己投票
rf.voteCount = 1 // 自己有一票
rf.timeStamp = time.Now() // 自己给自己投票也算一种消息
args := &RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: len(rf.log) - 1,
LastLogTerm: rf.log[len(rf.log)-1].Term,
}
rf.mu.Unlock()
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
go rf.collectVote(i, args)
}
}
- 更新
term - 标记自身角色转换
- 为自己投票
- 初始化票数为1
- 更新时间戳
其余的部分很简单, 就是构造RPC的请求结构体, 异步地对每个server发起投票申请
易错点:
忘记更新时间戳, 因为自己给自己投票也算一种消息, 应当更新时间戳, 否则下一轮投票很快又来了
collectVote函数处理每个server的回复并统计票数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53func (rf *Raft) collectVote(serverTo int, args *RequestVoteArgs) {
voteAnswer := rf.GetVoteAnswer(serverTo, args)
if !voteAnswer {
return
}
rf.muVote.Lock()
if rf.voteCount > len(rf.peers)/2 {
rf.muVote.Unlock()
return
}
rf.voteCount += 1
if rf.voteCount > len(rf.peers)/2 {
rf.mu.Lock()
if rf.role == Follower {
// 有另外一个投票的协程收到了更新的term而更改了自身状态为Follower
rf.mu.Unlock()
rf.muVote.Unlock()
return
}
rf.role = Leader
rf.mu.Unlock()
go rf.SendHeartBeats()
}
rf.muVote.Unlock()
}
func (rf *Raft) GetVoteAnswer(server int, args *RequestVoteArgs) bool {
sendArgs := *args
reply := RequestVoteReply{}
ok := rf.sendRequestVote(server, &sendArgs, &reply)
if !ok {
return false
}
rf.mu.Lock()
defer rf.mu.Unlock()
if sendArgs.Term != rf.currentTerm {
// 易错点: 函数调用的间隙被修改了
return false
}
if reply.Term > rf.currentTerm {
// 已经是过时的term了
rf.currentTerm = reply.Term
rf.votedFor = -1
rf.role = Follower
}
return reply.VoteGranted
}collectVote调用GetVoteAnswer, 其中GetVoteAnswer负责处理具体某一个server的回复:- 如果
RPC调用失败, 直接返回 - 如果
server回复了更大的term, 表示当前这一轮的投票已经废弃, 按照回复更新term、自身角色和投票数据 返回false - 然后才是返回
server是否赞成了投票
collectVote处理逻辑为:
- 如果发现当前投票已经结束了(即票数过半), 返回
- 否则按照投票结果对自身票数自增
- 自增后如果票数过半, 检查检查状态后转换自身角色为
Leader - 转换自身角色为
Leader, 开始发送心跳
这里特别说明为什么收集投票时需要muVote这个锁保护voteCount, 因为除了最后一个超过半票的一个协程, 其余协程只需要访问voteCount, 因此额外设计了muVote这个锁保护它。
易错点:
- 由于不同函数调用的间隙, 状态可能被别的协程改变了, 因此
GetVoteAnswer中如果发现sendArgs.Term != rf.currentTerm, 表示已经有Leader诞生了并通过心跳改变了自己的Term, 所以放弃投票数据收集collectVote中也存在类似的问题, 因为collectVote也是与RPC心跳的handler并发的, 可能新的Leader已经产生, 并通过心跳改变了自己的role为Follower, 如果不检查的话, 将导致多个Leader的存在- 尽管向多个
server发送的RequestVoteArgs内容是相同的, 但我们不同使用同一个指针, 而是应该复制一个结构体 否则会报错, 原因暂时没看源码, 未知(先鸽了)
4.2 投票接收方
投票的接收方则严格按照Figure 2设计, 代码:
1 | // example RequestVote RPC handler. |
代码的逻辑是(对Figure 2 做了一定自己理解的展开):
- 如果
args.Term < rf.currentTerm, 直接拒绝投票, 并告知更新的投票 - 如果
args.Term > rf.currentTerm, 更新rf.votedFor = -1, 表示自己没有投票, 之前轮次的投票作废 - 如果满足下面两个情况之一, 投票, 然后更新
currentTerm,votedFor,role,timeStampargs.Term > rf.currentTermterm == currentTerm且LastLogTerm和LastLogIndex位置的条目存在且term合法, 并且未投票或者投票对象是自己
- 其他情况不投票
易错点
args.Term > rf.currentTerm的情况需要设置rf.votedFor = -1, 因为当前的server可能在正处于旧的term的选举中,并投给了别人, 应当废除旧term的投票, 将其置为未投票的状态, 否则将错失应有的投票
5 心跳设计(AppendEntries RPC)
5.1 心跳发射器
当一个Leader诞生时, 立即启动心跳发射器, 其不断地调用AppendEntries RPC, 只是Entries是空的而已, 其代码相对简单:
1 | func (rf *Raft) SendHeartBeats() { |
易错点:
同前文描述, 尽管向多个server发送的AppendEntriesArgs内容是相同的, 但我们不能使用同一个指针, 而是应该复制一个结构体 否则会报错
1 | func (rf *Raft) handleHeartBeat(serverTo int, args *AppendEntriesArgs) { |
handleHeartBeat负责处理每一个发出的心跳函数的回复, 只需要考虑的就是自身的term被更新了, 需要更改自身状态, 其逻辑和前文相同, 不赘述
易错点
这里也存在函数调用间隙字段被修改的情况, 也需要检查sendArgs.Term != rf.currentTerm的情况
5.2 心跳接受方
心跳接受方实际上就是AppendEntries RPC的handler, 由于目前日志部分的字段还没有设计, 因此这里的代码不涉及持久化:
1 | func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) { |
AppendEntries严格按照Figure 2实现:
- 如果
term < currentTerm表示这是一个旧leader的消息, 告知其更新的term并返回false - 如果自己的日志中
prevLogIndex处不存在有效的日志, 或者与prevLogTerm不匹配, 返回false - 如果现存的日志与请求的信息冲突, 删除冲突的日志(这一部分不涉及)
- 添加日志(这一部分不涉及)
- 如果
leaderCommit > commitIndex, 确认者较小值并更新
同时, 收到AppendEntries需要更新对应的时间戳rf.timeStamp
易错点
- 如果
args.Term > rf.currentTerm, 表示这是新的Leader发送的消息, 由于自身可能正在进行选举投票, 因此需要更改rf.role = Followe && rf.votedFor = -1以终止其不应该继续的投票, 同时更新rf.votedFor = -1,-1表示未投过票。
6 测试
6.1 常规测试
执行测试命令
1 | go test -v -run 2A |
结果如下:
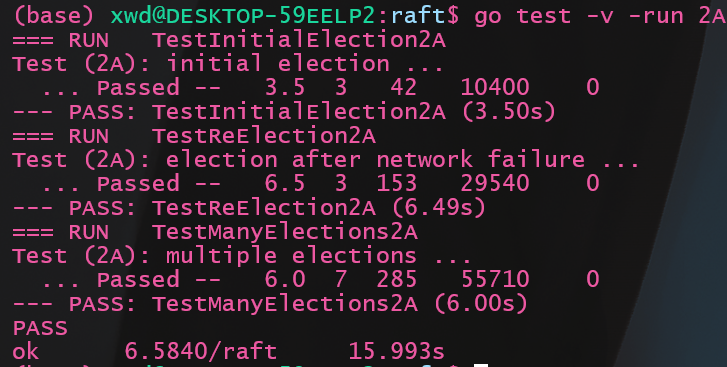
6.2 多次测试
raft的许多特性导致其一次测试并不准确, 有些bug需要多次测试才会出现, 编写如下脚本命名为manyTest_2A.sh:
1 | !/bin/bash |
再次进行测试:
1 | ./manyTest_2A.sh |
结果:
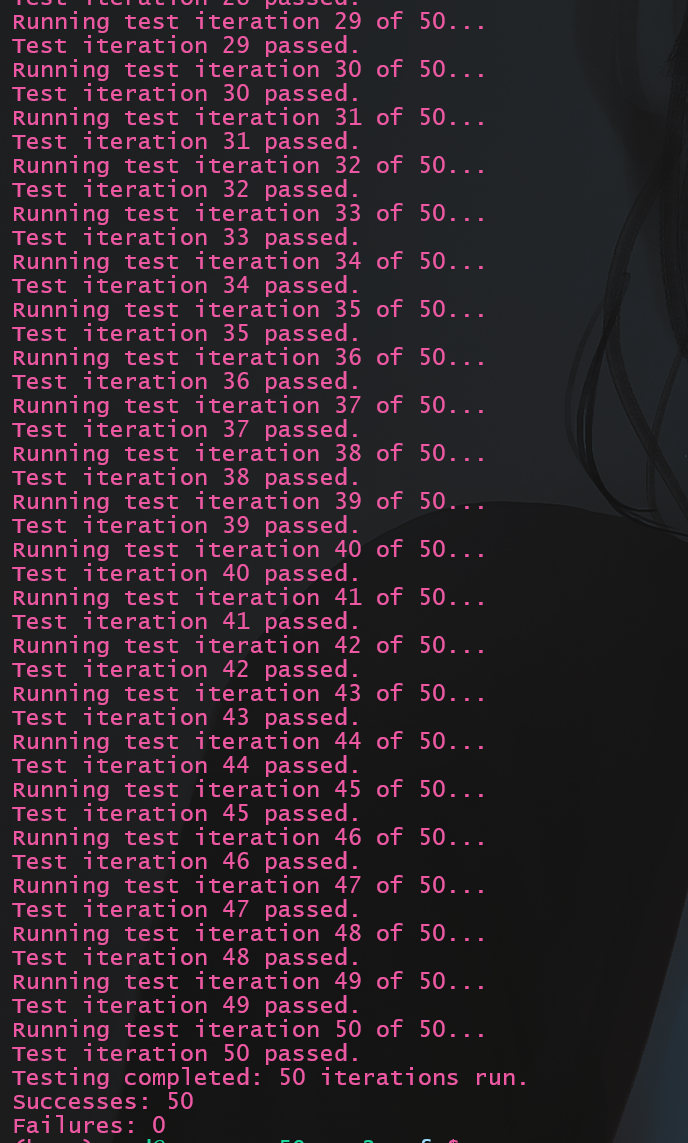
更新
代码在leader选举过程中存在bug, 但任然能通过测例, 修复后的代码和bug分析见 下一篇文章: Lab2_Raft_2B.md